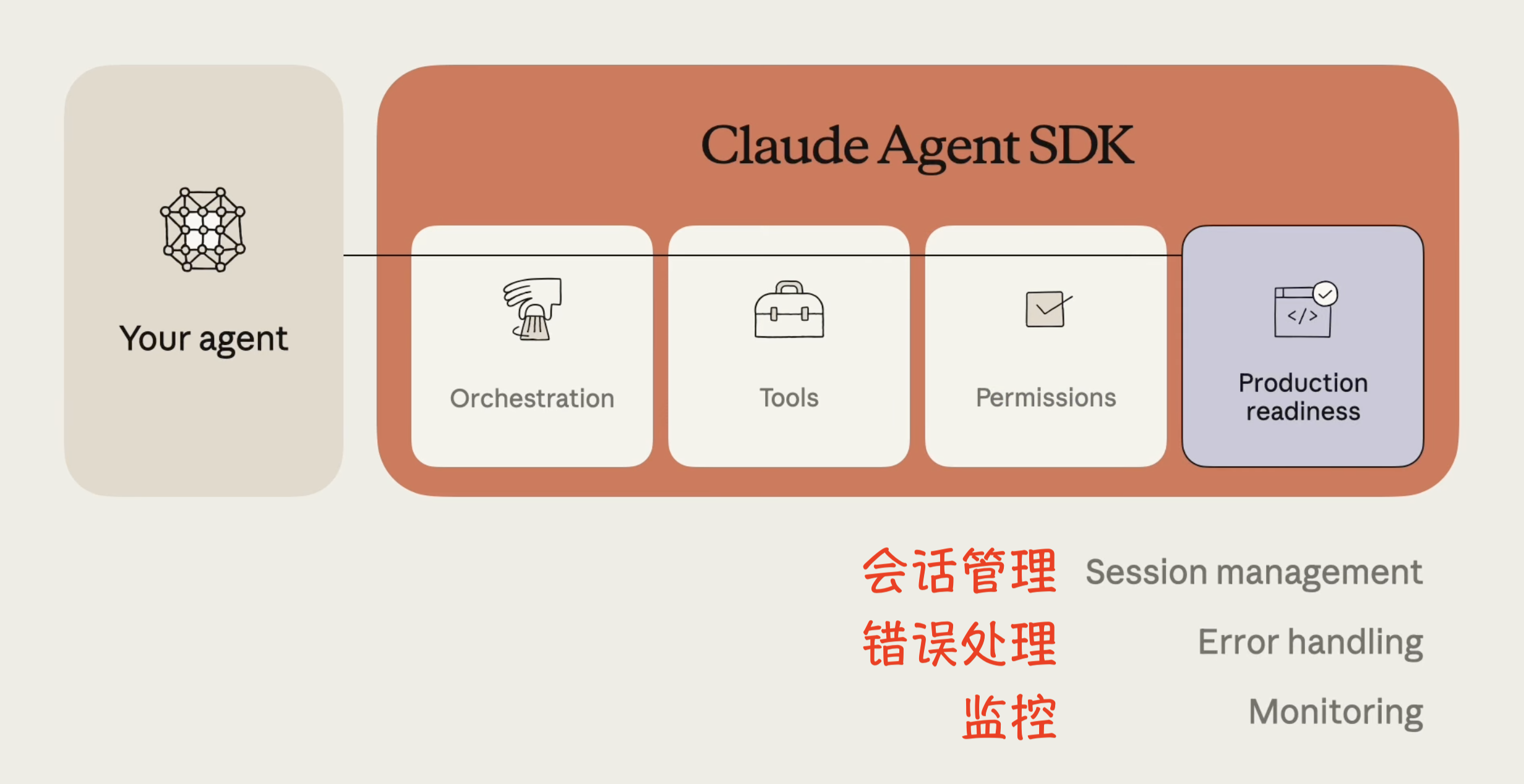
使用 Claude Agent SDK 构建智能体
Claude Agent SDK 是 Anthropic 发布的、用于在 Claude Code 基础上构建强大智能体(agents)的工具集合。该 SDK 最初是作为 Claude Code SDK(一个智能编码解决方案)发布的,旨在支持 Anthropic 内部的开发者效率。由于 Claude Code 已经超越了编码工具的范畴,被用于深度研究、视频制作和笔记记录等无数非编码应用,因此该工具被更名为 Claude Agent SDK,以反映其更广泛的愿景。
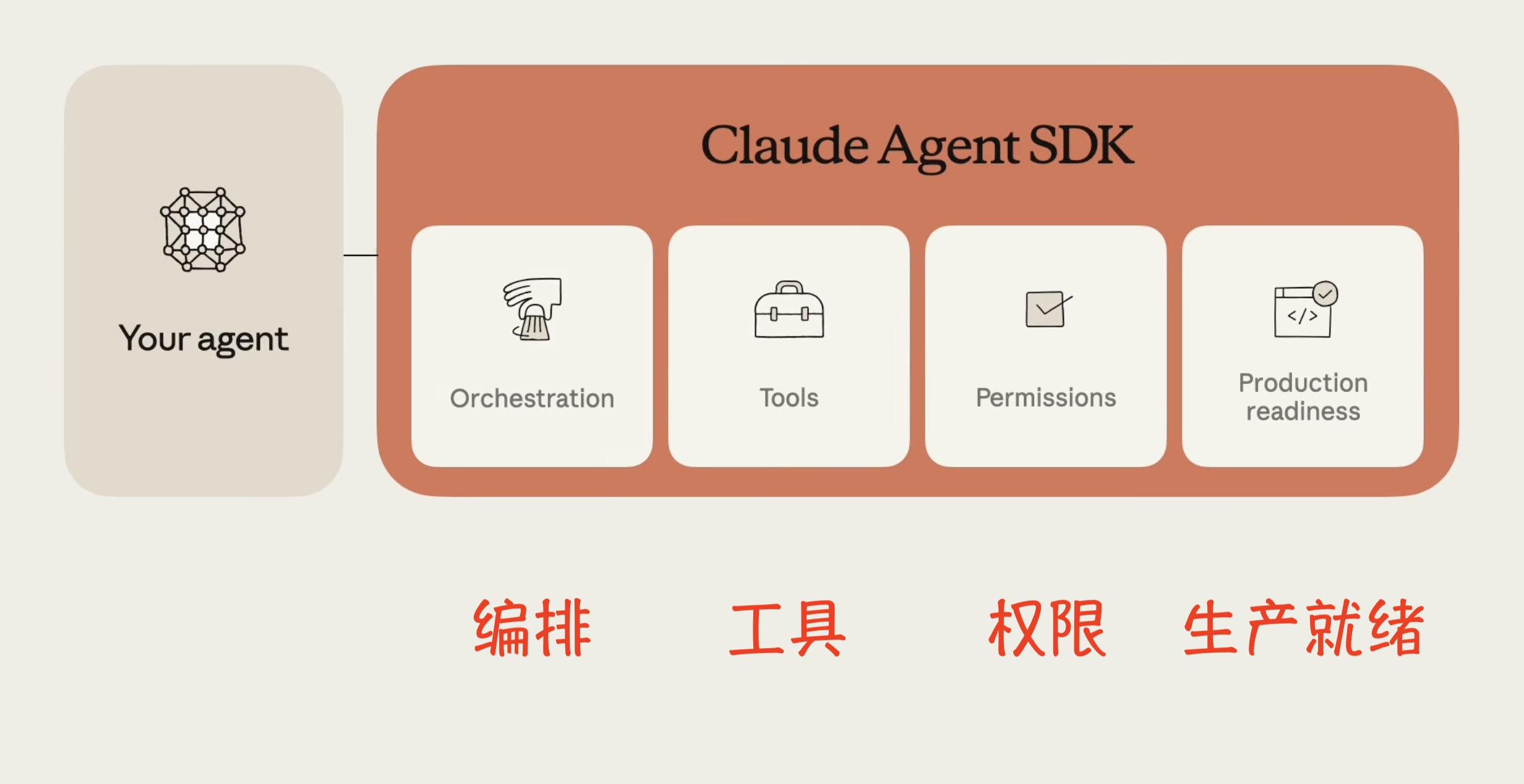
一、核心设计原则:赋予 Claude 计算机能力
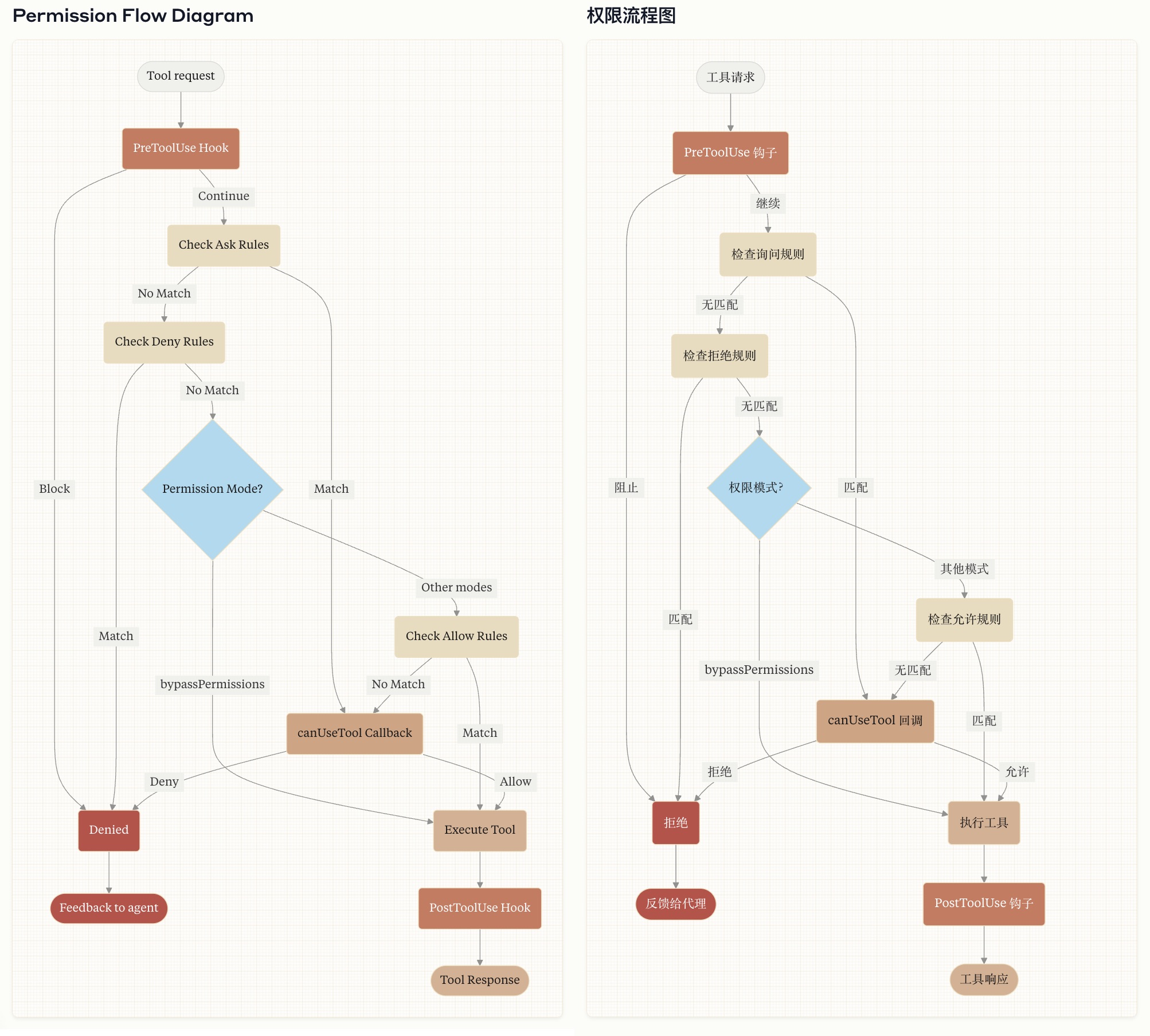
Claude Agent SDK 的关键设计原则是让 Claude 拥有程序员日常使用的相同工具。这意味着 Claude 必须能够:在代码库中查找文件、编写和编辑文件、运行代码、调试、以及迭代执行这些操作直到成功。
通过允许 Claude 访问用户计算机(经由终端),并赋予其运行 bash 命令、编辑文件、创建文件和搜索文件的能力,它能够有效执行非编码任务,如:阅读 CSV 文件、搜索网络、构建可视化、解释指标等数字工作,从而创建出具有通用目的的智能体。
二、构建的新型智能体
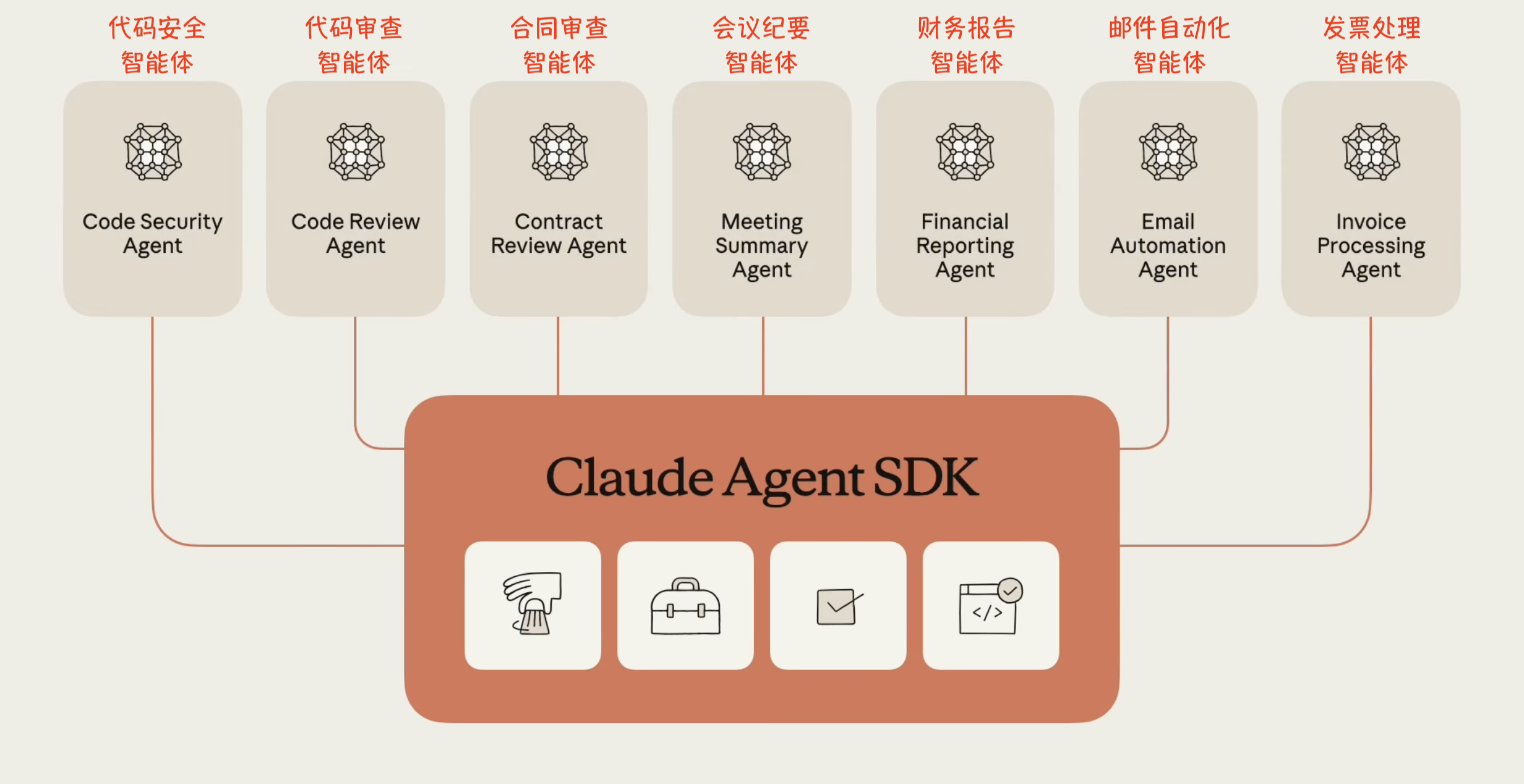
赋予 Claude 计算机能力解锁了许多以前效率不高的智能体类型。SDK 提供了用于自动化任何工作流程的原语,开发者可以构建:
- 金融智能体(Finance agents): 能够理解投资组合和目标,并通过访问外部 API、存储数据和运行代码进行计算来评估投资。
- 个人助理智能体(Personal assistant agents): 通过连接到内部数据源并在应用程序中跟踪上下文,帮助预订旅行、管理日历、安排约会和整理简报。
- 客户支持智能体(Customer support agents): 通过收集和审查用户数据、连接到外部 API、回复用户消息并在必要时升级给人类,来处理客户服务工单等高模糊度的用户请求。
- 深度研究智能体(Deep research agents): 通过搜索文件系统、分析和综合来自多个来源的信息、跨文件交叉引用数据以及生成详细报告,进行全面的研究。
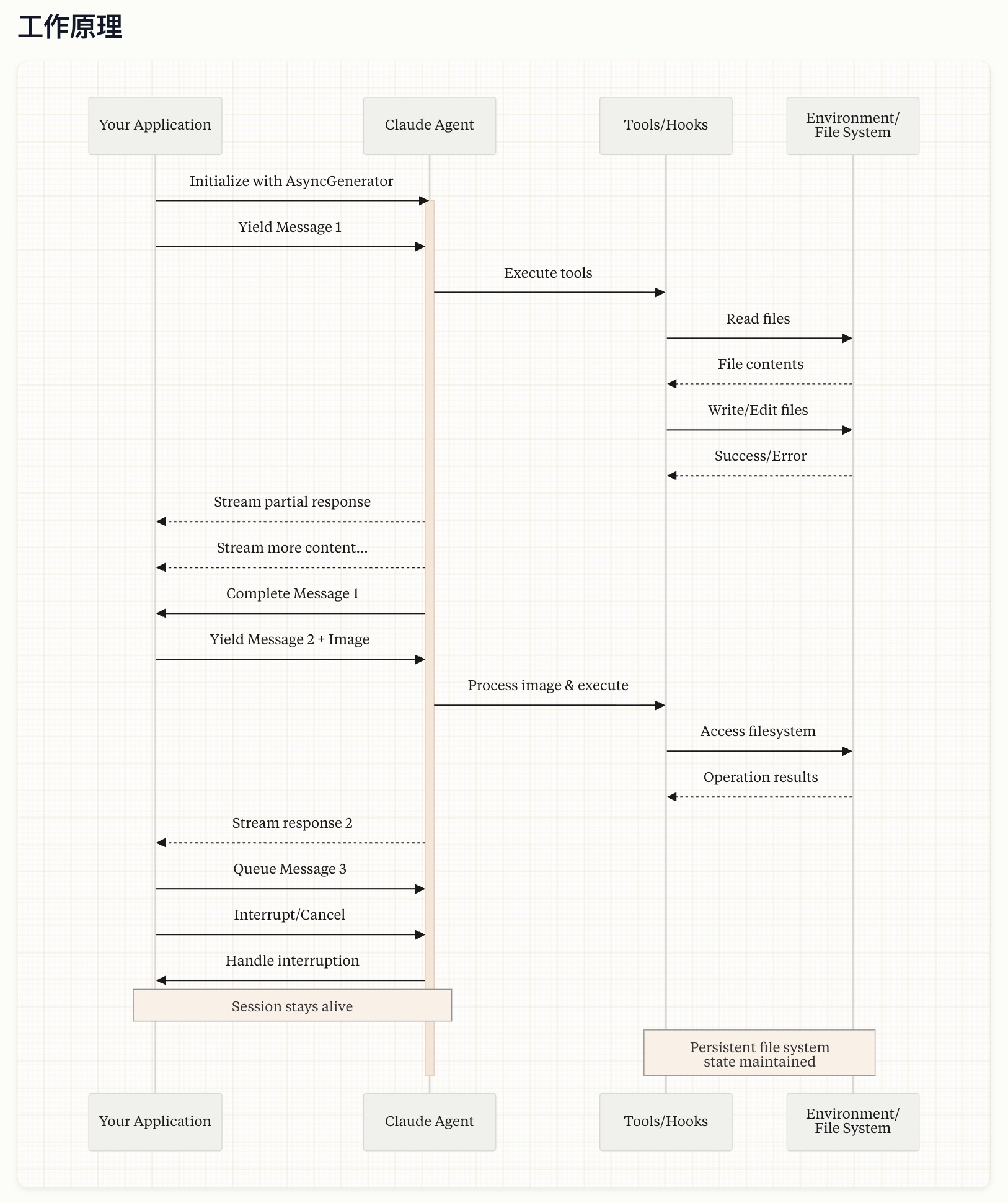
三、构建智能体的循环(Agent Loop)
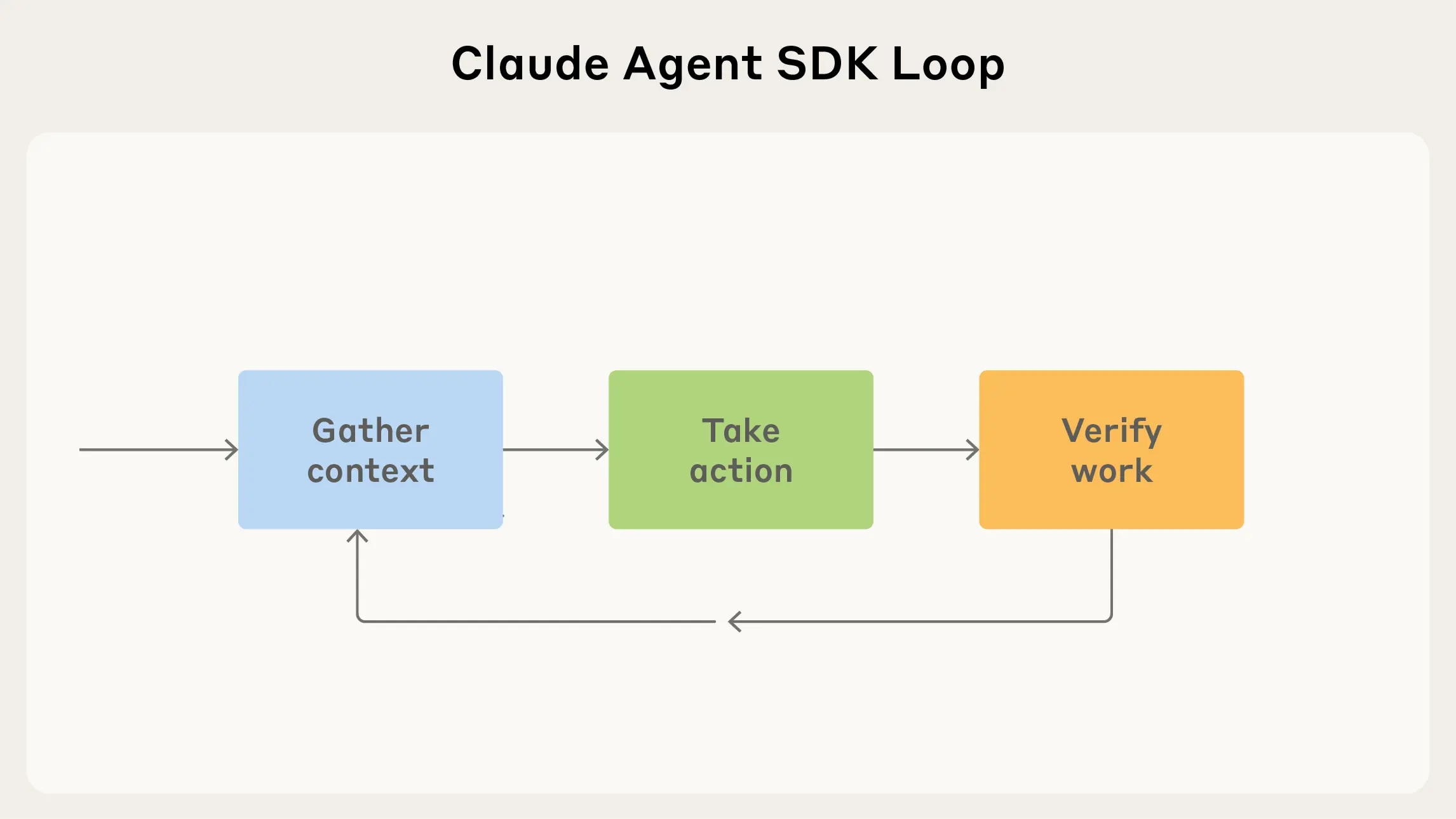
智能体通常在一个特定的反馈循环中运作:收集上下文 -> 采取行动 -> 验证工作 -> 重复。
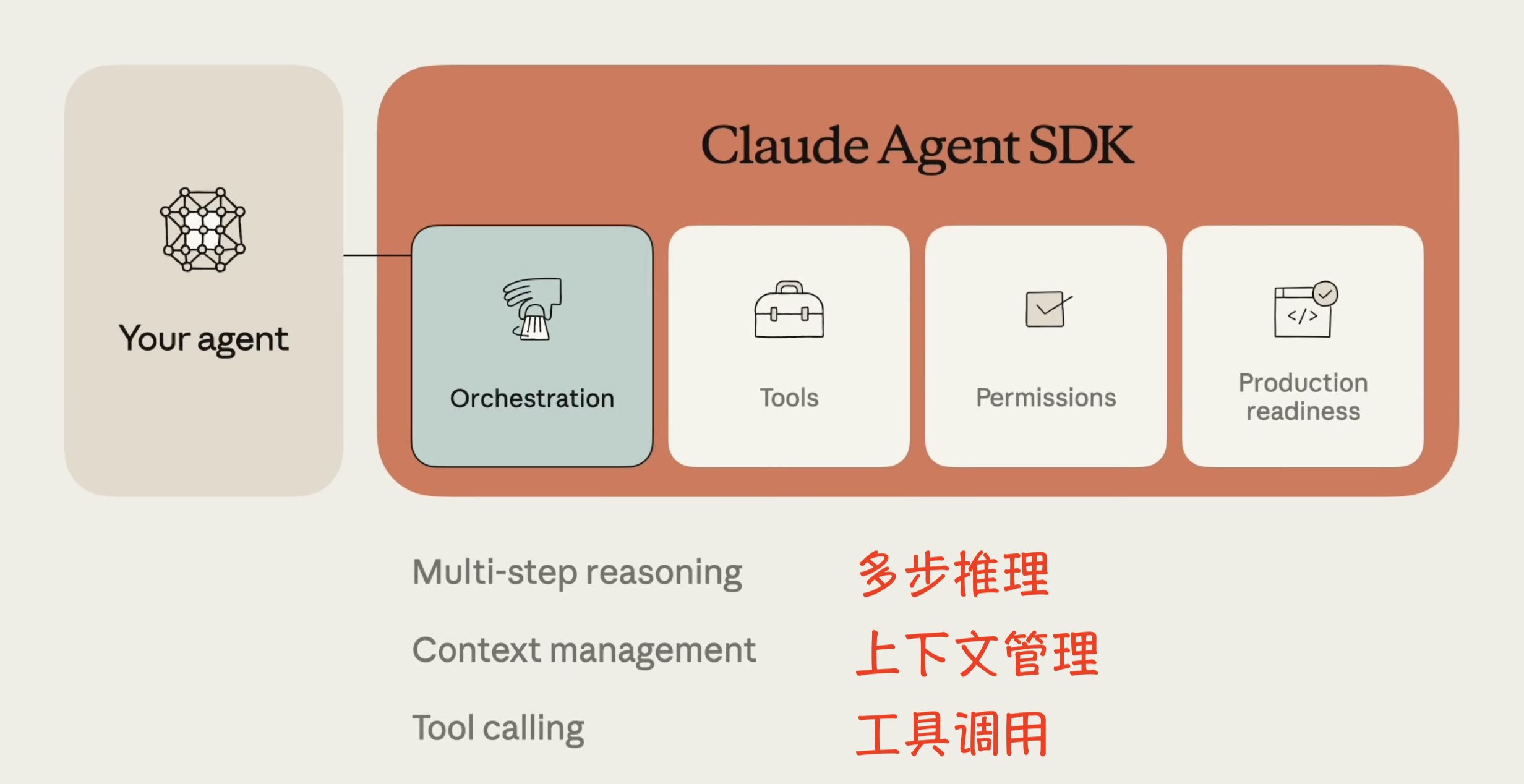
1. 收集上下文(Gather context)
开发智能体时,需要让它能够获取和更新自己的上下文。SDK 提供了以下功能:
- 智能搜索与文件系统(Agentic search and the file system): 文件系统代表了可以被拉入模型上下文的信息。Claude 会利用 bash 脚本(如
grep和tail)来决定如何加载大型文件(如日志或用户上传的文件)。文件和文件夹结构本身构成了一种上下文工程形式。 - 语义搜索(Semantic search): 通常比智能搜索快,但准确性较低、维护难度大且透明度不足。建议仅在需要更快结果或更多变体时才考虑添加。
- 子智能体(Subagents): 默认支持。它们用于实现并行化(同时处理不同任务)和上下文管理(子智能体使用隔离的上下文窗口,只将相关信息而非全部上下文发送给协调器)。这使得它们非常适合需要筛选大量信息的任务。
- 压缩(Compaction): 当上下文限制临近时,Claude Agent SDK 的压缩功能会自动总结先前的消息,以防止智能体耗尽上下文。
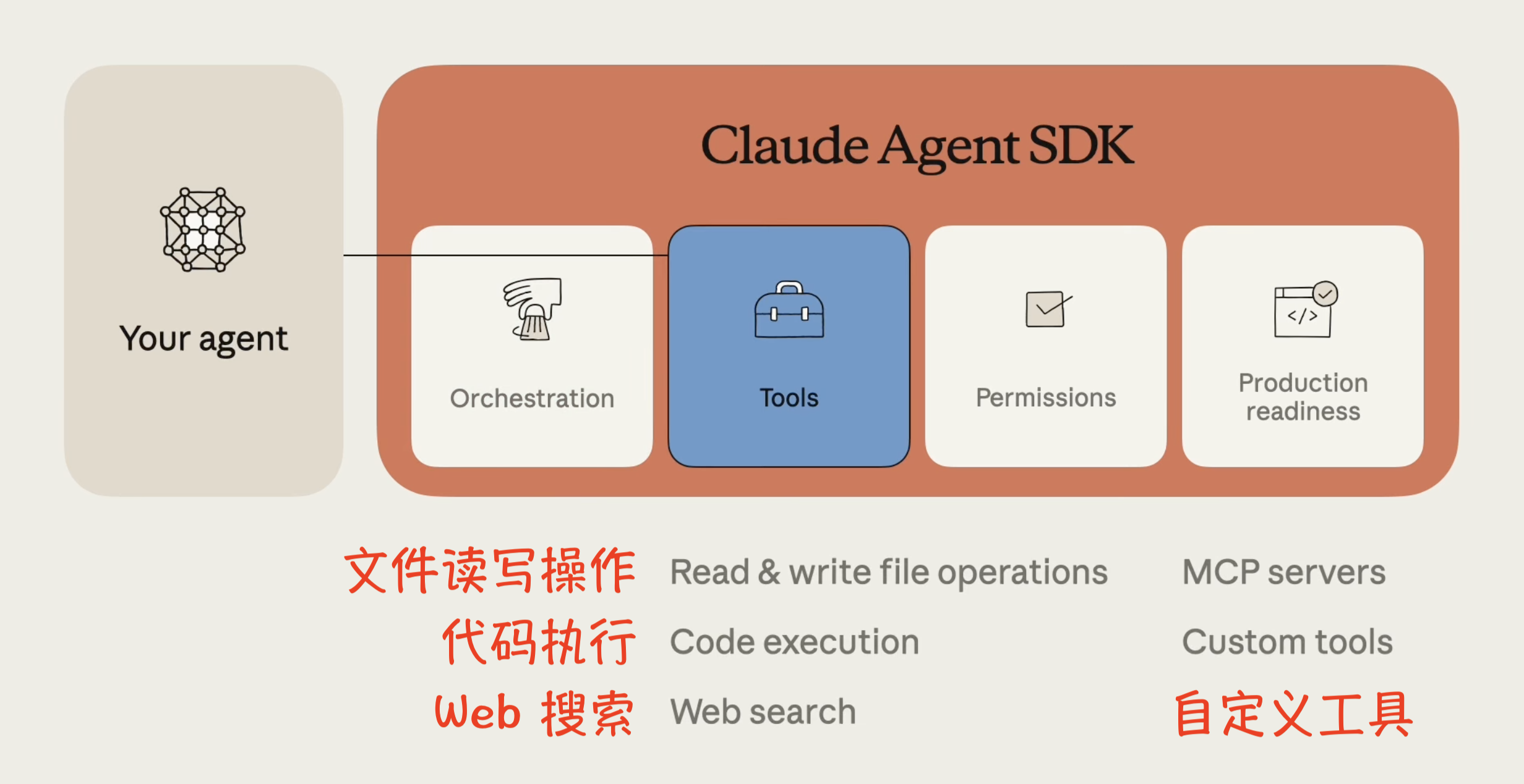
2. 采取行动(Take action)
收集上下文后,需要为智能体提供灵活的执行方式:
- 工具(Tools): 是智能体执行的主要构建块,也是 Claude 决定如何完成任务时考虑的主要动作。设计工具时应注重最大化上下文效率,使其成为智能体最主要的、最频繁的行动。
- Bash 和脚本(Bash & scripts): 作为通用工具,允许智能体利用计算机进行灵活的工作。
- 代码生成(Code generation): Claude Agent SDK 擅长此项。代码是精确的、可组合的且无限可重用,使其成为需要可靠执行复杂操作的智能体的理想输出。例如,Claude 通过编写 Python 脚本来创建 Excel、PPT 或 Word 文档,以确保一致的格式和复杂功能。
- MCP(Model Context Protocol): 提供标准化集成,自动处理身份验证和 API 调用,从而将智能体连接到 Slack、GitHub、Google Drive 或 Asana 等外部服务,无需编写自定义集成代码。智能体可以直接调用预构建的工具(如
search_slack_messages),MCP 会处理其余部分。
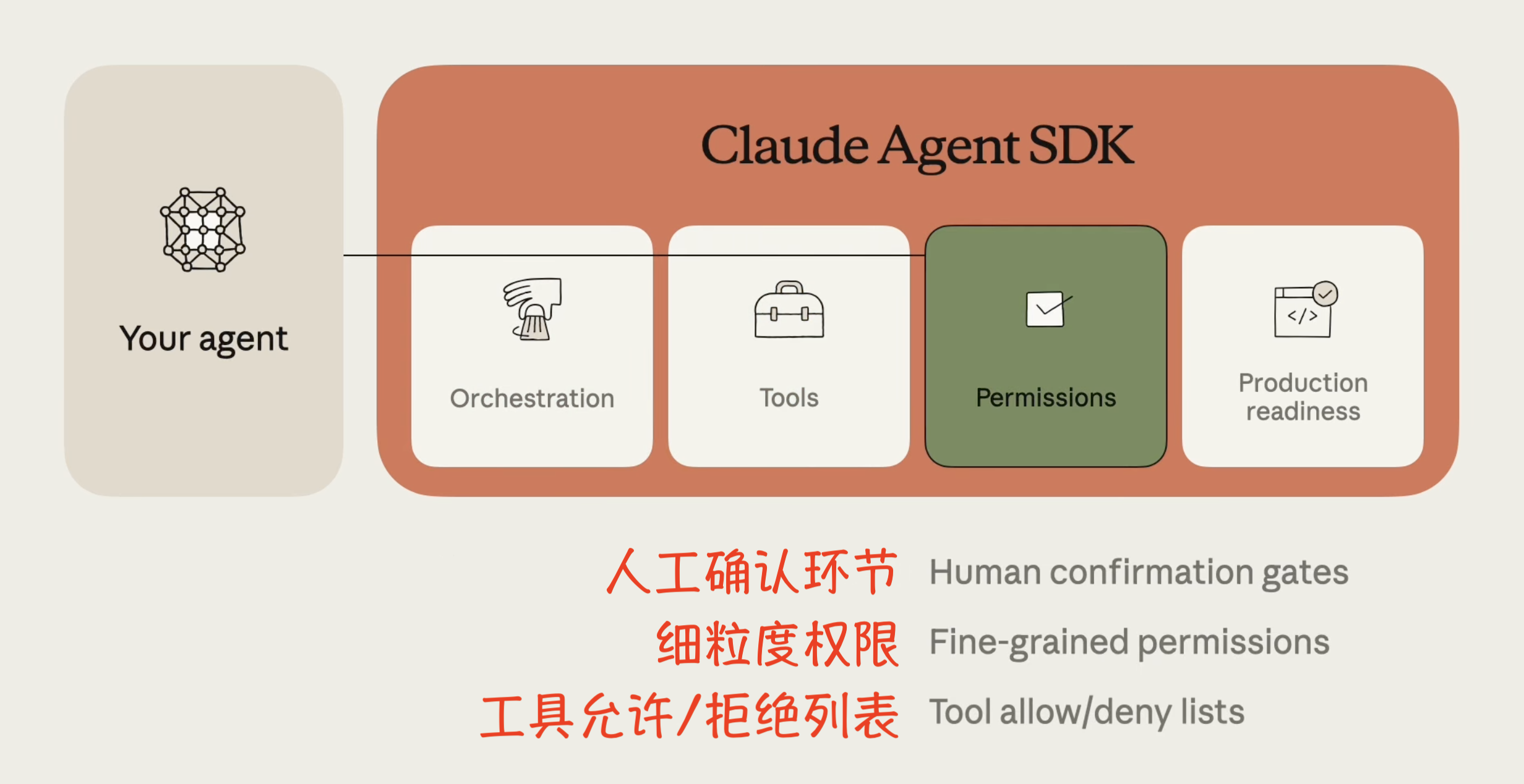
3. 验证工作(Verify your work)
能够检查并改进自身输出的智能体更加可靠,因为它们能在错误复合前捕捉错误、在偏离时自我纠正,并在迭代中改进。关键是提供具体的评估方式:
- 定义规则(Defining rules): 最佳的反馈形式是为输出提供明确定义的规则,并解释哪些规则失败以及原因。代码 Linting 是一种优秀的基于规则的反馈机制。
- 视觉反馈(Visual feedback): 用于完成视觉任务(如 UI 生成或测试)。通过截图或渲染形式提供反馈,模型会检查视觉输出是否与请求匹配,包括布局、样式和内容层次结构等。可以使用 Playwright 等 MCP 服务器自动化此视觉反馈循环。
- LLM 作为评判者(LLM as a judge): 让另一个语言模型根据模糊规则来“评判”智能体的输出。虽然这种方法通常不够稳健,并可能带来高延迟权衡,但对于追求任何性能提升的应用来说可能有用。
四、测试和改进
为了改进智能体,建议仔细查看其输出,特别是失败案例,并思考它是否拥有正确的工具来完成任务。评估时需要问的关键问题包括:
- 如果智能体误解了任务,是否可以更改搜索 API 的结构使其更容易找到所需信息?
- 如果智能体重复失败,是否可以在工具调用中添加正式规则来识别和修复故障?
- 如果智能体无法修复错误,是否可以提供更有用或更有创意的工具来采用不同的方法解决问题?
- 如果智能体的性能随着功能增加而变化,应基于客户使用情况建立代表性测试集进行程序化评估。
Building agents with the Claude Agent SDK
上下文编辑

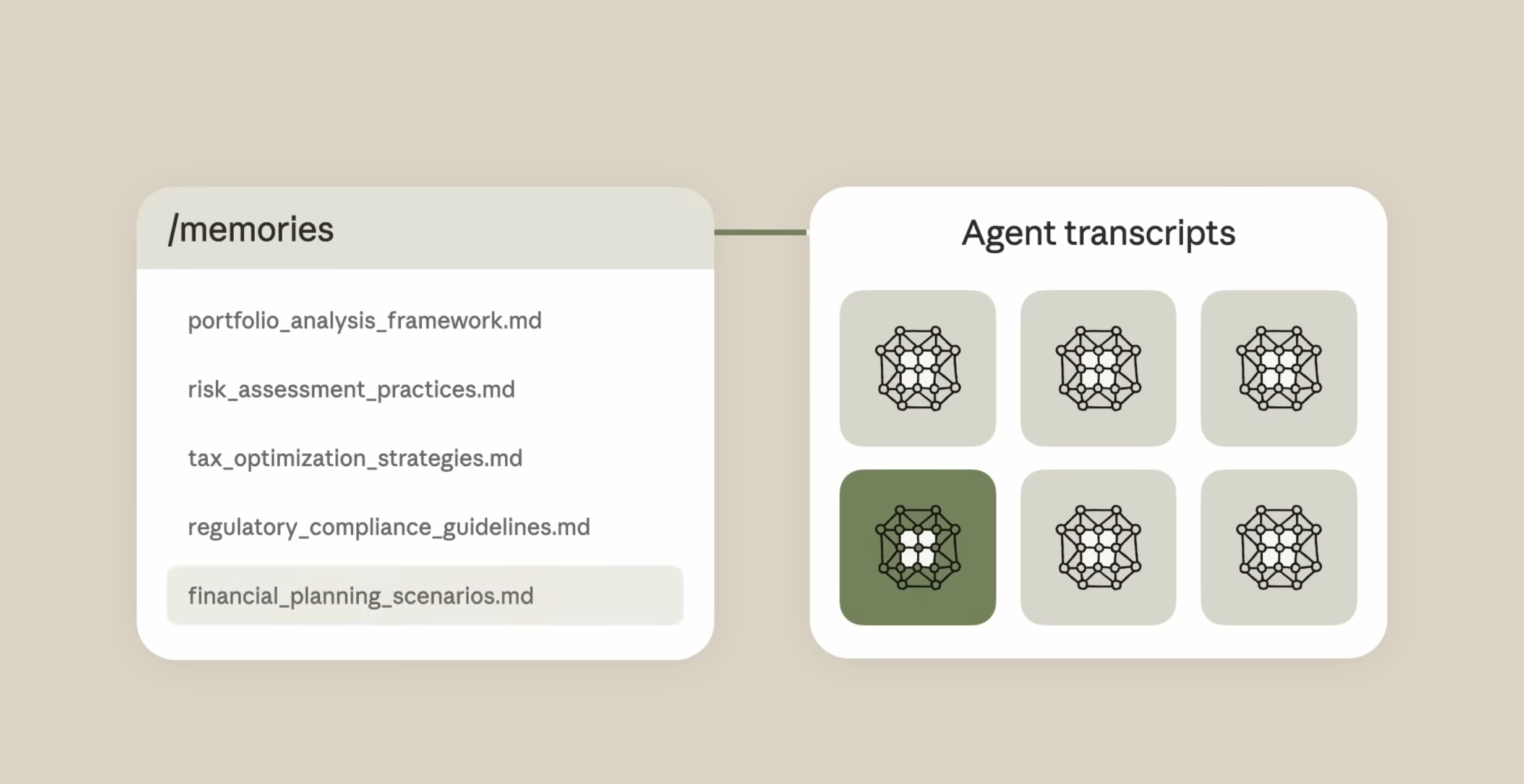
记忆存储
玩游戏