Jetson Thor 权威指南:从开箱到大模型部署与性能优化
该文章是对 NVIDIA Jetson Thor 平台进行大语言模型部署、系统优化和深度性能基准测试的权威指南。
平台配置与环境准备: 文章首先详细介绍了在 Jetson AGX Thor 开发套件上进行 BSP(Jetson Linux)安装流程。这包括下载 ISO 映像、使用 Balena Etcher 创建可启动 USB 棒,以及通过首次启动完成 UEFI 固件更新和 Ubuntu 初始设置。软件环境基于 JetPack 7,它提供了对前沿机器人和生成式 AI 的全面支持。部署环境采用云原生技术,通过 Docker 容器运行 vLLM 或 TritonServer 等推理服务。
系统性能调优:
为了释放硬件全部潜力,文章强调了系统级的性能调优步骤:必须通过 sudo nvpmodel -m 0 将功耗模式设置为最高性能模式 (MAXN)(130W),并使用 sudo jetson_clocks 锁定 CPU、GPU 和内存的核心频率,禁用 DVFS 机制。测试结果显示,MAXN + jetson_clocks 组合能显著提升性能,在高负载下,FP8 模型的吞吐量提升约 18.5%,在低负载下,每 Token 平均延迟(TPOT)减少约 43%。
量化模型基准测试结果: 文章对 Qwen3-8B 模型的多种量化精度(包括 BF16、FP8、FP4、Int4 等)进行了详尽的性能分析。核心发现是:
- FP8 量化精度(8.9G 模型)表现出绝对优势。在高并发(高负载)场景下,FP8 模型实现了最高的输出 Token 吞吐量(298.07 tok/s),是基线 BF16 模型(82.47 tok/s)的 3.6 倍。
- 在低延迟(低负载)场景下,FP8 实现了最低的首 Token 延迟(23.06 ms)和最低的平均生成延迟(8.88 ms)。
NVIDIA Jetson Thor
为物理 AI 和人形机器人打造的卓越平台

- NVIDIA Jetson Thor 为通用机器人和物理 AI 解锁实时推理能力
- NVIDIA Jetson Thor 为物理 AI 和人形机器人打造的卓越平台
- NVIDIA Jetson AGX Thor Developer Kit
- NVIDIA DRIVE AGX Thor 开发者套件 硬件快速入门指南
BSP 安装
- Jetson AGX Thor Developer Kit - User Guide
- Jetson AGX Thor Developer Kit - User Guide: Quick Start Guide
使用可启动安装 USB 棒在 Jetson AGX Thor 开发套件上快速安装 BSP( Jetson Linux )。
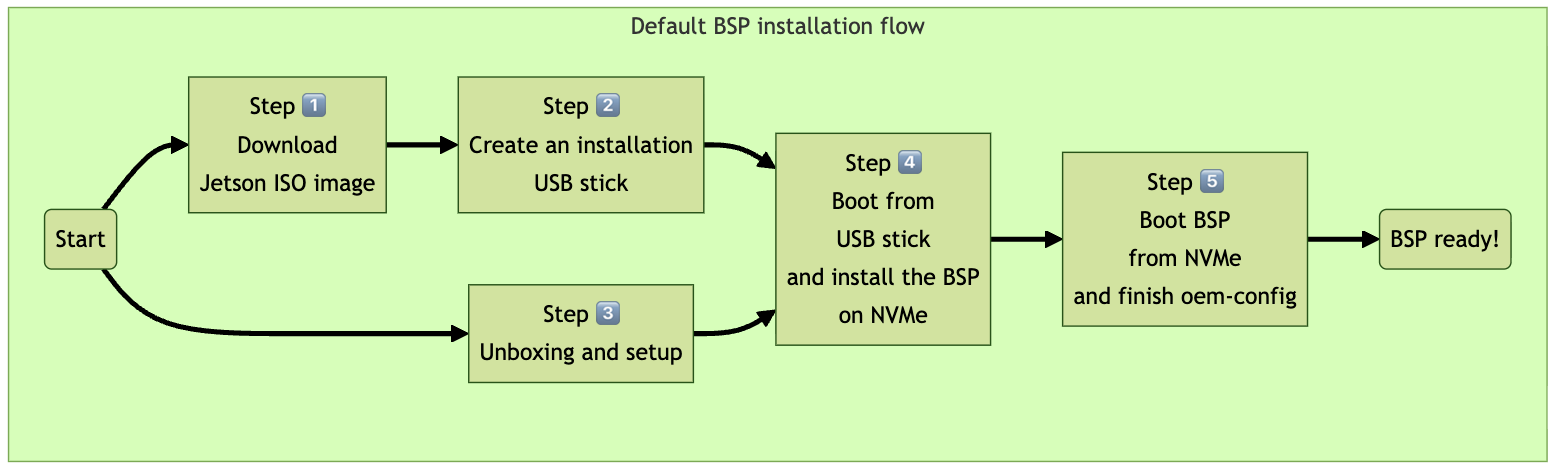
BSP 安装流程
1️⃣ 下载 ISO
首先,您需要从 NVIDIA 网站下载 Jetson BSP 安装映像文件:Jetson ISO (r38.2-08-22)
或者,您可以转到 JetPack 下载页面,找到 Jetson AGX Thor 开发套件的最新 JetPack 版本,然后将 Jetson ISO 映像文件下载到您的笔记本电脑或 PC 上。
2️⃣ 创建安装 USB
要在您的 Jetson AGX Thor 开发套件上安装 Jetson BSP(Jetson Linux),我们首先需要通过将下载的 ISO 映像写入 USB 记忆棒来创建安装媒体。
使用 Balena Etcher 创建可启动的 USB 记忆棒。
3️⃣ 开箱和安装
开箱

启动 Jetson
- 通过 HDMI 或 DisplayPort 连接显示器。
- 连接 USB 键盘和鼠标。
- 将可启动安装 USB 棒连接到 USB Type-A 端口或 Jetson AGX Thor 开发套件的 USB-C 端口。
- 将电源插头连接到两个 USB-C 端口之一。
- 按下电源按钮(11,下图左侧的按钮)启动 Jetson。
![]()
4️⃣ 从 USB 启动并在 NVMe 上安装 BSP
从安装 U 盘启动
Jetson BSP 安装菜单
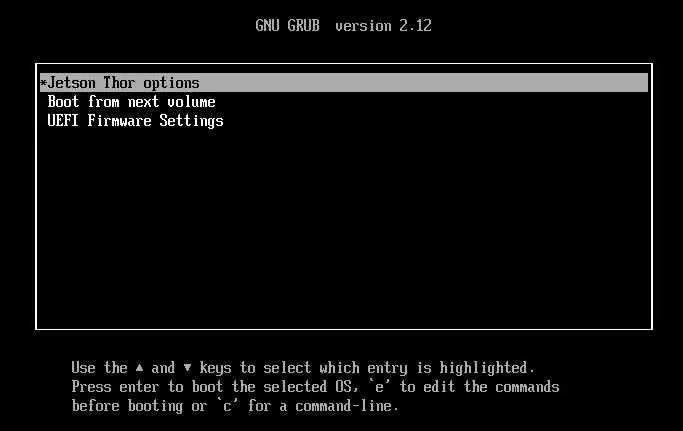
Jetson Thor 选项菜单
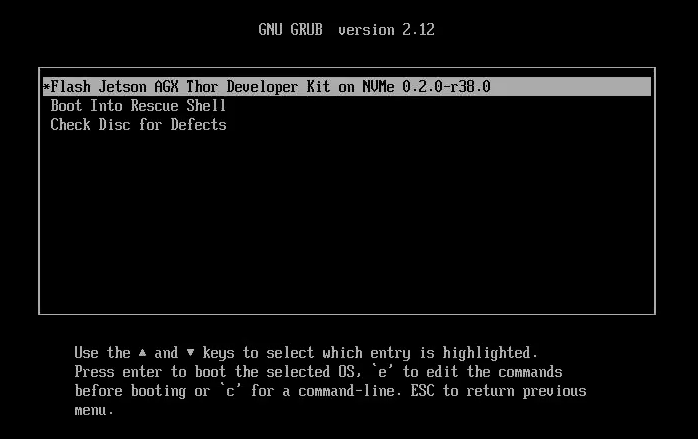
5️⃣ 首次从 NVMe 启动 BSP
UEFI 固件
Jetson 将自动启动 UEFI 固件更新过程。

初始软件设置
现在,您可以启动初始 Ubuntu 设置过程 (oem-config),创建默认用户帐户并设置其他内容。完成后,您就可以开始使用已完全设置好的 Jetson BSP 了。
恭喜!
您现在可以在 Jetson AGX Thor 开发套件上开始开发。
Headless(无头)模式
您可以使用笔记本电脑或 PC 远程访问 Jetson,并且 Jetson 将被用作服务器。

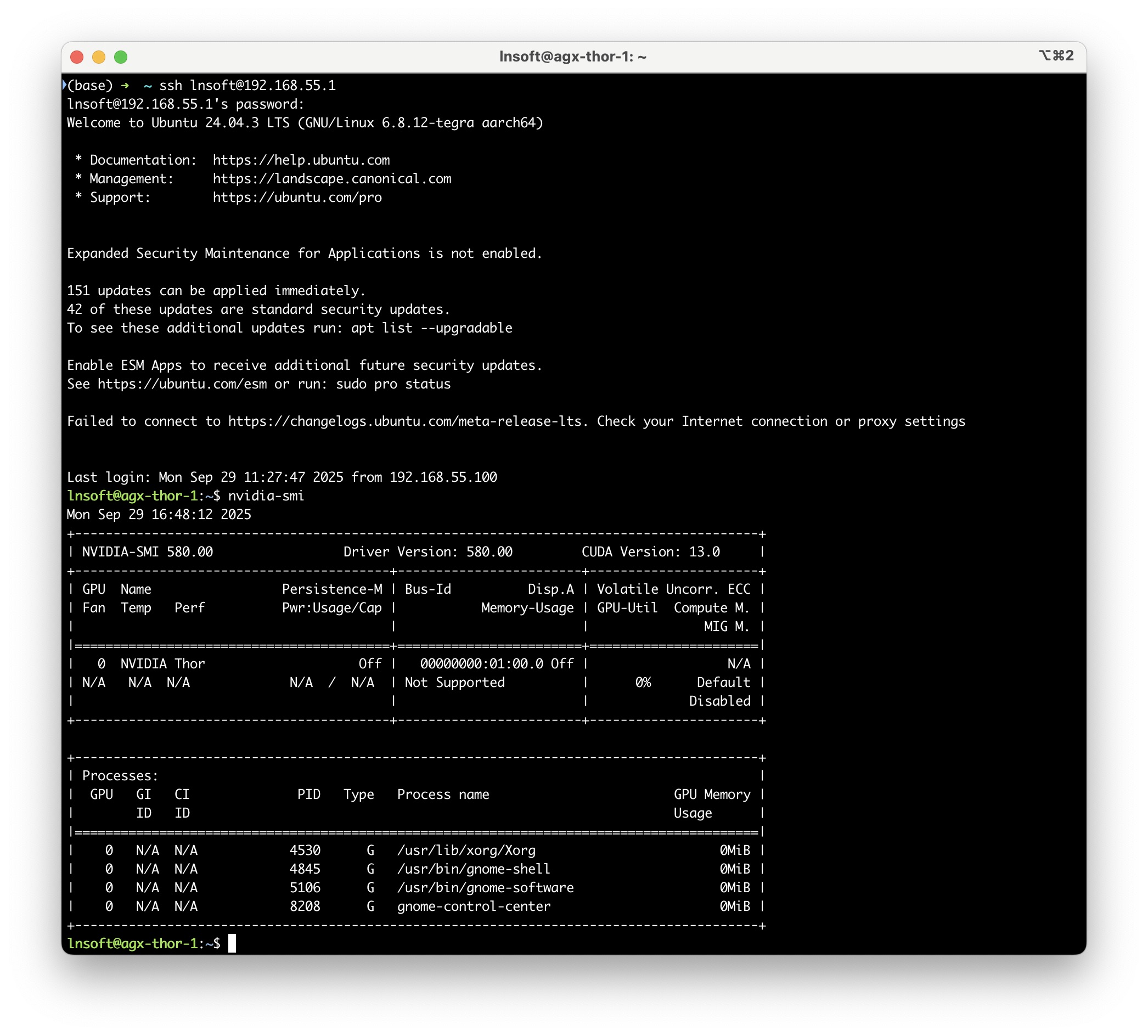
ssh 登录
ssh username@192.168.55.1
ssh 免密登录
复制您的公匙 id_rsa.pub 到 Jetson 设备,命名为 authorized_keys。
scp ~/.ssh/id_rsa.pub lnsoft@192.168.55.1:/home/lnsoft/.ssh/authorized_keys
ssh 登录可以不用输入密码直接登录 Jetson 设备。
ssh lnsoft@192.168.55.1
连接 WiFi
安装网络管理器(Network Manager)
系统默认预装网络管理器(Network Manager)软件。执行以下命令可确认并完成安装:
sudo apt update
sudo apt install network-manager
sudo service NetworkManager start
查看可用 WiFi 列表
sudo nmcli device wifi list
IN-USE BSSID SSID MODE CHAN RATE SIGNAL BARS SECURITY
2C:B2:1A:5D:64:A2 AI_5G Infra 161 540 Mbit/s 100 ▂▄▆█ WPA1 WPA2
DC:D8:7C:56:2C:76 WJJ_HOME Infra 1 270 Mbit/s 65 ▂▄▆_ WPA2
2C:B2:1A:5D:64:A1 AI Infra 11 540 Mbit/s 59 ▂▄▆_ WPA1 WPA2
DC:D8:7C:56:2C:78 WJJ_HOME_Gaming Infra 40 540 Mbit/s 42 ▂▄__ WPA2
DC:D8:7C:56:2C:77 WJJ_HOME_5G Infra 161 270 Mbit/s 37 ▂▄__ WPA2
连接 WiFi
sudo nmcli device wifi connect WJJ_HOME_Gaming password <PASSWORD>
sudo nmcli device wifi connect DC:D8:7C:56:2C:78 password <PASSWORD>
Device 'wlP1p1s0' successfully activated with '6698616f-9239-47e7-a28c-7def80fb60d8'.
查看连接状态
nmcli device wifi
IN-USE BSSID SSID MODE CHAN RATE SIGNAL BARS SECURITY
* DC:D8:7C:56:2C:78 WJJ_HOME_Gaming Infra 40 540 Mbit/s 37 ▂▄__ WPA2
查找无线设备名称
nmcli device status
DEVICE TYPE STATE CONNECTION
wlP1p1s0 wifi connected WJJ_HOME_Gaming
网络连接的切换
- 查看当前激活的网络连接
nmcli connection show --active
NAME UUID TYPE DEVICE
WJJ_HOME_Gaming 6698616f-9239-47e7-a28c-7def80fb60d8 wifi wlP1p1s0
- 关闭当前激活的网络连接
sudo nmcli connection down WJJ_HOME_Gaming
Connection 'WJJ_HOME_Gaming' successfully deactivated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/8)
- 查看当前激活的网络连接
nmcli connection show --active
NAME UUID TYPE DEVICE
AI_5G bb9b3900-6c8a-4556-98b9-79acfca5ef38 wifi wlP1p1s0
- 激活指定网络连接
sudo nmcli connection up AI_5G
Connection successfully activated (D-Bus active path: /org/freedesktop/NetworkManager/ActiveConnection/10)
- 查看当前激活的网络连接
nmcli connection show --active
NAME UUID TYPE DEVICE
AI_5G bb9b3900-6c8a-4556-98b9-79acfca5ef38 wifi wlP1p1s0
安装其它软件
安装 JetPack
sudo apt update
sudo apt install -y nvidia-jetpack
安装 Jetson Stats
jetson-stats 是一款专为 NVIDIA Jetson 系列设备设计的强大系统监控和控制的软件包。
- 安装
sudo pip3 install jetson-stats --break-system-packages
- 重启 jtop 服务
sudo systemctl restart jtop.service
- 运行 jtop
jtop
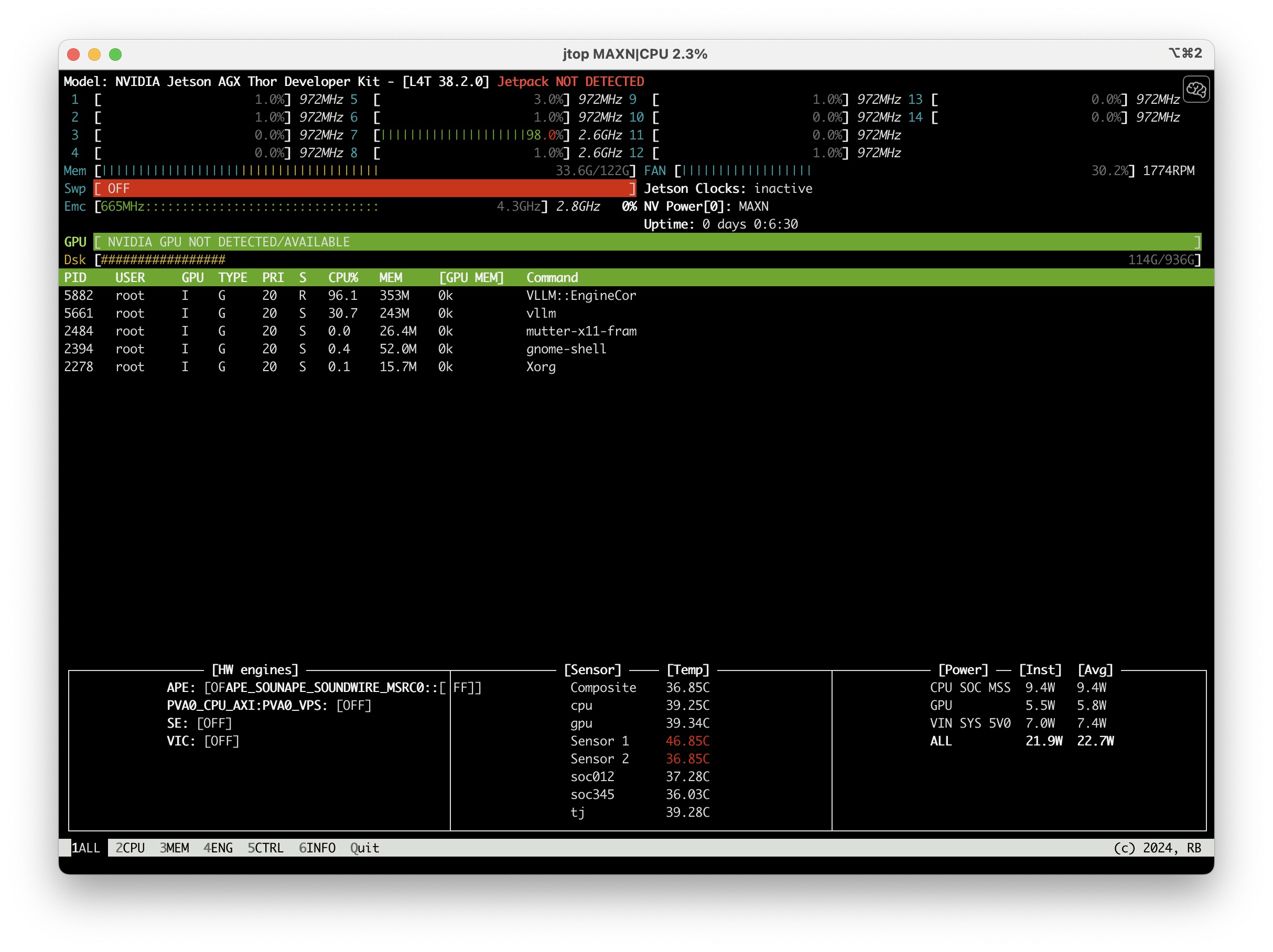
使用 jtop 可以取代手动运行命令
sync && echo 3 > /proc/sys/vm/drop_caches来清除缓存和sudo jetson_clocks来调整时钟频率,非常方便。
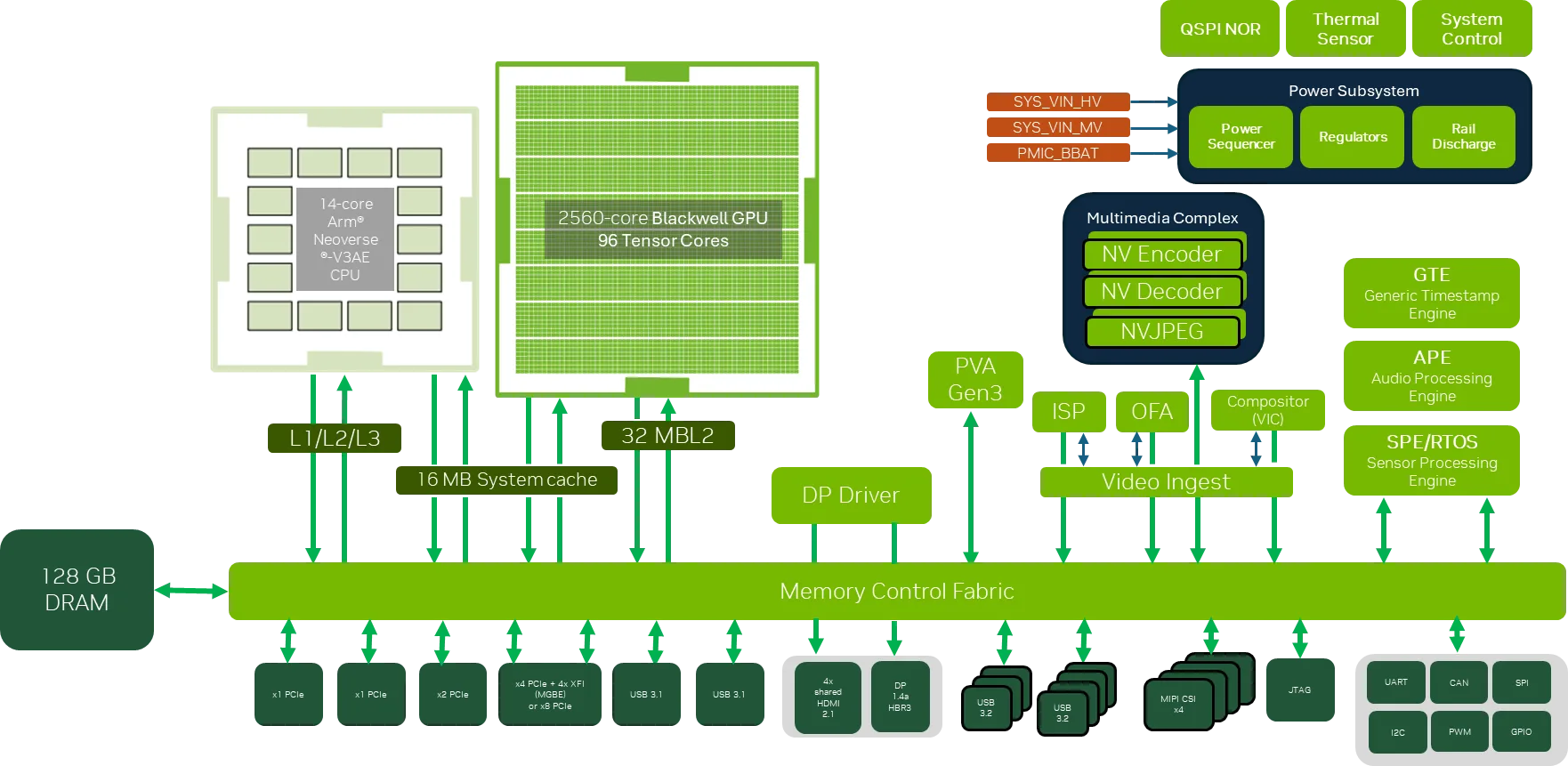
Jetson Thor 模组的组件构成
NVIDIA Jetson AGX Thor 开发者套件模组规格
| NVIDIA Jetson T5000 | NVIDIA Jetson T4000* | |||||||
|---|---|---|---|---|---|---|---|---|
| AI 性能 | 2070 TFLOPS (稀疏 FP4) 1035 TFLOPS (稠密 FP4 | 稀疏 FP8 | 稀疏 INT8) 517 TFLOPs (稠密 FP8 | 稀疏 FP16) | 1200 TFLOPS (稀疏 FP4) 600 TFLOPS (稠密 FP4 | 稀疏 FP8 | 稀疏 INT8) 300 TFLOPs (稠密 FP8 | 稀疏 FP16) |
| GPU | 2560 核 NVIDIA Blackwell 架构 GPU,具有 96 个第五代 Tensor Core,10 个 TPC 的 MIG | 1536 核 NVIDIA Blackwell 架构 GPU,具有 64 个第五代 Tensor Core,6 个 TPC 的 MIG | ||||||
| CPU | 14 核 Arm Neoverse-V3AE 64 位 CPU | 12 核 Arm Neoverse-V3AE 64 位 CPU | ||||||
| 内存 | 128 GB 256 位 LPDDR5X,273 GB/s | 64 GB 256 位 LPDDR5X,273 GB/s | ||||||
| 频率 | 1.57 GHz 最大 GPU 2.6 GHz 最大 CPU | 1.57 GHz 最大 GPU 2.6 GHz 最大 CPU | ||||||
| 存储 | 通过 PCIe 支持 NVMe;通过 USB3.2 支持 SSD | 通过 PCIe 支持 NVMe;通过 USB3.2 支持 SSD | ||||||
| 视觉加速器 | PVA v3.0 | PVA v3.0 | ||||||
| 视频编码 | 高达 6x4Kp60 (H.265/H.264) | 高达 6x4Kp60 (H.265/H.264)* | ||||||
| 视频解码 | 高达 4x 8Kp30 (H.265) 高达 4x 4Kp60 (H.264) | 高达 4x 8Kp30 (H.265)* 高达 4x 4Kp60 (H.264)* | ||||||
| 摄像头 | 通过 HSB 高达 20 个摄像头;通过 16x MIPI CSI-2 通道高达 6 个摄像头;使用虚拟通道 C-PHY 2.1 (10.25 Gbps) D-PHY 2.1 (40 Gbps) 高达 32 个摄像头 | 通过 HSB 高达 20 个摄像头;通过 16x MIPI CSI-2 通道高达 6 个摄像头;使用虚拟通道 C-PHY 2.1 (10.25 Gbps) D-PHY 2.1 (40 Gbps) 高达 32 个摄像头 | ||||||
| 显示 | 4x 共享 HDMI2.1 VESA Display Port 1.4a – HBR2, MST | 4x 共享 HDMI2.1 VESA Display Port 1.4a – HBR2, MST | ||||||
| 功耗 | 40 W – 130 W | 40 W – 70 W |
NVIDIA Jetson AGX Thor 开发者套件载板规格
| 规格 | 描述 |
|---|---|
| 集成 NVIDIA Jetson Thor 模组 | NVIDIA Jetson T5000 模组 |
| 存储 | M.2 Key M 插槽上集成 1TB NVMe |
| 摄像头 | 通过 QSFP 插槽连接 HSB 摄像头;USB 摄像头 |
| PCIe | M.2 Key M 插槽,带 x4 PCIe Gen5 (已安装 1TB NVMe);M.2 Key E 插槽,带 x1 PCIe Gen5 (已安装 Wi-Fi 6E 加蓝牙模组) |
| USB | 2 个 USB Type-A 3.2 Gen2;2 个 USB Type-C 3.1 Gen1;1 个 USB Type-C (仅用于调试) |
| 网络 | 1 个 5GBe RJ45 连接器;1 个 QSFP28 (4x 25GbE) |
| Wi-Fi | 802.11ax Wi-Fi 6E |
| 显示 | 1 个 HDMI 2.0b;1 个 DisplayPort 1.4a |
| 其他 I/O | 2 个 13 针 CAN 接头;2 个 6 针自动化接头;2 个 5 针接头;JTAG 连接器;1 个 4 针风扇连接器 – 12V, PWM, 和转速表;2 个 5 针音频面板接头;2 针 RTC 备用电池连接器;Microfit 电源插孔;电源、强制恢复和复位按钮 |
| 机械尺寸 | 243.19 毫米 x 112.40 毫米 x 56.88 毫米 (高度包括支脚、载板、模组和散热解决方案) |
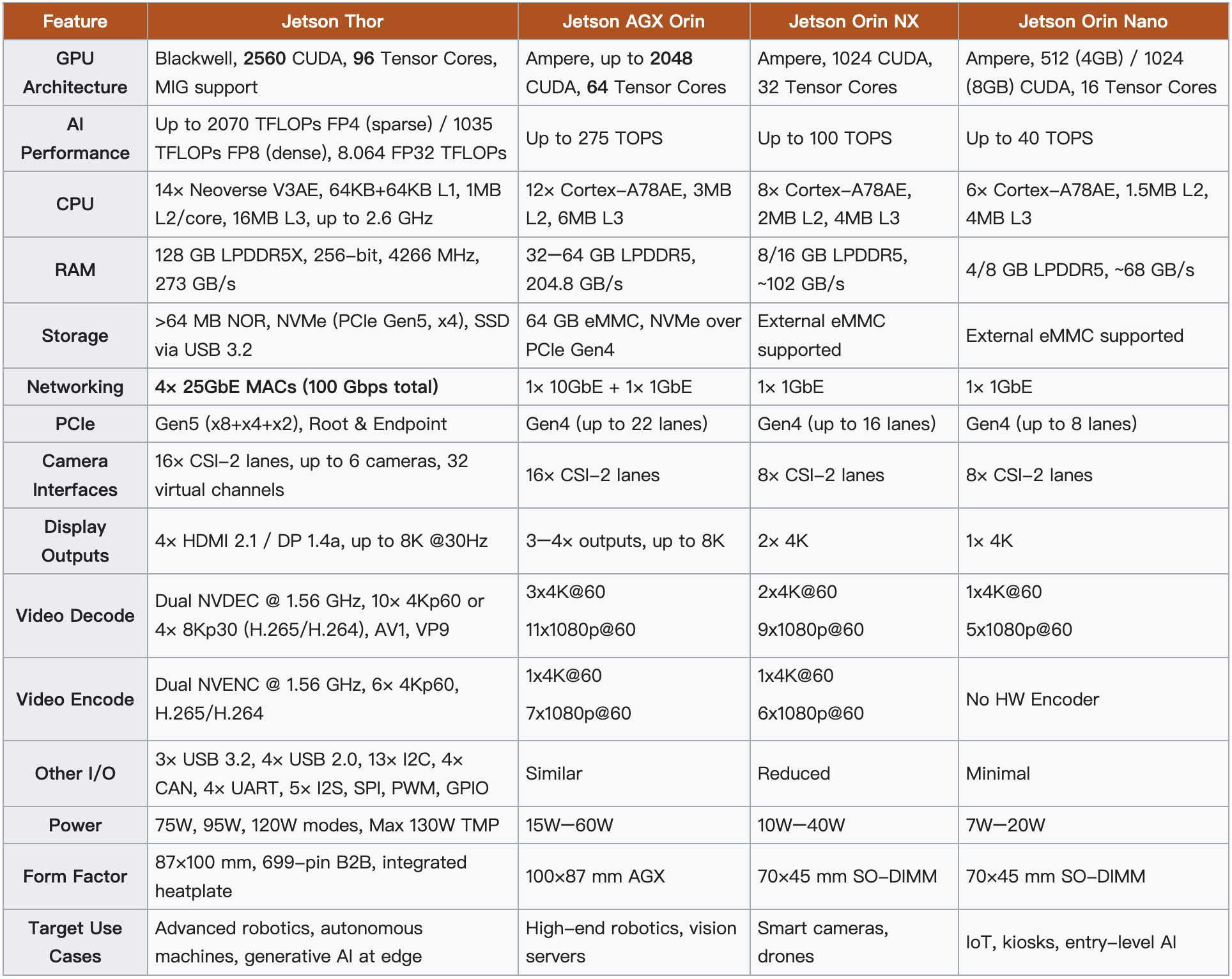
Jetson Thor 功能对比
信息查询
查询 Jetson 系统信息
# 用于记录系统(L4T - Linux for Tegra)的版本信息
cat /etc/nv_tegra_release
# R38 (release), REVISION: 2.0, GCID: 41844464, BOARD: generic, EABI: aarch64, DATE: Fri Aug 22 00:55:42 UTC 2025
# KERNEL_VARIANT: oot
TARGET_USERSPACE_LIB_DIR=nvidia
TARGET_USERSPACE_LIB_DIR_PATH=usr/lib/aarch64-linux-gnu/nvidia
INSTALL_TYPE=
查询指定 NVIDIA GPU 的计算能力(Compute Capability)
nvidia-smi -i 0 --query-gpu=compute_cap --format=csv,noheader
11.0
查询 NVIDIA GPU 的设备信息
docker run --rm --runtime=nvidia nvcr.io/nvidia/vllm:25.09-py3 /usr/local/bin/deviceQuery
/usr/local/bin/deviceQuery Starting...
CUDA Device Query (Driver API) statically linked version
Detected 1 CUDA Capable device(s)
Device 0: "NVIDIA Thor"
CUDA Driver Version: 13.0
CUDA Capability Major/Minor version number: 11.0
Total amount of global memory: 125772 MBytes (131881684992 bytes)
(20) Multiprocessors, (128) CUDA Cores/MP: 2560 CUDA Cores
GPU Max Clock rate: 1049 MHz (1.05 GHz)
Memory Clock rate: 0 Mhz
Memory Bus Width: 0-bit
L2 Cache Size: 33554432 bytes
Max Texture Dimension Sizes 1D=(131072) 2D=(131072, 65536) 3D=(16384, 16384, 16384)
Maximum Layered 1D Texture Size, (num) layers 1D=(32768), 2048 layers
Maximum Layered 2D Texture Size, (num) layers 2D=(32768, 32768), 2048 layers
Total amount of constant memory: 65536 bytes
Total amount of shared memory per block: 49152 bytes
Total number of registers available per block: 65536
Warp size: 32
Maximum number of threads per multiprocessor: 1536
Maximum number of threads per block: 1024
Max dimension size of a thread block (x,y,z): (1024, 1024, 64)
Max dimension size of a grid size (x,y,z): (2147483647, 65535, 65535)
Texture alignment: 512 bytes
Maximum memory pitch: 2147483647 bytes
Concurrent copy and kernel execution: Yes with 1 copy engine(s)
Run time limit on kernels: Yes
Integrated GPU sharing Host Memory: Yes
Support host page-locked memory mapping: Yes
Concurrent kernel execution: Yes
Alignment requirement for Surfaces: Yes
Device has ECC support: Disabled
Device supports Unified Addressing (UVA): Yes
Device supports Managed Memory: Yes
Device supports Compute Preemption: Yes
Supports Cooperative Kernel Launch: Yes
Supports MultiDevice Co-op Kernel Launch: Yes
Device PCI Domain ID / Bus ID / location ID: 0 / 1 / 0
Compute Mode:
< Default (multiple host threads can use ::cudaSetDevice() with device simultaneously) >
Result = PASS
收集环境信息
docker run --rm --runtime=nvidia nvcr.io/nvidia/vllm:25.09-py3 vllm collect-env
vllm collect-env 命令的作用是收集当前系统和环境的详细信息,特别是与 vLLM 库(一个用于大语言模型推理的开源库)运行相关的关键组件信息。
输出结果分成了几个主要部分,详细列出了运行 vLLM 所需或相关的软件和硬件信息:
- System Info (系统信息):
- 操作系统 (OS) 版本(如 Ubuntu 24.04.3 LTS, aarch64)。
- 编译器(GCC, Clang, CMake)和 C 库 (Libc) 版本。
- PyTorch Info (PyTorch 信息):
- PyTorch 版本(vLLM 依赖的深度学习框架)。
- 用于构建 PyTorch 的 CUDA 版本。
- Python Environment (Python 环境):
- Python 版本和平台架构(如 Python 3.12.3, Linux-aarch64)。
- CUDA / GPU Info (CUDA / GPU 信息):
- CUDA 是否可用,CUDA 运行时版本。
- GPU 型号和配置 (如 GPU 0: NVIDIA Thor)。
- Nvidia 驱动版本、cuDNN 版本。
- CPU Info (CPU 信息):
- CPU 架构 (aarch64)、核心数、缓存信息等。
- 有关 CPU 侧安全漏洞的缓解措施信息。
- Versions of relevant libraries (相关库版本):
- 通过
pip安装的与深度学习、GPU 相关的关键 Python 库的版本(如 numpy, nvidia-ml-py, onnx, torch, torchvision, transformers, triton)。
- 通过
- vLLM Info (vLLM 信息):
- vLLM 自身的版本 (
vLLM Version: 0.10.1.1...)。 - vLLM 的构建标志,例如支持的 CUDA 架构 (
CUDA Archs: 8.0 8.6 9.0 10.0 11.0 12.0+PTX)。 - GPU 拓扑结构 (GPU Topology) 和 NUMA 亲和性。
- vLLM 自身的版本 (
- Environment Variables (环境变量):
- 列出对 vLLM 或其依赖项(如 CUDA、PyTorch)有影响的关键环境变量(如
NVIDIA_VISIBLE_DEVICES,CUDA_VERSION,LD_LIBRARY_PATH)。
- 列出对 vLLM 或其依赖项(如 CUDA、PyTorch)有影响的关键环境变量(如
网络配置(静态 IP)
无线网络 / Wi-Fi 配置请参考文章:
查看网络设备状态
nmcli device status
DEVICE TYPE STATE CONNECTION
enP2p1s0 ethernet connecting (getting IP configuration) Wired connection 1
l4tbr0 bridge connected (externally) l4tbr0
lo loopback connected (externally) lo
docker0 bridge connected (externally) docker0
wlP1p1s0 wifi disconnected --
p2p-dev-wlP1p1s0 wifi-p2p disconnected --
mgbe0_0 ethernet unavailable --
mgbe1_0 ethernet unavailable --
mgbe2_0 ethernet unavailable --
mgbe3_0 ethernet unavailable --
can0 can unmanaged --
can1 can unmanaged --
can2 can unmanaged --
can3 can unmanaged --
usb0 ethernet unmanaged --
usb1 ethernet unmanaged --
查看网络设备的信息
ip addr show enP2p1s0
10: enP2p1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 4c:bb:47:01:ce:99 brd ff:ff:ff:ff:ff:ff
配置静态 IP 地址
sudo nmcli connection modify "Wired connection 1" \
ipv4.method manual \
ipv4.addresses "27.41.19.62/25" \
ipv4.gateway "27.41.19.1" \
ipv4.dns "27.41.84.1" \
connection.autoconnect yes
- IP: 27.41.19.62
- 子网掩码: 255.255.255.128
- 网关: 27.41.19.1
- DNS: 27.41.84.1
255.255.255.128 对应的CIDR是 /25,所以完整的CIDR表示是:27.41.19.62/25
重启网络连接
sudo nmcli connection down "Wired connection 1"
sudo nmcli connection up "Wired connection 1"
查看网络设备的信息
ip addr show enP2p1s0
10: enP2p1s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 4c:bb:47:01:ce:99 brd ff:ff:ff:ff:ff:ff
inet 27.41.19.62/25 brd 27.41.19.127 scope global noprefixroute enP2p1s0
valid_lft forever preferred_lft forever
inet6 fe80::568f:cf25:2b3a:55df/64 scope link noprefixroute
valid_lft forever preferred_lft forever
验证配置
# 查看连接详情
nmcli connection show "static-enP2p1s0"
# 检查IP地址配置
ip addr show enP2p1s0
# 检查路由
ip route show
# 测试网络连通性
ping -c 4 27.41.19.1
# 测试DNS
nslookup google.com 27.41.84.1
NVIDIA JetPack
NVIDIA JetPack™ 是 NVIDIA Jetson™ 平台官方软件套件,涵盖丰富工具和库,可用于打造 AI 赋能的边缘应用。JetPack 7 是系列最新版本,专为前沿机器人和生成式 AI 提供支持。JetPack 7 完全兼容 NVIDIA Jetson 平台,实现超低延迟、确定性性能,以及可扩展的物理世界机器部署方案。
JetPack 7 概述
JetPack 7 为 NVIDIA® Jetson Thor™ 平台提供全方位支持,具备可抢占的实时内核、Multi-Instance GPU (MIG) 及集成式 Holoscan Sensor Bridge。采用 Linux Kernel 6.8 及 Ubuntu 24.04 LTS,模块化云原生架构,结合最新 NVIDIA AI 计算堆栈,可无缝衔接 NVIDIA AI 工作流。无论是开发人形机器人,还是搭建高负载生成式 AI 应用,JetPack 7 为您的项目提供软件基础。
JetPack 7 采用 SBSA 架构设计
JetPack 7 使 Jetson 软件与服务器基础系统架构(SBSA)对齐,让 Jetson Thor 与业界 ARM 服务器标准保持一致。SBSA 规范关键硬件和固件接口,带来更强操作系统支持、更简便的软件移植及流畅企业集成。在此基础上,Jetson Thor 支持所有 Arm 目标统一安装 CUDA 13.0,简化开发流程、降低分化,确保从服务器系统到 Jetson Thor 的一致性。

JetPack 组件
Jetson 平台服务(Platform Services)
正在寻找一种更简单的方法来加速开发和部署复杂的边缘 AI 应用?Jetson 平台服务是 NVIDIA JetPack™ SDK 不可或缺的组件,可提供预构建和可定制的云原生软件服务来实现这一目标。企业、系统集成商和解决方案提供商可以使用这些 API 驱动的模块化服务,更快、更轻松地构建生成式 AI 和边缘应用。
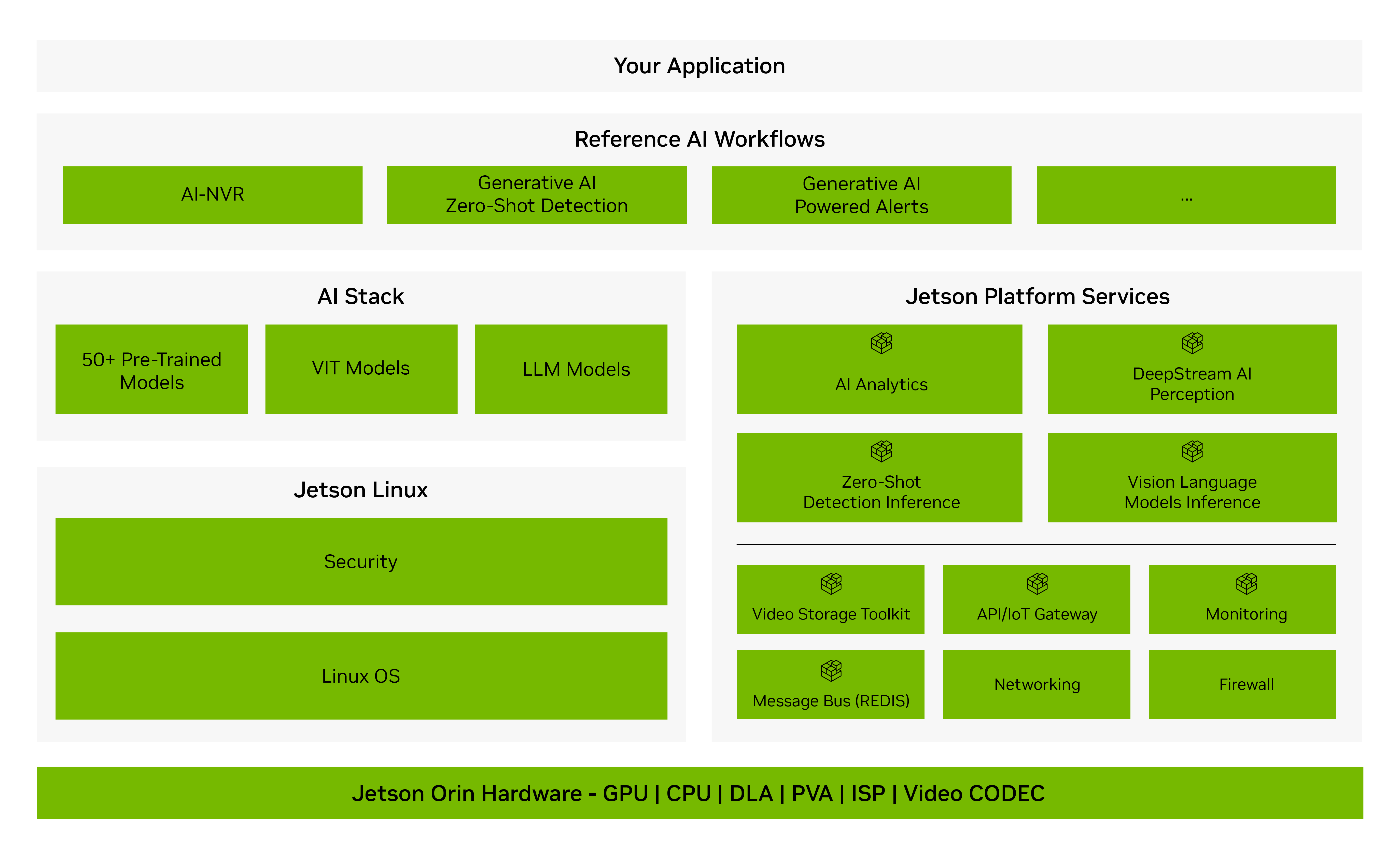
Jetson 云原生技术
云原生(Cloud-Native)技术具备快速产品开发和持续产品升级所需的灵活性与敏捷性。
Jetson 平台将云原生技术拓展至边缘计算领域,支持容器(containers)和容器编排等曾为云应用带来革命性变革的技术。
NVIDIA JetPack 包含集成了 Docker 的 NVIDIA 容器运行时(NVIDIA Container Runtime),可在 Jetson 平台上运行支持 GPU 加速的容器化应用。开发者能够将 Jetson 平台所需的应用及其所有依赖项打包到单个容器中,确保该容器在任何部署环境下都能正常运行。
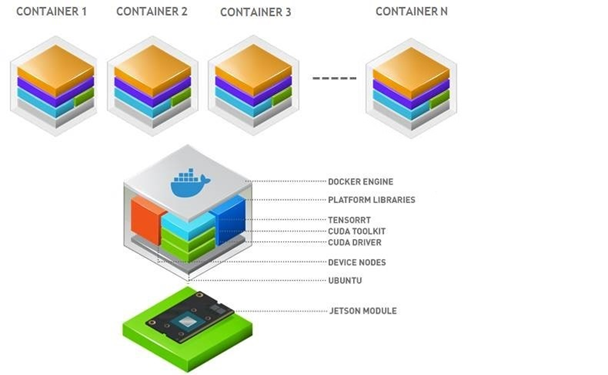
构建人工智能所需的一切 —— GPU 优化容器、预训练模型、软件开发工具包和 Helm 图表 —— 都统一在一个目录中,适用于云、数据中心或边缘环境。
Holoscan Sensor Bridge(HSB)
Holoscan 传感器桥接器专为低延迟数据流和控制而设计。它通过以太网使用用户数据协议 (UDP) 将传感器数据传输到 NVIDIA Jetson 和 NVIDIA IGX 等系统上的 GPU 显存,从而降低延迟和 CPU 占用率。它针对 NVIDIA ConnectX SmartNICs 和 camera-over-Ethernet 技术的使用进行了优化,可实现视频、边缘 AI 和机器人的实时处理。HSB 将原始传感器数据串流到 Holoscan SDK 中,支持从采集到推理和可视化的统一流程。
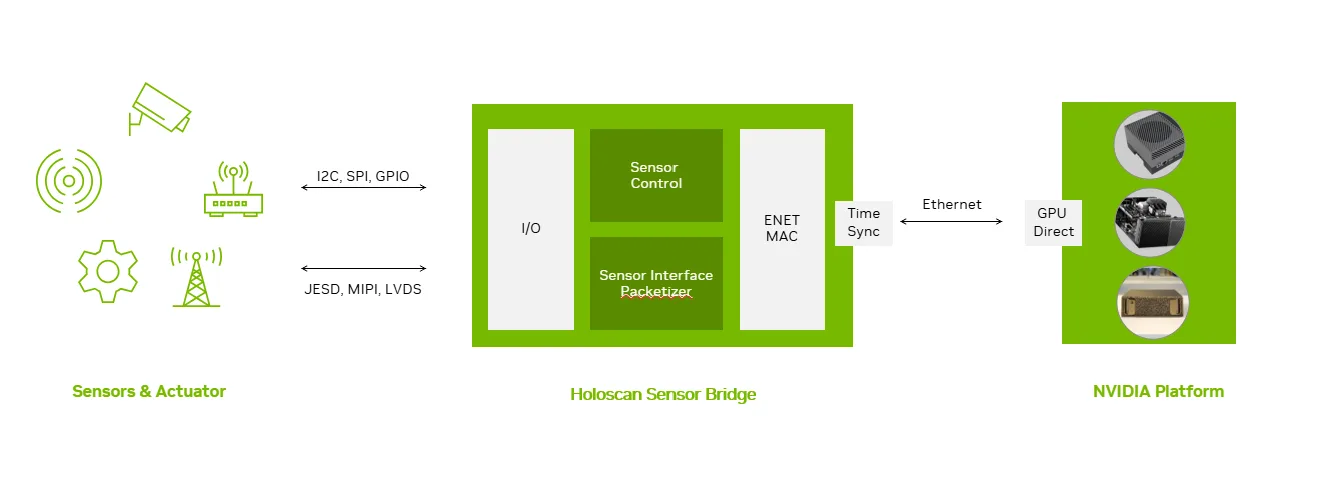
Holoscan Sensor Bridge 设计架构
NVIDIA Isaac
NVIDIA Isaac AI 机器人开发平台由 NVIDIA CUDA 加速库、应用框架和 AI 模型组成,可加速自主移动机器人 (AMR)、手臂和操纵器以及人形机器人等 AI 机器人的开发。
NVIDIA Metropolis
构建视觉 AI 智能体和应用程序的平台。
大模型
安装 modelscope
sudo apt install python3.12-venv
python -m venv venv
source venv/bin/activate
pip install modelscope
BFloat16
BFloat16 是一种 16 位浮点数格式,其关键优势在于拥有与 32 位浮点数 (FP32) 相同的 8 位指数位,这赋予它广阔的数值范围,使其在模型训练中能更好地处理梯度和激活值的极端值,因此被广泛采纳为大型语言模型训练的标准精度。
modelscope download --model Qwen/Qwen3-8B --local_dir Qwen/Qwen3-8B
modelscope download --model Qwen/Qwen3-30B-A3B --local_dir Qwen/Qwen3-30B-A3B
modelscope download --model Qwen/Qwen3-Coder-30B-A3B-Instruct --local_dir Qwen/Qwen3-Coder-30B-A3B-Instruct
FP8
FP8 是一种极端的 8 位浮点格式(常见为 E4M3 或 E5M2),它将数据量直接减半,主要目标是最大化显存节省和提高计算效率;在 LLM 中,它常被用于量化激活值和 KV 缓存,以运行更大的批次或模型,尽管它对保持精度提出了极高挑战。
modelscope download --model Qwen/Qwen3-8B-FP8 --local_dir Qwen/Qwen3-8B-FP8
modelscope download --model Qwen/Qwen3-32B-FP8 --local_dir Qwen/Qwen3-32B-FP8
modelscope download --model Qwen/Qwen3-30B-A3B-FP8 --local_dir Qwen/Qwen3-30B-A3B-FP8
modelscope download --model Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 --local_dir Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8
modelscope download --model Qwen/Qwen3-VL-30B-A3B-Instruct-FP8 --local_dir Qwen/Qwen3-VL-30B-A3B-Instruct-FP8
modelscope download --model nv-community/Qwen2.5-VL-7B-Instruct-FP8 --local_dir nv-community/Qwen2.5-VL-7B-Instruct-FP8
FP4
FP4 是进一步探索极致量化的 4 位格式,例如非线性的 NF4,其核心目的在于对模型权重进行最大程度的压缩,以实现最低的显存占用和最快的加载速度,是追求极致推理效率时的重要选择。
modelscope download --model nv-community/Qwen3-8B-FP4 --local_dir nv-community/Qwen3-8B-FP4
modelscope download --model nv-community/Qwen3-30B-A3B-FP4 --local_dir nv-community/Qwen3-30B-A3B-FP4
W4A16
W4A16 是一种在推理中寻求平衡的混合精度配置,它将模型权重压缩到 4 位(例如通过 GPTQ 或 AWQ 实现)以最大化节省显存和加速加载,而将模型激活值保持在 16 位(FP16/BF16)以确保计算过程的数值稳定性。
modelscope download --model okwinds/Qwen3-8B-Int4-W4A16 --local_dir okwinds/Qwen3-8B-Int4-W4A16
modelscope download --model okwinds/Qwen3-Coder-30B-A3B-Instruct-Int4-W4A16 --local_dir okwinds/Qwen3-Coder-30B-A3B-Instruct-Int4-W4A16
W8A16
W8A16 是一种比 W4A16 更保守的混合精度配置,它使用 8 位权重以提供比 4 位量化更高的精度保留,同时使用 16 位激活值来维持运算的精度和稳定性,适用于对精度要求较高但仍需一定内存优化的场景。
modelscope download --model okwinds/Qwen3-8B-Int8-W8A16 --local_dir okwinds/Qwen3-8B-Int8-W8A16
GPTQ
GPTQ 是一种高效的后训练量化 (PTQ) 技术,它通过基于近似二阶信息的一次性权重量化,将模型权重压缩到极低的 4 位精度,在大幅节省显存的同时,旨在通过分组优化来最小化模型性能的损失。
modelscope download --model JunHowie/Qwen3-8B-GPTQ-Int4 --local_dir JunHowie/Qwen3-8B-GPTQ-Int4
modelscope download --model JunHowie/Qwen3-8B-GPTQ-Int8 --local_dir JunHowie/Qwen3-8B-GPTQ-Int8
modelscope download --model Qwen/Qwen3-30B-A3B-GPTQ-Int4 --local_dir Qwen/Qwen3-30B-A3B-GPTQ-Int4
AWQ
AWQ 是一种后训练量化 (PTQ) 方法,其创新点在于识别出模型中少数极度重要的权重,并对这些关键权重跳过或特殊处理,以保持模型性能,因此它通常只需较小的校准数据集就能在 4 位量化中取得良好效果。
modelscope download --model Qwen/Qwen3-8B-AWQ --local_dir Qwen/Qwen3-8B-AWQ
modelscope download --model Qwen/Qwen3-32B-AWQ --local_dir Qwen/Qwen3-32B-AWQ
modelscope download --model cpatonn-mirror/Qwen3-Coder-30B-A3B-Instruct-AWQ-4bit --local_dir cpatonn-mirror/Qwen3-Coder-30B-A3B-Instruct-AWQ-4bit
modelscope download --model cpatonn-mirror/Qwen3-Coder-30B-A3B-Instruct-AWQ-8bit --local_dir cpatonn-mirror/Qwen3-Coder-30B-A3B-Instruct-AWQ-8bit
modelscope download --model Qwen/Qwen2.5-VL-7B-Instruct-AWQ --local_dir Qwen/Qwen2.5-VL-7B-Instruct-AWQ
GGUF
GGUF 是一种统一的文件格式和运行时规范,旨在将量化后的模型、元数据、词汇表等打包成一个单一且易于移植的文件,它支持多种量化等级,并被广泛用于 llama.cpp 等项目,特别优化了在本地设备上使用 CPU 进行 LLM 推理的效率。
modelscope download --model Qwen/Qwen3-8B-GGUF --local_dir Qwen/Qwen3-8B-GGUF
modelscope download --model Qwen/Qwen3-30B-A3B-GGUF --local_dir Qwen/Qwen3-30B-A3B-GGUF
语音
modelscope download --model iic/SenseVoiceSmall --local_dir iic/SenseVoiceSmall
modelscope download --model iic/CosyVoice2-0.5B --local_dir iic/CosyVoice2-0.5B
部署模型
通过 BSP 安装的 Jetson 系统,默认已经安装了 Docker 和 NVIDIA 容器运行时,可以直接使用 Docker 来部署模型。
⚠️ 目前 FP8 和 FP4 的模型,虽然部署成功了,但在实际使用时,服务会直接崩溃,原因是推理时使用的算子需要基于本地架构进行编译,通过在 GitHub Issues 和 NVIDIA 论坛中搜索,可能是软件生态还不够完善,需要等待一段时间吧。
镜像下载
- vllm
docker pull nvcr.io/nvidia/vllm:25.09-py3
- tritonserver:vllm
docker pull nvcr.io/nvidia/tritonserver:25.08-vllm-python-py3
- ollama
docker pull ghcr.io/nvidia-ai-iot/ollama:r38.2.arm64-sbsa-cu130-24.04
配置 Docker 运行时
/etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
},
"registry-mirrors": [
"https://docker.xuanyuan.me"
]
}
重启 Docker 服务
sudo systemctl restart docker
不使用 sudo 运行 Docker 命令
sudo usermod -aG docker $USER # 将当前用户加入 docker 组(永久生效,但需新会话)
newgrp docker # 立即启用新组权限(开启新 shell)
运行 Docker 容器
- vllm
docker run -it --rm \
--ipc=host \
--net=host \
--runtime=nvidia \
--name=vllm \
-v /home/lnsoft/wjj/models:/models \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v ~/.cache/modelscope:/root/.cache/modelscope \
nvcr.io/nvidia/vllm:25.09-py3 \
bash
- tritonserver:vllm
docker run -it --rm \
--ipc=host \
--net=host \
--runtime=nvidia \
--name=vllm \
-v /home/lnsoft/wjj/models:/models \
-v ~/.cache/huggingface:/root/.cache/huggingface \
-v ~/.cache/modelscope:/root/.cache/modelscope \
nvcr.io/nvidia/tritonserver:25.08-vllm-python-py3 \
bash
清理缓存
主动清理 Linux 系统的缓存,确保最大的可用内存。
sync && echo 3 | sudo tee /proc/sys/vm/drop_caches
- 1:释放页缓存(Page Cache)。
- 2:释放目录项和 inode 缓存(dentries and inodes)。
- 3:释放所有三种缓存(包括 PageCache, dentries, and inodes)。
/proc/sys/vm/drop_caches:Linux 内核内存管理接口
部署模型(容器内)
vllm serve /models/Qwen/Qwen3-8B --served-model-name qwen3
测试验证
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "qwen3",
"messages": [{"role": "user", "content": "你好,Jetson AGX Thor!"}],
"max_tokens": 64
}'
性能调优
请注意,
性能调优将导致更高的功耗和更大的热量产生,因此需要确保设备具有足够的散热能力。
功率模式
设置功率模式
设置 Jetson 设备的功率模式(Power Model)为最大性能模式(Maximum Performance)。
Nvidia Power Model Tool (Nvidia 功耗模型工具) 用于设置 Jetson 设备的功耗模式。
sudo nvpmodel -m 0
- 0: 最高性能模式,总功耗 130W,用于释放所有性能限制。
- 1: 受限的性能模式,总功耗限制在 120W 左右。(默认)
查看当前的功率模式
nvpmodel -q
默认的功率模式
NV Power Mode: 120W
1
设置的功率模式
NV Power Mode: MAXN
0
核心频率
将系统的核心频率锁定到当前功率模式下的最大值,它会禁用系统的动态电压频率调节 (DVFS) 机制。
在默认的 DVFS 机制下,系统会根据负载和温度动态调整 CPU、GPU 和内存的时钟频率,以达到功耗和性能的平衡。运行
sudo jetson_clocks会将 CPU、GPU 和 EMC(内存控制器) 的时钟频率锁定到当前活动的nvpmodel模式(在这里是模式 0)所允许的静态最大频率。
设置核心频率
每次重启后,核心频率都会被重置为默认值。所以,如果需要在每次重启后都保持相同的核心频率,请在每次重启后运行
sudo jetson_clocks命令。
sudo jetson_clocks
Enabled Legacy persistence mode for GPU 00000000:01:00.0.
All done.
查看当前的核心频率
sudo jetson_clocks --show
SOC family:tegra264 Machine:NVIDIA Jetson AGX Thor Developer Kit
Online CPUs: 0-13, Offline CPUs:
cpu0: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu1: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu2: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu3: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu4: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu5: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu6: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu7: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu8: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu9: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu10: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu11: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu12: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
cpu13: Governor=schedutil MinFreq=2601000 MaxFreq=2601000 CurrentFreq=2601000 IdleStates: WFI=0 cc7=0
gpu-gpc-0 MinFreq=1575000000 MaxFreq=1575000000 CurrentFreq=1575000000
gpu-nvd-0 MinFreq=1692000000 MaxFreq=1692000000 CurrentFreq=1692000000
EMC MinFreq=665600000 MaxFreq=4266000000 CurrentFreq=4266000000 FreqOverride=1
PVA0_VPS0: Online=0 MinFreq=0 MaxFreq=1215000000 CurrentFreq=1215000000
PVA0_AXI: Online=0 MinFreq=0 MaxFreq=909000000 CurrentFreq=909000000
FAN Dynamic Speed Control=nvfancontrol hwmon1_pwm1=73
FAN Dynamic Speed Control=nvfancontrol hwmon1_pwm1_enable=1
NV Power Mode: MAXN
基准测试
MAXN
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 50.88
Total input tokens: 204169
Total generated tokens: 12800
Request throughput (req/s): 1.97
Output token throughput (tok/s): 251.56
Total Token throughput (tok/s): 4264.12
---------------Time to First Token----------------
Mean TTFT (ms): 554.96
Median TTFT (ms): 495.34
P99 TTFT (ms): 1142.79
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 26.96
Median TPOT (ms): 26.84
P99 TPOT (ms): 29.10
---------------Inter-token Latency----------------
Mean ITL (ms): 26.96
Median ITL (ms): 22.31
P99 ITL (ms): 160.66
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 20.12
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.50
Output token throughput (tok/s): 63.61
Total Token throughput (tok/s): 1078.93
---------------Time to First Token----------------
Mean TTFT (ms): 35.70
Median TTFT (ms): 35.82
P99 TTFT (ms): 38.47
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 15.56
Median TPOT (ms): 15.54
P99 TPOT (ms): 15.79
---------------Inter-token Latency----------------
Mean ITL (ms): 15.56
Median ITL (ms): 15.61
P99 ITL (ms): 17.14
==================================================
MAXN + jetson_clocks
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 42.94
Total input tokens: 204169
Total generated tokens: 12800
Request throughput (req/s): 2.33
Output token throughput (tok/s): 298.07
Total Token throughput (tok/s): 5052.48
---------------Time to First Token----------------
Mean TTFT (ms): 495.44
Median TTFT (ms): 455.84
P99 TTFT (ms): 912.34
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 22.59
Median TPOT (ms): 23.00
P99 TPOT (ms): 25.05
---------------Inter-token Latency----------------
Mean ITL (ms): 22.59
Median ITL (ms): 17.88
P99 ITL (ms): 150.30
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 11.52
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.87
Output token throughput (tok/s): 111.15
Total Token throughput (tok/s): 1885.21
---------------Time to First Token----------------
Mean TTFT (ms): 23.06
Median TTFT (ms): 23.14
P99 TTFT (ms): 25.49
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 8.88
Median TPOT (ms): 8.88
P99 TPOT (ms): 8.98
---------------Inter-token Latency----------------
Mean ITL (ms): 8.88
Median ITL (ms): 8.68
P99 ITL (ms): 9.99
==================================================
120W
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 53.30
Total input tokens: 204169
Total generated tokens: 12800
Request throughput (req/s): 1.88
Output token throughput (tok/s): 240.14
Total Token throughput (tok/s): 4070.55
---------------Time to First Token----------------
Mean TTFT (ms): 580.06
Median TTFT (ms): 528.33
P99 TTFT (ms): 1282.32
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 28.27
Median TPOT (ms): 28.82
P99 TPOT (ms): 31.41
---------------Inter-token Latency----------------
Mean ITL (ms): 28.27
Median ITL (ms): 22.97
P99 ITL (ms): 174.90
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 20.03
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.50
Output token throughput (tok/s): 63.90
Total Token throughput (tok/s): 1083.83
---------------Time to First Token----------------
Mean TTFT (ms): 34.54
Median TTFT (ms): 34.47
P99 TTFT (ms): 37.52
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 15.50
Median TPOT (ms): 15.58
P99 TPOT (ms): 15.63
---------------Inter-token Latency----------------
Mean ITL (ms): 15.50
Median ITL (ms): 15.56
P99 ITL (ms): 17.10
==================================================
120W + jetson_clocks
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 51.24
Total input tokens: 204169
Total generated tokens: 12800
Request throughput (req/s): 1.95
Output token throughput (tok/s): 249.82
Total Token throughput (tok/s): 4234.69
---------------Time to First Token----------------
Mean TTFT (ms): 457.83
Median TTFT (ms): 500.31
P99 TTFT (ms): 1036.49
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 27.99
Median TPOT (ms): 27.96
P99 TPOT (ms): 30.22
---------------Inter-token Latency----------------
Mean ITL (ms): 27.99
Median ITL (ms): 21.98
P99 ITL (ms): 169.94
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 16.01
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.62
Output token throughput (tok/s): 79.94
Total Token throughput (tok/s): 1355.95
---------------Time to First Token----------------
Mean TTFT (ms): 27.23
Median TTFT (ms): 26.95
P99 TTFT (ms): 31.75
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 12.39
Median TPOT (ms): 12.40
P99 TPOT (ms): 12.48
---------------Inter-token Latency----------------
Mean ITL (ms): 12.39
Median ITL (ms): 12.39
P99 ITL (ms): 13.45
==================================================
性能分析
测试配置
本次基准测试使用的配置为:
- 模型/精度:Qwen3-8B-FP8
- 输入序列长度:2048 tokens
- 输出序列长度:128 tokens
- 高负载并发数:8
- 低负载并发数:1
高负载
| 模式 | jetson_clocks |
Output token throughput (tok/s) | Mean TTFT (ms) | Mean TPOT (ms) |
|---|---|---|---|---|
| MAXN | 否 | 251.56 | 554.96 | 26.96 |
| MAXN | 是 | 298.07 | 495.44 | 22.59 |
| 120W | 否 | 240.14 | 580.06 | 28.27 |
| 120W | 是 | 249.82 | 457.83 | 27.99 |
jetson_clocks效果显著:- 在 MAXN 模式下,运行
jetson_clocks后,吞吐量从 251.56 tok/s 提升至 298.07 tok/s(提升约 18.5%),Mean TPOT 从 26.96 ms 降低至 22.59 ms(减少约 16%)。 - 在 120W 模式下,运行
jetson_clocks后的性能提升不明显(240.14 tok/s $\to$ 249.82 tok/s),但 Mean TTFT 改善明显(580.06 ms $\to$ 457.83 ms)。
- 在 MAXN 模式下,运行
- MAXN +
jetson_clocks组合最佳:- MAXN +
jetson_clocks提供了最高吞吐量(298.07 tok/s)和最低的生成延迟(TPOT 22.59 ms),是高并发服务的最优选择。
- MAXN +
低负载
| 模式 | jetson_clocks |
Output token throughput (tok/s) | Mean TTFT (ms) | Mean TPOT (ms) |
|---|---|---|---|---|
| MAXN | 否 | 63.61 | 35.70 | 15.56 |
| MAXN | 是 | 111.15 | 23.06 | 8.88 |
| 120W | 否 | 63.90 | 34.54 | 15.50 |
| 120W | 是 | 79.94 | 27.23 | 12.39 |
jetson_clocks对延迟至关重要:- 无论在哪种功耗模式下,运行
jetson_clocks都能显著降低 TTFT 和 TPOT。 - 以 MAXN 模式为例,TTFT 从 35.70 ms 降至 23.06 ms(减少约 35%),TPOT 从 15.56 ms 降至 8.88 ms(减少约 43%)。
- 无论在哪种功耗模式下,运行
- MAXN +
jetson_clocks仍是最佳体验:- MAXN +
jetson_clocks组合提供了最低的首 Token 延迟(23.06 ms)和最低的生成延迟(8.88 ms)。对于追求最佳用户响应速度的场景,这是不二选择。
- MAXN +
测试结果表明在最高功耗模式 (MAXN) 下,强制锁定高频率(jetson_clocks)能够更好地释放硬件的全部潜力。
基准测试(性能)
测试配置
本次基准测试采用了以下配置参数对 Qwen3-8B 及其量化版本进行性能评估:
| 配置项 | 高负载配置 | 低负载配置 |
|---|---|---|
| 总请求数 | 100 | 10 |
| 最大并发数 | 8 | 1 |
| 输入序列长度 | 2048 tokens | 2048 tokens |
| 输出序列长度 | 128 tokens | 128 tokens |
| 测试场景 | 高吞吐量/高并发压力测试 | 低延迟/单用户体验测试 |
- 硬件:Jetson AGX Thor 128GB
- 操作系统:Ubuntu 24.04.3 LTS (GNU/Linux 6.8.12-tegra aarch64)
- 镜像版本:
nvcr.io/nvidia/vllm:25.09-py3 - vllm 版本:
0.10.1.1+381074ae - 测试工具:
vllm bench serve
| 模型 | 量化精度 | 量化后大小 | 网址 |
|---|---|---|---|
| Qwen3-8B | BF16 | 16 G | https://www.modelscope.cn/models/Qwen/Qwen3-8B |
| Qwen3-8B-FP8 | FP8 | 8.9 G | https://www.modelscope.cn/models/Qwen/Qwen3-8B-FP8 |
| Qwen3-8B-FP4 | FP4 | 6 G | https://www.modelscope.cn/models/nv-community/Qwen3-8B-FP4 |
| Qwen3-8B-GPTQ-Int4 | GPTQ(Int4) | 5.7 G | https://www.modelscope.cn/models/JunHowie/Qwen3-8B-GPTQ-Int4 |
| Qwen3-8B-GPTQ-Int8 | GPTQ(Int8) | 9 G | https://www.modelscope.cn/models/JunHowie/Qwen3-8B-GPTQ-Int8 |
| Qwen3-8B-AWQ | AWQ(Int4) | 5.7 G | https://www.modelscope.cn/models/Qwen/Qwen3-8B-AWQ |
| Qwen3-8B-Int4-W4A16 | W4A16 | 5.7 G | https://www.modelscope.cn/models/okwinds/Qwen3-8B-Int4-W4A16 |
| Qwen3-8B-Int8-W8A16 | W8A16 | 8.9 G | https://www.modelscope.cn/models/okwinds/Qwen3-8B-Int8-W8A16 |
| Qwen3-8B-GGUF | GGUF(Q5_K_M) | 5.5 G | https://www.modelscope.cn/models/Qwen/Qwen3-8B-GGUF |
工作流程
设置最大性能模式
sudo nvpmodel -m 0
sudo jetson_clocks
运行 vllm 容器
docker run -it --rm \
--ipc=host \
--net=host \
--runtime=nvidia \
--name=vllm \
-v /home/lnsoft/wjj/models:/models \
nvcr.io/nvidia/vllm:25.09-py3 \
bash
部署模型
vllm serve /models/Qwen/Qwen3-8B --served-model-name qwen3
运行基准测试
- 高负载
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 2048 \
--random-output-len 128 \
--num-prompts 100 \
--max-concurrency 8
- 低负载
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 2048 \
--random-output-len 128 \
--num-prompts 10 \
--max-concurrency 1
Qwen3-8B
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 150.59
Total input tokens: 204169
Total generated tokens: 12419
Request throughput (req/s): 0.66
Output token throughput (tok/s): 82.47
Total Token throughput (tok/s): 1438.24
---------------Time to First Token----------------
Mean TTFT (ms): 974.57
Median TTFT (ms): 959.99
P99 TTFT (ms): 2200.61
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 85.33
Median TPOT (ms): 86.05
P99 TPOT (ms): 90.57
---------------Inter-token Latency----------------
Mean ITL (ms): 85.33
Median ITL (ms): 72.52
P99 ITL (ms): 361.74
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 81.59
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.12
Output token throughput (tok/s): 15.69
Total Token throughput (tok/s): 266.09
---------------Time to First Token----------------
Mean TTFT (ms): 78.19
Median TTFT (ms): 78.22
P99 TTFT (ms): 80.61
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 63.63
Median TPOT (ms): 63.63
P99 TPOT (ms): 63.76
---------------Inter-token Latency----------------
Mean ITL (ms): 63.63
Median ITL (ms): 63.59
P99 ITL (ms): 64.89
==================================================
Qwen3-8B-FP8
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 42.94
Total input tokens: 204169
Total generated tokens: 12800
Request throughput (req/s): 2.33
Output token throughput (tok/s): 298.07
Total Token throughput (tok/s): 5052.48
---------------Time to First Token----------------
Mean TTFT (ms): 495.44
Median TTFT (ms): 455.84
P99 TTFT (ms): 912.34
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 22.59
Median TPOT (ms): 23.00
P99 TPOT (ms): 25.05
---------------Inter-token Latency----------------
Mean ITL (ms): 22.59
Median ITL (ms): 17.88
P99 ITL (ms): 150.30
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 11.52
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.87
Output token throughput (tok/s): 111.15
Total Token throughput (tok/s): 1885.21
---------------Time to First Token----------------
Mean TTFT (ms): 23.06
Median TTFT (ms): 23.14
P99 TTFT (ms): 25.49
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 8.88
Median TPOT (ms): 8.88
P99 TPOT (ms): 8.98
---------------Inter-token Latency----------------
Mean ITL (ms): 8.88
Median ITL (ms): 8.68
P99 ITL (ms): 9.99
==================================================
Qwen3-8B-FP4
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 74.12
Total input tokens: 204169
Total generated tokens: 12393
Request throughput (req/s): 1.35
Output token throughput (tok/s): 167.20
Total Token throughput (tok/s): 2921.73
---------------Time to First Token----------------
Mean TTFT (ms): 570.92
Median TTFT (ms): 460.86
P99 TTFT (ms): 1935.81
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 42.08
Median TPOT (ms): 41.89
P99 TPOT (ms): 50.72
---------------Inter-token Latency----------------
Mean ITL (ms): 42.09
Median ITL (ms): 33.41
P99 ITL (ms): 211.06
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 31.79
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.31
Output token throughput (tok/s): 40.26
Total Token throughput (tok/s): 682.94
---------------Time to First Token----------------
Mean TTFT (ms): 38.55
Median TTFT (ms): 38.39
P99 TTFT (ms): 40.58
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 24.73
Median TPOT (ms): 24.71
P99 TPOT (ms): 24.81
---------------Inter-token Latency----------------
Mean ITL (ms): 24.73
Median ITL (ms): 24.60
P99 ITL (ms): 25.78
==================================================
Qwen3-8B-GPTQ-Int4
- 高负载
============ Serving Benchmark Result ============
Successful requests: 200
Maximum request concurrency: 8
Benchmark duration (s): 240.75
Total input tokens: 408281
Total generated tokens: 24244
Request throughput (req/s): 0.83
Output token throughput (tok/s): 100.70
Total Token throughput (tok/s): 1796.55
---------------Time to First Token----------------
Mean TTFT (ms): 1918.40
Median TTFT (ms): 1886.97
P99 TTFT (ms): 3725.30
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 64.07
Median TPOT (ms): 65.20
P99 TPOT (ms): 77.52
---------------Inter-token Latency----------------
Mean ITL (ms): 63.69
Median ITL (ms): 31.55
P99 ITL (ms): 743.86
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 29.70
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.34
Output token throughput (tok/s): 43.09
Total Token throughput (tok/s): 730.96
---------------Time to First Token----------------
Mean TTFT (ms): 36.87
Median TTFT (ms): 36.94
P99 TTFT (ms): 38.49
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 23.09
Median TPOT (ms): 23.09
P99 TPOT (ms): 23.19
---------------Inter-token Latency----------------
Mean ITL (ms): 23.09
Median ITL (ms): 22.96
P99 ITL (ms): 24.13
==================================================
Qwen3-8B-GPTQ-Int8
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 156.75
Total input tokens: 204169
Total generated tokens: 12419
Request throughput (req/s): 0.64
Output token throughput (tok/s): 79.23
Total Token throughput (tok/s): 1381.78
---------------Time to First Token----------------
Mean TTFT (ms): 2225.45
Median TTFT (ms): 1899.85
P99 TTFT (ms): 5168.47
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 81.04
Median TPOT (ms): 83.37
P99 TPOT (ms): 91.55
---------------Inter-token Latency----------------
Mean ITL (ms): 81.04
Median ITL (ms): 45.06
P99 ITL (ms): 858.38
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 47.19
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.21
Output token throughput (tok/s): 27.13
Total Token throughput (tok/s): 460.11
---------------Time to First Token----------------
Mean TTFT (ms): 50.83
Median TTFT (ms): 50.65
P99 TTFT (ms): 53.36
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 36.75
Median TPOT (ms): 36.74
P99 TPOT (ms): 36.86
---------------Inter-token Latency----------------
Mean ITL (ms): 36.75
Median ITL (ms): 36.83
P99 ITL (ms): 37.66
==================================================
Qwen3-8B-AWQ
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 123.36
Total input tokens: 204169
Total generated tokens: 12392
Request throughput (req/s): 0.81
Output token throughput (tok/s): 100.45
Total Token throughput (tok/s): 1755.51
---------------Time to First Token----------------
Mean TTFT (ms): 1823.17
Median TTFT (ms): 1529.95
P99 TTFT (ms): 4474.37
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 63.92
Median TPOT (ms): 65.64
P99 TPOT (ms): 77.46
---------------Inter-token Latency----------------
Mean ITL (ms): 63.99
Median ITL (ms): 31.84
P99 ITL (ms): 745.13
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 30.00
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.33
Output token throughput (tok/s): 42.66
Total Token throughput (tok/s): 723.61
---------------Time to First Token----------------
Mean TTFT (ms): 36.95
Median TTFT (ms): 37.39
P99 TTFT (ms): 38.72
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 23.33
Median TPOT (ms): 23.36
P99 TPOT (ms): 23.40
---------------Inter-token Latency----------------
Mean ITL (ms): 23.33
Median ITL (ms): 23.17
P99 ITL (ms): 24.34
==================================================
Qwen3-8B-Int4-W4A16
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 124.74
Total input tokens: 204169
Total generated tokens: 12419
Request throughput (req/s): 0.80
Output token throughput (tok/s): 99.56
Total Token throughput (tok/s): 1736.36
---------------Time to First Token----------------
Mean TTFT (ms): 2114.14
Median TTFT (ms): 2230.05
P99 TTFT (ms): 4737.55
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 62.10
Median TPOT (ms): 61.38
P99 TPOT (ms): 71.65
---------------Inter-token Latency----------------
Mean ITL (ms): 62.10
Median ITL (ms): 31.80
P99 ITL (ms): 746.19
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 29.98
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.33
Output token throughput (tok/s): 42.70
Total Token throughput (tok/s): 724.22
---------------Time to First Token----------------
Mean TTFT (ms): 37.85
Median TTFT (ms): 38.06
P99 TTFT (ms): 39.91
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 23.30
Median TPOT (ms): 23.31
P99 TPOT (ms): 23.41
---------------Inter-token Latency----------------
Mean ITL (ms): 23.30
Median ITL (ms): 23.11
P99 ITL (ms): 24.41
==================================================
Qwen3-8B-Int8-W8A16
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 152.79
Total input tokens: 204169
Total generated tokens: 12419
Request throughput (req/s): 0.65
Output token throughput (tok/s): 81.28
Total Token throughput (tok/s): 1417.54
---------------Time to First Token----------------
Mean TTFT (ms): 2294.06
Median TTFT (ms): 2376.24
P99 TTFT (ms): 5134.68
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 77.95
Median TPOT (ms): 80.18
P99 TPOT (ms): 87.64
---------------Inter-token Latency----------------
Mean ITL (ms): 77.95
Median ITL (ms): 45.00
P99 ITL (ms): 852.45
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 46.51
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.22
Output token throughput (tok/s): 27.52
Total Token throughput (tok/s): 466.84
---------------Time to First Token----------------
Mean TTFT (ms): 50.23
Median TTFT (ms): 50.24
P99 TTFT (ms): 51.65
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 36.22
Median TPOT (ms): 36.22
P99 TPOT (ms): 36.25
---------------Inter-token Latency----------------
Mean ITL (ms): 36.22
Median ITL (ms): 36.24
P99 ITL (ms): 37.03
==================================================
Qwen3-8B-GGUF
推荐:Qwen3-8B-Q5_K_M.gguf
- Q5_K_M (5-bit K-quantization with medium group size) 是一种高效的量化方案。
-
它通常能在保持接近原始模型性能的同时,提供良好的内存节省和推理速度提升。
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 1617.23
Total input tokens: 204169
Total generated tokens: 12800
Request throughput (req/s): 0.06
Output token throughput (tok/s): 7.91
Total Token throughput (tok/s): 134.16
---------------Time to First Token----------------
Mean TTFT (ms): 43688.41
Median TTFT (ms): 47162.20
P99 TTFT (ms): 93242.93
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 670.56
Median TPOT (ms): 706.07
P99 TPOT (ms): 830.26
---------------Inter-token Latency----------------
Mean ITL (ms): 670.56
Median ITL (ms): 88.76
P99 ITL (ms): 15722.16
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 1
Benchmark duration (s): 4.39
Total input tokens: 2048
Total generated tokens: 128
Request throughput (req/s): 0.23
Output token throughput (tok/s): 29.14
Total Token throughput (tok/s): 495.41
---------------Time to First Token----------------
Mean TTFT (ms): 148.53
Median TTFT (ms): 148.53
P99 TTFT (ms): 148.53
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 33.41
Median TPOT (ms): 33.41
P99 TPOT (ms): 33.41
---------------Inter-token Latency----------------
Mean ITL (ms): 33.41
Median ITL (ms): 33.34
P99 ITL (ms): 34.03
==================================================
性能分析
高负载
在高并发场景下,模型的吞吐量和平均延迟是关键性能指标。
| 模型 | 量化精度 | 量化后大小 | Request throughput (req/s) | Output token throughput (tok/s) | Mean TTFT (ms) | Mean TPOT (ms) |
|---|---|---|---|---|---|---|
| Qwen3-8B | BF16 | 16 G | 0.66 | 82.47 | 974.57 | 85.33 |
| Qwen3-8B-FP8 🚀 | FP8 | 8.9 G | 2.33 | 298.07 | 495.44 | 22.59 |
| Qwen3-8B-FP4 | FP4 | 6 G | 1.35 | 167.20 | 570.92 | 42.08 |
| Qwen3-8B-GPTQ-Int4 | GPTQ(Int4) | 5.7 G | 0.83 | 100.70 | 1918.40 | 64.07 |
| Qwen3-8B-GPTQ-Int8 | GPTQ(Int8) | 9 G | 0.64 | 79.23 | 2225.45 | 81.04 |
| Qwen3-8B-AWQ | AWQ(Int4) | 5.7 G | 0.81 | 100.45 | 1823.17 | 63.92 |
| Qwen3-8B-Int4-W4A16 | W4A16 | 5.7 G | 0.80 | 99.56 | 2114.14 | 62.10 |
| Qwen3-8B-Int8-W8A16 | W8A16 | 8.9 G | 0.65 | 81.28 | 2294.06 | 77.95 |
| Qwen3-8B-GGUF | GGUF(Q5_K_M) | 5.5 G | 0.06 | 7.91 | 43688.41 | 670.56 |
分析总结:
- FP8 性能遥遥领先: FP8 模型在所有指标上都表现最佳。其输出 Token 吞吐量(298.07 tok/s)是基线 BF16 模型(82.47 tok/s)的 3.6 倍,同时将平均每 Token 延迟(TPOT)降至最低的 22.59 ms。这得益于其半精度的带宽优势和高效的计算优化。
- FP4 吞吐量优秀: FP4 模型在减小模型大小的同时,吞吐量(167.20 tok/s)显著优于所有 Int4 量化方案(约 100 tok/s),是性能的第二选择。
- Int4 量化 TTFT 恶化: 尽管 GPTQ、AWQ 等 Int4 方案模型尺寸小(约 5.7G),但在高并发下,其平均首 Token 延迟(Mean TTFT)急剧恶化,普遍在 1.8 到 2.2 秒之间,远高于 BF16 基线(974.57 ms)和 FP 方案。这表明这些方案在处理高并发请求时,反量化或上下文切换的开销很大。
- GGUF 表现最差: GGUF(Q5_K_M)在高并发下表现极差,吞吐量最低(7.91 tok/s),TTFT 高达 43.7 秒,不适合高并发服务。
低负载
在低并发场景下,首 Token 延迟(TTFT) 对于用户体验至关重要,而 TPOT 代表持续生成速度。
| 模型 | 量化精度 | 量化后大小 | Request throughput (req/s) | Output token throughput (tok/s) | Mean TTFT (ms) | Mean TPOT (ms) |
|---|---|---|---|---|---|---|
| Qwen3-8B | BF16 | 16 G | 0.12 | 15.69 | 78.19 | 63.63 |
| Qwen3-8B-FP8 🚀 | FP8 | 8.9 G | 0.87 | 111.15 | 23.06 | 8.88 |
| Qwen3-8B-FP4 | FP4 | 6 G | 0.31 | 40.26 | 38.55 | 24.73 |
| Qwen3-8B-GPTQ-Int4 | GPTQ(Int4) | 5.7 G | 0.34 | 43.09 | 36.87 | 23.09 |
| Qwen3-8B-GPTQ-Int8 | GPTQ(Int8) | 9 G | 0.21 | 27.13 | 50.83 | 36.75 |
| Qwen3-8B-AWQ | AWQ(Int4) | 5.7 G | 0.33 | 42.66 | 36.95 | 23.33 |
| Qwen3-8B-Int4-W4A16 | W4A16 | 5.7 G | 0.33 | 42.70 | 37.85 | 23.30 |
| Qwen3-8B-Int8-W8A16 | W8A16 | 8.9 G | 0.22 | 27.52 | 50.23 | 36.22 |
| Qwen3-8B-GGUF | GGUF(Q5_K_M) | 5.5 G | 0.23 | 29.14 | 148.53 | 33.41 |
分析总结:
- FP8 统治地位依旧: FP8 仍然是最快的,其 TTFT 仅为 23.06 ms,TPOT 仅为 8.88 ms。这意味着用户几乎可以瞬时获得第一个 Token,并以最快的速度接收后续内容。
- Int4/FP4 性能持平: 在低负载下,FP4 和 Int4 方案(GPTQ, AWQ, W4A16)的 TTFT 都在 36 ms 至 38 ms 之间,TPOT 都在 23 ms 至 25 ms 之间,性能非常接近,且都远优于基线 BF16 模型。这表明在无并发竞争时,这些量化方案都能有效地加速推理。
- GGUF 延迟较高: GGUF 虽然模型尺寸最小(5.5G),但其 TTFT(148.53 ms)和 TPOT(33.41 ms)均不如 BF16 以外的其他方案。
性能与模型大小的权衡
| 模型/方案 | 量化后大小 | 性能表现 (高负载) | 性能表现 (低负载) | 适用场景 |
|---|---|---|---|---|
| Qwen3-8B-FP8 | 8.9G | 最高吞吐量(298.07 tok/s) | 最低延迟(TTFT 23.06 ms) | 性能优先、高并发服务 |
| Qwen3-8B-FP4 | 6G | 高吞吐量(167.20 tok/s) | 低延迟(TTFT 38.55 ms) | 模型尺寸和性能的良好平衡 |
| Int4 方案 (GPTQ/AWQ/W4A16) | 5.7G | 吞吐量中等,TTFT 严重恶化 | 低延迟(TTFT ≈ 37 ms) | 对模型尺寸最敏感、仅限低并发/单用户部署 |
| Int8 方案 (GPTQ/W8A16) | 9G | 最低吞吐量,TTFT 严重恶化 | 延迟中等(TTFT ≈ 50 ms) | 不推荐用于服务部署 |
| Qwen3-8B (BF16) | 16G | 最低吞吐量 | 延迟最高 | 基准测试,无需量化 |
| Qwen3-8B-GGUF | 5.5G | 极差 | 较差 | CPU 或边缘设备部署,牺牲性能 |
最终建议:
- 追求极致性能和高并发: Qwen3-8B-FP8 是毫无疑问的最佳选择,它以 8.9G 的大小实现了最高的吞吐量和最低的延迟。
- 追求最小尺寸和平衡性能: 如果显存资源非常紧张,Qwen3-8B-FP4(6G)提供了比其他 Int4 方案更好的高负载性能。若服务并发很低,任意 Int4 方案(5.7G)都是可接受的。
- 避免 GGUF 用于在线服务: GGUF 虽然文件最小,但在 GPU 推理服务中的性能(尤其在高并发下)极低,应仅考虑用于 CPU 或受限的边缘设备推理。
Qwen3-Coder-30B-A3B-Instruct-Int4-W4A16
- 高负载
============ Serving Benchmark Result ============
Successful requests: 100
Maximum request concurrency: 8
Benchmark duration (s): 99.27
Total input tokens: 204169
Total generated tokens: 12789
Request throughput (req/s): 1.01
Output token throughput (tok/s): 128.83
Total Token throughput (tok/s): 2185.54
---------------Time to First Token----------------
Mean TTFT (ms): 1314.33
Median TTFT (ms): 1111.64
P99 TTFT (ms): 3123.45
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 51.26
Median TPOT (ms): 52.49
P99 TPOT (ms): 59.17
---------------Inter-token Latency----------------
Mean ITL (ms): 51.27
Median ITL (ms): 30.34
P99 ITL (ms): 523.20
==================================================
- 低负载
============ Serving Benchmark Result ============
Successful requests: 10
Maximum request concurrency: 1
Benchmark duration (s): 19.68
Total input tokens: 20431
Total generated tokens: 1280
Request throughput (req/s): 0.51
Output token throughput (tok/s): 65.05
Total Token throughput (tok/s): 1103.33
---------------Time to First Token----------------
Mean TTFT (ms): 41.75
Median TTFT (ms): 43.20
P99 TTFT (ms): 46.20
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 15.16
Median TPOT (ms): 15.16
P99 TPOT (ms): 15.19
---------------Inter-token Latency----------------
Mean ITL (ms): 15.16
Median ITL (ms): 15.15
P99 ITL (ms): 15.68
==================================================
基准测试(场景)
- 镜像版本:
nvcr.io/nvidia/tritonserver:25.08-vllm-python-py3 - vllm 版本:
0.9.2
测试场景
| 场景 | random-input-len | random-output-len | num-prompts |
|---|---|---|---|
| 预热 | 1024 | 128 | 100 |
| 对话 | 128 | 64 | 1000 |
| 高吞吐量 | 256 | 512 | 1000 |
| 长上下文 | 1024 | 128 | 1000 |
1. 预热
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--random-input-len 1024 \
--random-output-len 128 \
--num-prompts 100
2. 对话场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 128 \
--random-output-len 64 \
--num-prompts 1000
3. 高吞吐量场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 256 \
--random-output-len 512 \
--num-prompts 1000
4. 长上下文场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 1024 \
--random-output-len 128 \
--num-prompts 1000
Qwen/Qwen3-8B
模型部署
vllm serve /models/Qwen/Qwen3-8B \
--port 8000 \
--served-model-name qwen3 \
--max-model-len 32000 \
--gpu-memory-utilization 0.9
对话场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 128 \
--random-output-len 64 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 46.48
Total input tokens: 127521
Total generated tokens: 62082
Request throughput (req/s): 21.52
Output token throughput (tok/s): 1335.80
Total Token throughput (tok/s): 4079.62
---------------Time to First Token----------------
Mean TTFT (ms): 19115.49
Median TTFT (ms): 16719.37
P99 TTFT (ms): 40381.70
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 165.65
Median TPOT (ms): 179.31
P99 TPOT (ms): 188.64
---------------Inter-token Latency----------------
Mean ITL (ms): 165.05
Median ITL (ms): 102.03
P99 ITL (ms): 510.22
==================================================
高吞吐量场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 256 \
--random-output-len 512 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 345.18
Total input tokens: 255191
Total generated tokens: 478793
Request throughput (req/s): 2.90
Output token throughput (tok/s): 1387.09
Total Token throughput (tok/s): 2126.39
---------------Time to First Token----------------
Mean TTFT (ms): 123528.06
Median TTFT (ms): 92979.97
P99 TTFT (ms): 282225.26
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 168.77
Median TPOT (ms): 174.96
P99 TPOT (ms): 185.47
---------------Inter-token Latency----------------
Mean ITL (ms): 168.29
Median ITL (ms): 147.41
P99 ITL (ms): 602.51
==================================================
长上下文场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B \
--dataset-name random \
--random-input-len 1024 \
--random-output-len 128 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 471.01
Total input tokens: 1021646
Total generated tokens: 123508
Request throughput (req/s): 2.12
Output token throughput (tok/s): 262.22
Total Token throughput (tok/s): 2431.28
---------------Time to First Token----------------
Mean TTFT (ms): 209787.40
Median TTFT (ms): 206818.42
P99 TTFT (ms): 448316.75
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 783.01
Median TPOT (ms): 882.62
P99 TPOT (ms): 896.30
---------------Inter-token Latency----------------
Mean ITL (ms): 783.20
Median ITL (ms): 888.09
P99 ITL (ms): 903.99
==================================================
Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8
模型部署
vllm serve /models/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 --served-model-name qwen3
对话场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 \
--dataset-name random \
--random-input-len 128 \
--random-output-len 64 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 66.93
Total input tokens: 127521
Total generated tokens: 63872
Request throughput (req/s): 14.94
Output token throughput (tok/s): 954.33
Total Token throughput (tok/s): 2859.67
---------------Time to First Token----------------
Mean TTFT (ms): 29213.45
Median TTFT (ms): 24896.09
P99 TTFT (ms): 60083.47
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 241.88
Median TPOT (ms): 252.47
P99 TPOT (ms): 297.77
---------------Inter-token Latency----------------
Mean ITL (ms): 241.96
Median ITL (ms): 192.50
P99 ITL (ms): 571.64
==================================================
高吞吐量场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 \
--dataset-name random \
--random-input-len 256 \
--random-output-len 512 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 384.50
Total input tokens: 255191
Total generated tokens: 504103
Request throughput (req/s): 2.60
Output token throughput (tok/s): 1311.07
Total Token throughput (tok/s): 1974.77
---------------Time to First Token----------------
Mean TTFT (ms): 142234.69
Median TTFT (ms): 95529.07
P99 TTFT (ms): 307812.16
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 186.97
Median TPOT (ms): 199.74
P99 TPOT (ms): 217.30
---------------Inter-token Latency----------------
Mean ITL (ms): 185.47
Median ITL (ms): 166.00
P99 ITL (ms): 738.75
==================================================
长上下文场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-Coder-30B-A3B-Instruct-FP8 \
--dataset-name random \
--random-input-len 1024 \
--random-output-len 128 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 541.03
Total input tokens: 1021646
Total generated tokens: 127223
Request throughput (req/s): 1.85
Output token throughput (tok/s): 235.15
Total Token throughput (tok/s): 2123.50
---------------Time to First Token----------------
Mean TTFT (ms): 236102.28
Median TTFT (ms): 227295.14
P99 TTFT (ms): 523762.85
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 916.02
Median TPOT (ms): 1060.07
P99 TPOT (ms): 1088.53
---------------Inter-token Latency----------------
Mean ITL (ms): 916.60
Median ITL (ms): 1080.27
P99 ITL (ms): 1168.64
==================================================
okwinds/Qwen3-8B-Int4-W4A16
模型部署
VLLM_DISABLED_KERNELS=MacheteLinearKernel \
vllm serve /models/okwinds/Qwen3-8B-Int4-W4A16 \
--port 8000 \
--served-model-name qwen3 \
--max-model-len 32000 \
--gpu-memory-utilization 0.9
VLLM_DISABLED_KERNELS=MacheteLinearKernel
禁用定制优化:它告诉 vLLM 不要使用 MacheteLinearKernel 这个为 4-bit 量化模型设计的、高度优化的 CUDA 内核。这种方法是一个有效的临时解决方案,能够让您立即启动模型进行测试。
对话场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/okwinds/Qwen3-8B-Int4-W4A16 \
--dataset-name random \
--random-input-len 128 \
--random-output-len 64 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 75.87
Total input tokens: 127521
Total generated tokens: 62484
Request throughput (req/s): 13.18
Output token throughput (tok/s): 823.58
Total Token throughput (tok/s): 2504.40
---------------Time to First Token----------------
Mean TTFT (ms): 32741.44
Median TTFT (ms): 29547.32
P99 TTFT (ms): 69400.40
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 268.98
Median TPOT (ms): 301.16
P99 TPOT (ms): 313.77
---------------Inter-token Latency----------------
Mean ITL (ms): 268.32
Median ITL (ms): 126.23
P99 ITL (ms): 854.40
==================================================
高吞吐量场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/okwinds/Qwen3-8B-Int4-W4A16 \
--dataset-name random \
--random-input-len 256 \
--random-output-len 512 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 403.56
Total input tokens: 255191
Total generated tokens: 470428
Request throughput (req/s): 2.48
Output token throughput (tok/s): 1165.70
Total Token throughput (tok/s): 1798.05
---------------Time to First Token----------------
Mean TTFT (ms): 150162.80
Median TTFT (ms): 117509.58
P99 TTFT (ms): 345428.49
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 203.26
Median TPOT (ms): 217.11
P99 TPOT (ms): 248.70
---------------Inter-token Latency----------------
Mean ITL (ms): 201.96
Median ITL (ms): 172.77
P99 ITL (ms): 966.66
==================================================
长上下文场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/okwinds/Qwen3-8B-Int4-W4A16 \
--dataset-name random \
--random-input-len 1024 \
--random-output-len 128 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 671.15
Total input tokens: 1021646
Total generated tokens: 123608
Request throughput (req/s): 1.49
Output token throughput (tok/s): 184.17
Total Token throughput (tok/s): 1706.41
---------------Time to First Token----------------
Mean TTFT (ms): 309627.45
Median TTFT (ms): 306525.40
P99 TTFT (ms): 648530.40
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 1109.58
Median TPOT (ms): 1252.48
P99 TPOT (ms): 1267.25
---------------Inter-token Latency----------------
Mean ITL (ms): 1109.18
Median ITL (ms): 1256.14
P99 ITL (ms): 1276.80
==================================================
okwinds/Qwen3-Coder-30B-A3B-Instruct-Int4-W4A16
模型部署
VLLM_DISABLED_KERNELS=MacheteLinearKernel \
vllm serve /models/okwinds/Qwen3-Coder-30B-A3B-Instruct-Int4-W4A16 \
--port 8000 \
--served-model-name qwen3 \
--max-model-len 16000 \
--gpu-memory-utilization 0.95
对话场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/okwinds/Qwen3-Coder-30B-A3B-Instruct-Int4-W4A16 \
--dataset-name random \
--random-input-len 128 \
--random-output-len 64 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 61.14
Total input tokens: 127521
Total generated tokens: 63800
Request throughput (req/s): 16.35
Output token throughput (tok/s): 1043.44
Total Token throughput (tok/s): 3129.04
---------------Time to First Token----------------
Mean TTFT (ms): 25856.00
Median TTFT (ms): 22808.47
P99 TTFT (ms): 54261.26
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 216.23
Median TPOT (ms): 238.58
P99 TPOT (ms): 246.64
---------------Inter-token Latency----------------
Mean ITL (ms): 215.22
Median ITL (ms): 124.65
P99 ITL (ms): 577.63
==================================================
高吞吐量场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/okwinds/Qwen3-Coder-30B-A3B-Instruct-Int4-W4A16 \
--dataset-name random \
--random-input-len 256 \
--random-output-len 512 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 374.62
Total input tokens: 255191
Total generated tokens: 500683
Request throughput (req/s): 2.67
Output token throughput (tok/s): 1336.52
Total Token throughput (tok/s): 2017.73
---------------Time to First Token----------------
Mean TTFT (ms): 141835.32
Median TTFT (ms): 101236.88
P99 TTFT (ms): 307108.71
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 181.67
Median TPOT (ms): 187.91
P99 TPOT (ms): 204.51
---------------Inter-token Latency----------------
Mean ITL (ms): 181.42
Median ITL (ms): 150.46
P99 ITL (ms): 812.16
==================================================
长上下文场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/okwinds/Qwen3-Coder-30B-A3B-Instruct-Int4-W4A16 \
--dataset-name random \
--random-input-len 1024 \
--random-output-len 128 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 598.99
Total input tokens: 1021646
Total generated tokens: 126897
Request throughput (req/s): 1.67
Output token throughput (tok/s): 211.85
Total Token throughput (tok/s): 1917.47
---------------Time to First Token----------------
Mean TTFT (ms): 254949.29
Median TTFT (ms): 237700.22
P99 TTFT (ms): 577361.42
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 1023.92
Median TPOT (ms): 1207.47
P99 TPOT (ms): 1240.32
---------------Inter-token Latency----------------
Mean ITL (ms): 1023.03
Median ITL (ms): 1225.72
P99 ITL (ms): 1329.30
==================================================
Qwen/Qwen3-8B-AWQ
模型部署
vllm serve /models/Qwen/Qwen3-8B-AWQ \
--port 8000 \
--served-model-name qwen3 \
--max-model-len 32000 \
--gpu-memory-utilization 0.9
对话场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B-AWQ \
--dataset-name random \
--random-input-len 128 \
--random-output-len 64 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 78.30
Total input tokens: 127521
Total generated tokens: 62030
Request throughput (req/s): 12.77
Output token throughput (tok/s): 792.18
Total Token throughput (tok/s): 2420.75
---------------Time to First Token----------------
Mean TTFT (ms): 33502.02
Median TTFT (ms): 30555.16
P99 TTFT (ms): 71248.42
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 278.23
Median TPOT (ms): 308.20
P99 TPOT (ms): 328.85
---------------Inter-token Latency----------------
Mean ITL (ms): 277.72
Median ITL (ms): 130.00
P99 ITL (ms): 860.93
==================================================
高吞吐量场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B-AWQ \
--dataset-name random \
--random-input-len 256 \
--random-output-len 512 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 404.02
Total input tokens: 255191
Total generated tokens: 477499
Request throughput (req/s): 2.48
Output token throughput (tok/s): 1181.87
Total Token throughput (tok/s): 1813.51
---------------Time to First Token----------------
Mean TTFT (ms): 151728.03
Median TTFT (ms): 116351.25
P99 TTFT (ms): 340206.59
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 200.64
Median TPOT (ms): 214.60
P99 TPOT (ms): 236.85
---------------Inter-token Latency----------------
Mean ITL (ms): 199.14
Median ITL (ms): 172.79
P99 ITL (ms): 984.32
==================================================
长上下文场景
vllm bench serve \
--base-url http://localhost:8000 \
--model qwen3 \
--tokenizer /models/Qwen/Qwen3-8B-AWQ \
--dataset-name random \
--random-input-len 1024 \
--random-output-len 128 \
--num-prompts 1000
============ Serving Benchmark Result ============
Successful requests: 1000
Benchmark duration (s): 673.51
Total input tokens: 1021646
Total generated tokens: 123934
Request throughput (req/s): 1.48
Output token throughput (tok/s): 184.01
Total Token throughput (tok/s): 1700.91
---------------Time to First Token----------------
Mean TTFT (ms): 310565.61
Median TTFT (ms): 307672.55
P99 TTFT (ms): 650003.44
-----Time per Output Token (excl. 1st token)------
Mean TPOT (ms): 1114.62
Median TPOT (ms): 1256.36
P99 TPOT (ms): 1272.11
---------------Inter-token Latency----------------
Mean ITL (ms): 1114.34
Median ITL (ms): 1259.18
P99 ITL (ms): 1290.74
==================================================
TensorRT-LLM
模型部署
docker run --rm -it \
--ipc=host \
--ulimit memlock=-1 \
--ulimit stack=67108864 \
--runtime=nvidia \
-v /models:/models \
nvcr.io/nvidia/tensorrt-llm/release:1.2.0rc1 \
bash
# trtllm-serve TinyLlama/TinyLlama-1.1B-Chat-v1.0
trtllm-serve /models/Qwen/Qwen3-8B-FP8
- Quick Start Recipe for Qwen3 Next on TensorRT LLM - Blackwell & Hopper Hardware
- Run benchmarking with trtllm-serve
FAQ
RuntimeError: Unsupported SM version for FP8 block scaling GEMM
[10/24/2025-13:08:47] [TRT-LLM] [I] get signal from executor worker
[10/24/2025-13:08:47] [TRT-LLM] [E] Executor worker initialization error: Traceback (most recent call last):
File "/usr/local/lib/python3.12/dist-packages/tensorrt_llm/executor/worker.py", line 364, in worker_main
worker: GenerationExecutorWorker = worker_cls(
参考资料
- NVIDIA Jetson Linux Developer Guide
- Docker on NVIDIA GPU Cloud
- Introducing NVIDIA Jetson Thor, the Ultimate Platform for Physical AI
- NVIDIA Jetson Thor,专为物理 AI 打造的卓越平台
- NVIDIA Jetson 开发者套件
- Running LLMs with TensorRT-LLM on Nvidia Jetson AGX Orin
- How to Run vLLM on Jetson AGX Thor?
- Gen AI Benchmarking: LLMs and VLMs on Jetson
- NVIDIA® Jetson™ - Powered Edge AI Device Collection
- Ollama Docker image
- Run LLM Stuck while use Jetson Thor
- NVIDIA JETSON AGX THOR DEVELOPER KIT - The Ultimate Platform for Humanoid Robotics
- Performance Comparison of Qwen3-30B-A3B-AWQ on Jetson Thor vs Orin AGX 64GB
- NVIDIA Triton Inference Server
- Triton Inference Server
- CUDA Toolkit 13.0 Update 1 Downloads
- sys_cache_cleaner.sh
- vllm_benchmark_server.sh
- Docker Hub - vLLM
- Docker Hub - SGLang
- Docker Hub - GPUStack
- 后台启用缓存清理器
- vLLM 性能基准测试示例(使用Qwen2.5-VL-3B)
- NVIDIA Jetson AI Lab Benchmarks
- Gen AI Benchmarking: LLMs and VLMs on Jetson
- Performance Comparison of Qwen3-30B-A3B-AWQ on Jetson Thor vs Orin AGX 64GB
- MIG User Guide
- MXFP4, FP4, and FP8: How GPT-OSS Runs 120B Parameters on an 80GB GPU with MoE Weight Quantization
- nvidia/cuda
- sbsa/cu130 index
- jp6/cu129 index
- vLLM Installation GPU