SenseVoice
SenseVoice 是具有音频理解能力的音频基础模型,包括语音识别(ASR)、语种识别(LID)、语音情感识别(SER)和声学事件分类(AEC)或声学事件检测(AED)。
SenseVoice
核心功能 🎯
SenseVoice 专注于高精度多语言语音识别、情感辨识和音频事件检测
- 多语言识别: 采用超过 40 万小时数据训练,支持超过 50 种语言,识别效果上优于 Whisper 模型。
- 富文本识别:
- 具备优秀的情感识别,能够在测试数据上达到和超过目前最佳情感识别模型的效果。
- 支持声音事件检测能力,支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件进行检测。
- 高效推理: SenseVoice-Small 模型采用非自回归端到端框架,推理延迟极低,10s 音频推理仅耗时 70ms,15 倍优于 Whisper-Large。
- 微调定制: 具备便捷的微调脚本与策略,方便用户根据业务场景修复长尾样本问题。
- 服务部署: 具有完整的服务部署链路,支持多并发请求,支持客户端语言有,python、c++、html、java 与 c# 等。
架构图
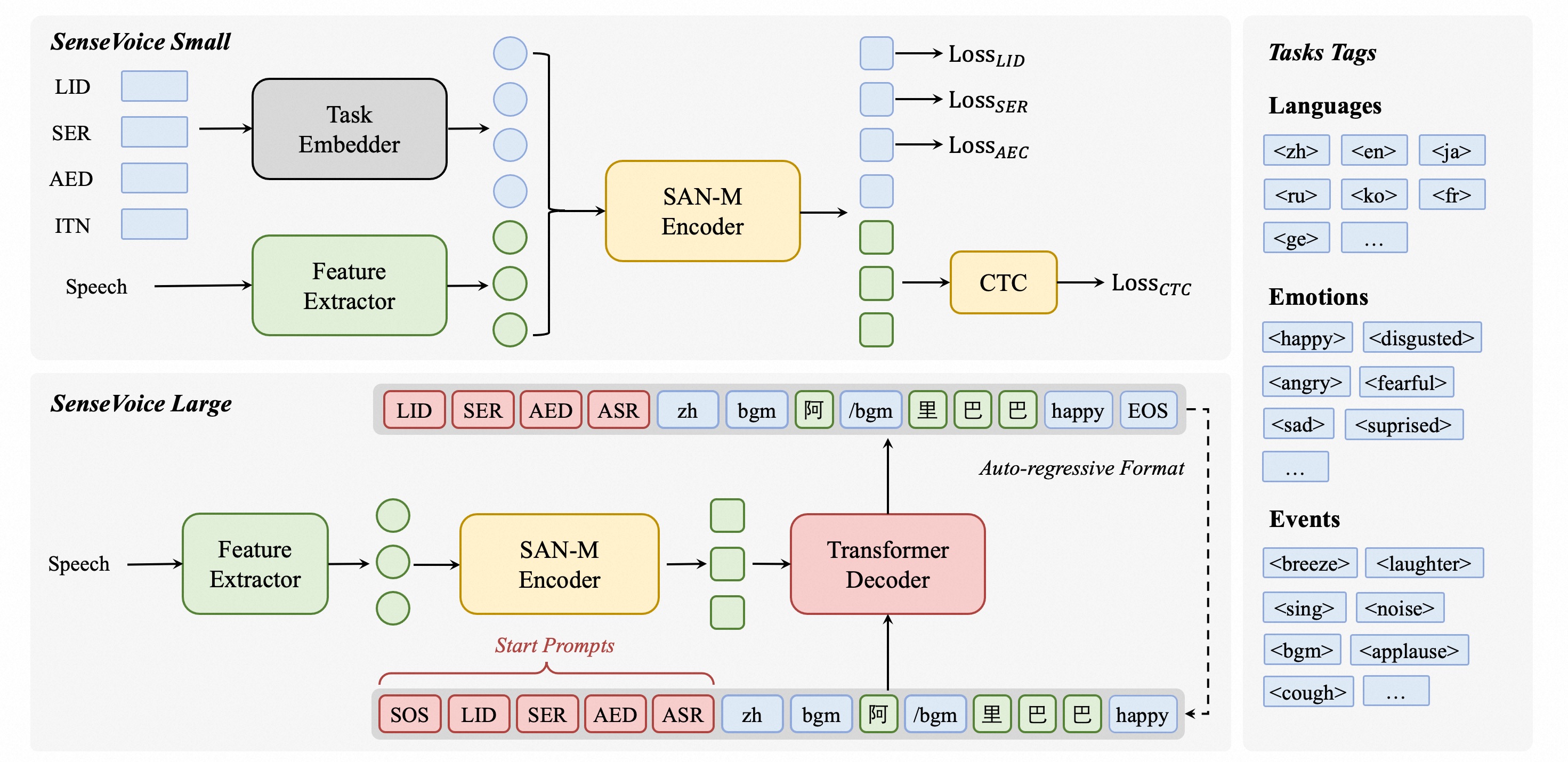
- 语音识别(ASR)
- 语言识别(LID)
- 语音情感识别(SER)
- 音频事件检测(AED,比如笑声、掌声、背景音乐、咳嗽等)
- 逆文本归一化(ITN)
安装
克隆代码库
git clone https://github.com/FunAudioLLM/SenseVoice
cd SenseVoice
创建并激活 Conda 环境
# ❌ conda create -n funasr python=3.13.0 -y
conda create -n funasr python=3.10.9 -y
conda activate funasr
| Python 版本 | PyTorch 支持 |
|---|---|
| 3.10 | 支持 |
| 3.11 | 支持 |
| 3.12 | 刚开始支持(部分) |
| 3.13 | ❌ 目前不支持 |
安装依赖
pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install gradio "fastapi[standard]" funasr_onnx \
-i https://pypi.tuna.tsinghua.edu.cn/simple
运行
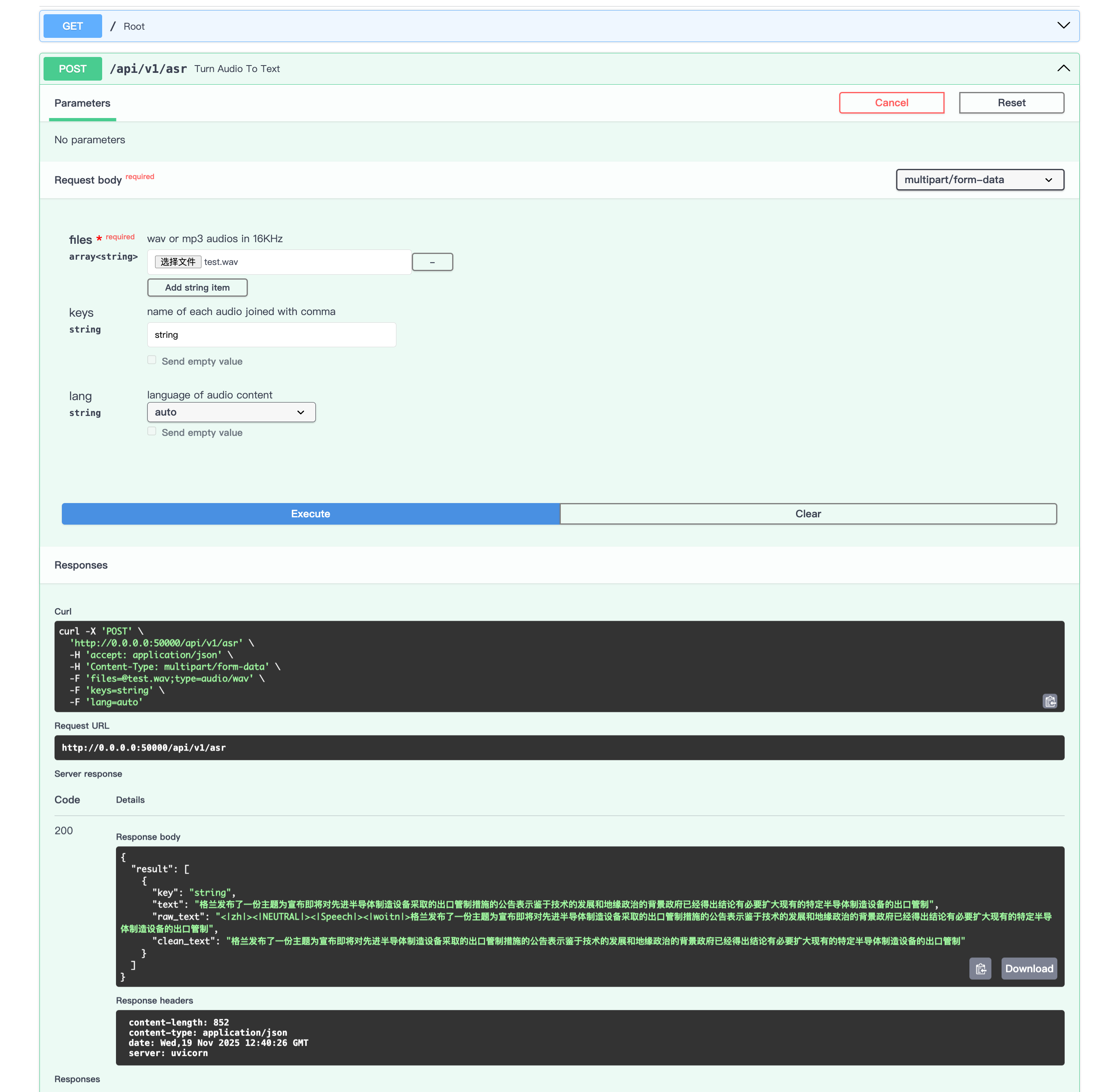
运行 API 服务
# macOS Silicon
export SENSEVOICE_DEVICE=mps
fastapi run --port 50000
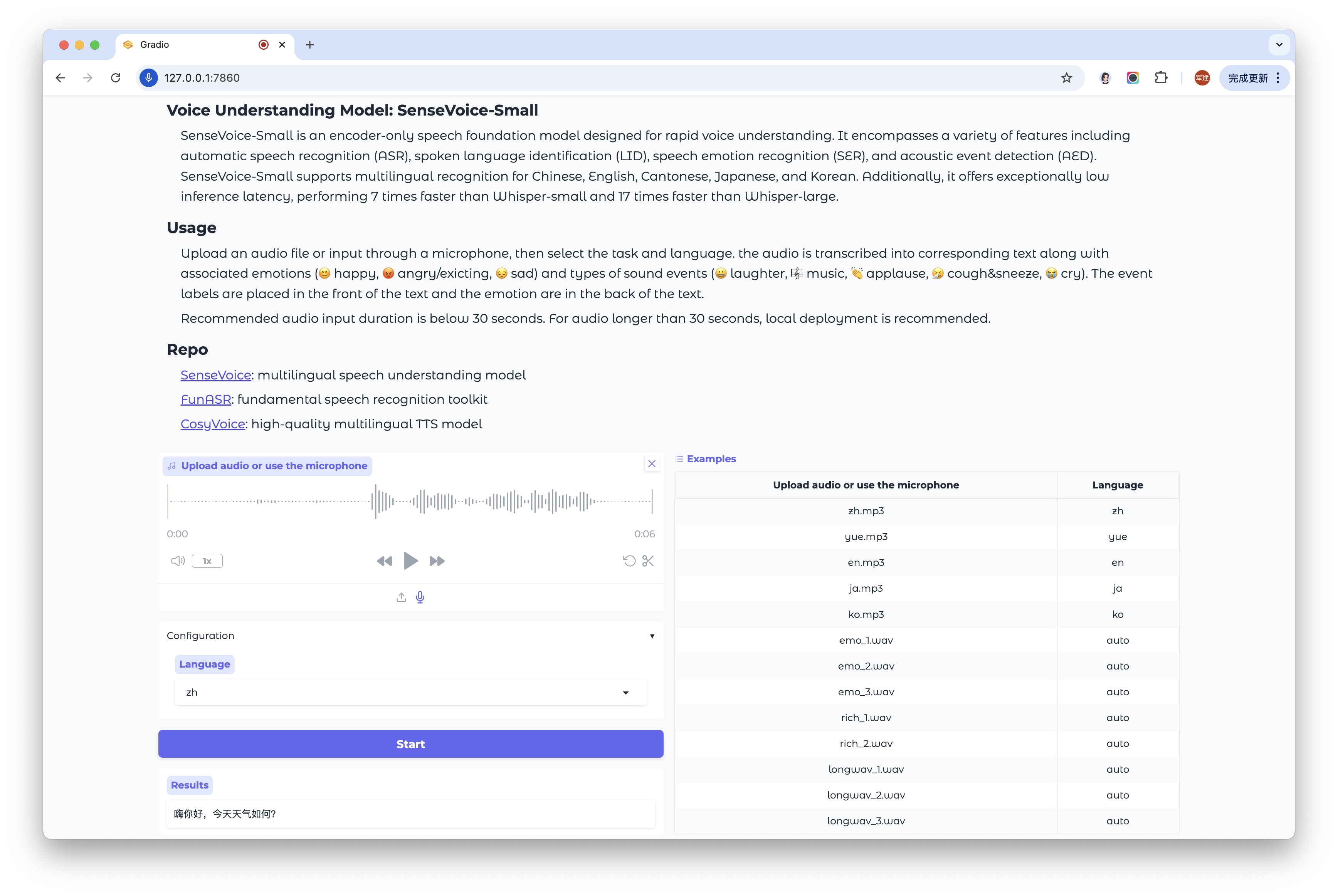
运行 WebUI
python webui.py
You are using the latest version of funasr-1.2.7
Downloading Model from https://www.modelscope.cn to directory: /Users/junjian/.cache/modelscope/hub/models/iic/SenseVoiceSmall
Loading remote code successfully: model
Downloading Model from https://www.modelscope.cn to directory: /Users/junjian/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch
* Running on local URL: http://127.0.0.1:7860
* To create a public link, set `share=True` in `launch()`.
audio_fs: 44100
language: zh, merge_vad: True
rtf_avg: 0.009: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 20.79it/s]
rtf_avg: 0.125: 100%|█████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.45it/s]
rtf_avg: 0.125, time_speech: 5.520, time_escape: 0.692: 100%|████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.44it/s]
[{'key': 'rand_key_W4Acq9GFz6Y1t', 'text': '<|zh|><|NEUTRAL|><|Speech|><|withitn|>嗨你好,今天天气如何?'}]
嗨你好,今天天气如何?
推理
| 引擎 | 设备 | 用时 (s) | 音频时长 (s) |
|---|---|---|---|
| funasr 🚀 | mps | 0.47 | 72 |
| cpu | 1.7 | 72 | |
| directly | mps | 0.58 | 72 |
| cpu | 1.82 | 72 | |
| onnx | cpu | 4 | 72 |
| onnx(quantize) | cpu | 2.5 | 72 |
ℹ安装 onnxruntime-silicon 没有成功使用,所以没有测试 mps。
funasr 推理
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
remote_code="./model.py",
device="mps",
)
# ----------- 测试 E2E 推理时间 -----------
wav = "wav/all2.wav"
# 计算音频时长
import soundfile as sf
audio, sr = sf.read(wav)
audio_dur = len(audio) / sr
import time
t0 = time.perf_counter()
res = model.generate(
input=wav,
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
)
t1 = time.perf_counter()
e2e_time = t1 - t0
rtf = e2e_time / audio_dur
print("----- ASR Benchmark -----")
print(f"Audio duration: {audio_dur:.3f} s")
print(f"🚀🚀🚀 E2E inference time: {e2e_time:.3f} s")
print(f"RTF: {rtf:.4f}")
text = rich_transcription_postprocess(res[0]["text"])
print(text)
直接推理
from model import SenseVoiceSmall
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
m, kwargs = SenseVoiceSmall.from_pretrained(model=model_dir, device="mps")
m.eval()
# ----------- 测试 E2E 推理时间 -----------
wav = "wav/all2.wav"
# 计算音频时长
import soundfile as sf
audio, sr = sf.read(wav)
audio_dur = len(audio) / sr
import time
t0 = time.perf_counter()
res = m.inference(
data_in=wav,
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=False,
ban_emo_unk=False,
**kwargs,
)
t1 = time.perf_counter()
e2e_time = t1 - t0
rtf = e2e_time / audio_dur
print("----- ASR Benchmark -----")
print(f"Audio duration: {audio_dur:.3f} s")
print(f"🚀🚀🚀 E2E inference time: {e2e_time:.3f} s")
print(f"RTF: {rtf:.4f}")
text = rich_transcription_postprocess(res [0][0]["text"])
print(text)
ONNX 推理
from pathlib import Path
from funasr_onnx import SenseVoiceSmall
from funasr_onnx.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = SenseVoiceSmall(model_dir, batch_size=10, quantize=True, device="cpu")
# ----------- 测试 E2E 推理时间 -----------
wav = "wav/all2.wav"
# 计算音频时长
import soundfile as sf
audio, sr = sf.read(wav)
audio_dur = len(audio) / sr
import time
t0 = time.perf_counter()
res = model(wav, language="auto", use_itn=True)
t1 = time.perf_counter()
e2e_time = t1 - t0
rtf = e2e_time / audio_dur
print("----- ASR Benchmark -----")
print(f"Audio duration: {audio_dur:.3f} s")
print(f"🚀🚀🚀 E2E inference time: {e2e_time:.3f} s")
print(f"RTF: {rtf:.4f}")
print([rich_transcription_postprocess(i) for i in res])
Libtorch 推理
❌ 使用
pip install funasr_torch安装后,并没有真正安装成功,可以考虑使用源码方式安装。
from pathlib import Path
from funasr_torch import SenseVoiceSmall
from funasr_torch.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "iic/SenseVoiceSmall"
model = SenseVoiceSmall(model_dir, batch_size=10, device="mps")
# ----------- 测试 E2E 推理时间 -----------
wav = "wav/all2.wav"
# 计算音频时长
import soundfile as sf
audio, sr = sf.read(wav)
audio_dur = len(audio) / sr
import time
t0 = time.perf_counter()
res = model(wav, language="auto", use_itn=True)
t1 = time.perf_counter()
e2e_time = t1 - t0
rtf = e2e_time / audio_dur
print("----- ASR Benchmark -----")
print(f"Audio duration: {audio_dur:.3f} s")
print(f"🚀🚀🚀 E2E inference time: {e2e_time:.3f} s")
print(f"RTF: {rtf:.4f}")
print([rich_transcription_postprocess(i) for i in res])
混合 VAD 推理(离线)
from funasr import AutoModel
from funasr.utils.postprocess_utils import rich_transcription_postprocess
model_dir = "/Users/junjian/.cache/modelscope/hub/models/iic/SenseVoiceSmall"
vad_model_dir = "/Users/junjian/.cache/modelscope/hub/models/iic/speech_fsmn_vad_zh-cn-16k-common-pytorch"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
remote_code="./model.py",
vad_model=vad_model_dir,
vad_kwargs={"max_single_segment_time": 30000},
device="mps",
disable_update=True
)
res = model.generate(
input=f"wav/all2.wav",
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True,
merge_length_s=15,
)
text = rich_transcription_postprocess(res[0]["text"])
print(text)