本文将介绍如何在 Jetson Thor 平台上编译、部署和测试 llama.cpp 项目中的 GGUF 格式的大模型。
git clone https://github.com/ggml-org/llama.cpp.git
cd llama.cpp
计算能力(CC)定义了每种 NVIDIA GPU 架构的硬件特性和支持的指令。在下表中查找您的GPU的计算能力。
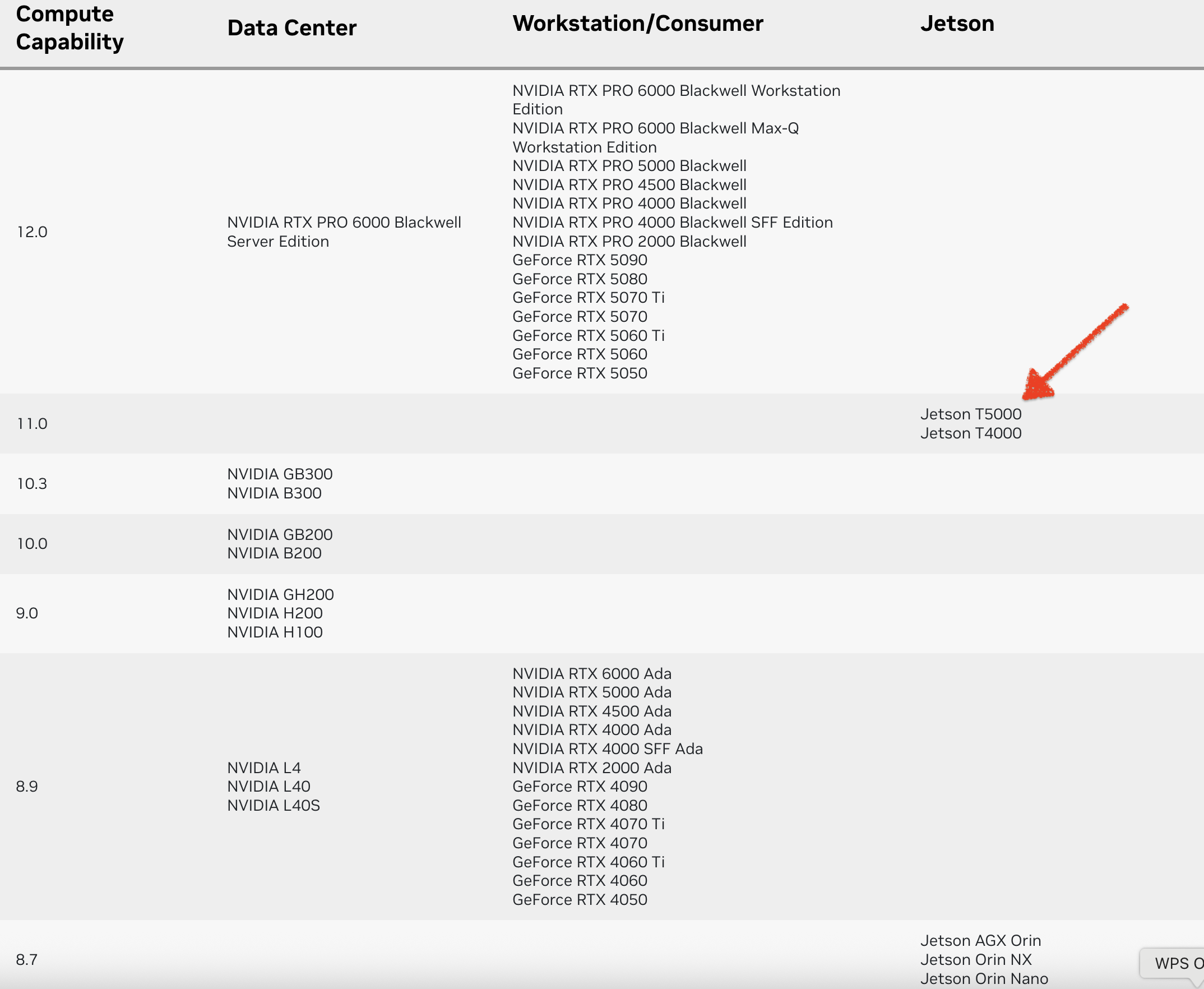
编译
cmake -B build -DGGML_CUDA=ON -DCMAKE_CUDA_ARCHITECTURES="110"
cmake --build build --config Release -j $(nproc)
模型部署
运行 llama-server
./build/bin/llama-server \
--model /models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q5_K_M.gguf \
--alias qwen3 \
--host 0.0.0.0 \
--port 8000 \
--reasoning-budget 0 \
--gpu-layers -1 \
--ctx-size 0 \
--parallel $(nproc) \
--threads $(nproc) \
--flash-attn on \
--no-kv-offload \
--no-op-offload \
--no-mmap \
--mlock
./build/bin/llama-server \
--model /models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf \
--alias qwen3 \
--host 0.0.0.0 \
--port 8000 \
--jinja \
--reasoning-format none \
--gpu-layers -1 \
--ctx-size 0 \
--parallel $(nproc) \
--threads $(nproc) \
--flash-attn on \
--no-kv-offload \
--no-op-offload \
--no-mmap \
--mlock
./build/bin/llama-server \
--model /models/ggml-org/gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00001-of-00003.gguf \
--alias qwen3 \
--host 0.0.0.0 \
--port 8000 \
--jinja \
--gpu-layers -1 \
--ctx-size 0 \
--parallel $(nproc) \
--threads $(nproc) \
--flash-attn on \
--no-kv-offload \
--no-op-offload \
--no-mmap \
--mlock
llama-server 命令行参数解释
模型路径与别名设置
.llama-server
- 这是
llama.cpp 项目中用于启动 REST API 服务的可执行文件 [i]。
--model /models/ggml-org/gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00001-of-00003.gguf
- 使用此选项(
-m, --model FNAME)指定要加载的模型文件的路径。
--alias qwen3
- 使用此选项(
-a, --alias STRING)为模型名称设置别名,该别名将用于 REST API。
服务配置
--host 0.0.0.0
- 指定服务器要监听的 IP 地址。默认是
127.0.0.1。
--port 8000
--jinja
- 启用此标志,在聊天中将使用 Jinja 模板。默认情况下,此功能是禁用的。
--reasoning-format none
- 此选项(
-rf, --reasoning-format FORMAT)用于控制是否允许以及如何从模型的响应中提取“思维标签”。
- 当将此参数设置为 none 时,模型生成的思维内容(thoughts)将保持未解析状态,并保留在 message.content 字段中。 默认值是
none。
--reasoning-budget 0
- 当设置为
0 时,思维内容(thoughts)将被禁用。默认值是 -1。
资源与并发控制
--gpu-layers -1
- 此选项(
-ngl, --gpu-layers, --n-gpu-layers N)设置存储在 VRAM 中的最大层数。
- 设置为
-1 通常意味着尝试将所有可能的层加载到 VRAM 中。
--ctx-size 0
- 此选项(
-c, --ctx-size N)设置提示上下文的大小。
- 当设置为
0 时,上下文大小将从模型中加载。默认值是 4096。
--parallel $(nproc)
- 此选项(
-np, --parallel N)设置并行解码的序列数量。
$(nproc) 是一个 shell 命令,表示将并行序列数设置为系统可用的处理器核心数。默认值是 1。
--threads $(nproc)
- 此选项(
-t, --threads N)设置在生成过程中使用的线程数量。
$(nproc) 意味着将线程数设置为系统可用的处理器核心数。
性能优化与内存管理
--flash-attn on
- 此选项(
-fa, --flash-attn [on|off|auto])设置 Flash Attention 的使用。
- 在此配置中,它被显式设置为“开启”(
on)。
--no-kv-offload
- 此选项(
-nkvo, --no-kv-offload)用于禁用 KV (Key/Value) 卸载。
--no-op-offload
- 此选项用于禁用将主机张量操作卸载到设备(默认值为
false)。
--no-mmap
- 此选项用于不进行内存映射模型。这会导致加载速度变慢,但如果未使用
mlock,则可能减少换页。
--mlock
- 此选项用于强制系统将模型保留在 RAM 中,而不是进行交换或压缩。
编写脚本 llama-server.sh
vim /models/llama.cpp/llama-server.sh
#!/bin/bash
# 默认配置
DEFAULT_MODEL="/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf"
DEFAULT_HOST="0.0.0.0"
DEFAULT_PORT="8000"
DEFAULT_PARALLEL=$(nproc)
DEFAULT_THREADS=$(nproc)
# 函数:列出所有 gguf 模型
list_gguf_models() {
echo "找到的 GGUF 模型文件:"
echo "================================================"
find /models/ -name "*.gguf" -not -path "/models/llama.cpp/*" 2>/dev/null | sort
echo "================================================"
echo "总计: $(find /models/ -name "*.gguf" -not -path "/models/llama.cpp/*" 2>/dev/null | wc -l) 个模型文件"
}
# 函数:显示帮助信息
show_help() {
echo "使用方法: $0 [选项]"
echo "选项:"
echo " -l, --list 列出所有 GGUF 模型(排除 /models/llama.cpp 目录)"
echo " -m, --model MODEL_PATH 指定模型路径"
echo " -H, --host HOST 指定主机地址 (默认: $DEFAULT_HOST)"
echo " -p, --port PORT 指定端口 (默认: $DEFAULT_PORT)"
echo " -P, --parallel PARALLEL 并行数 (默认: $(nproc))"
echo " -t, --threads THREADS 线程数 (默认: $(nproc))"
echo " -h, --help 显示帮助信息"
}
# 解析命令行参数
SHOW_LIST=false
MODEL_PATH=""
HOST=""
PORT=""
PARALLEL=""
THREADS=""
while [[ $# -gt 0 ]]; do
case $1 in
-l|--list)
SHOW_LIST=true
shift
;;
-m|--model)
MODEL_PATH="$2"
shift 2
;;
-H|--host)
HOST="$2"
shift 2
;;
-p|--port)
PORT="$2"
shift 2
;;
-P|--parallel)
PARALLEL="$2"
shift 2
;;
-t|--threads)
THREADS="$2"
shift 2
;;
-h|--help)
show_help
exit 0
;;
*)
echo "未知参数: $1"
show_help
exit 1
;;
esac
done
# 如果指定了 --list,只列出模型并退出
if [ "$SHOW_LIST" = true ]; then
list_gguf_models
exit 0
fi
# 设置默认值
MODEL_PATH="${MODEL_PATH:-$DEFAULT_MODEL}"
HOST="${HOST:-$DEFAULT_HOST}"
PORT="${PORT:-$DEFAULT_PORT}"
PARALLEL="${PARALLEL:-$DEFAULT_PARALLEL}"
THREADS="${THREADS:-$DEFAULT_THREADS}"
# 检查模型文件是否存在
if [ ! -f "$MODEL_PATH" ]; then
echo "错误: 模型文件不存在 - $MODEL_PATH"
echo "使用 -l 参数查看可用模型:"
echo " $0 -l"
exit 1
fi
echo "启动 llama-server..."
echo "模型路径: $MODEL_PATH"
echo "主机地址: $HOST"
echo "端口: $PORT"
echo "并行数: $PARALLEL"
echo "线程数: $THREADS"
# 运行 llama-server 命令
./build/bin/llama-server \
--model "$MODEL_PATH" \
--alias qwen3 \
--host "$HOST" \
--port "$PORT" \
--jinja \
--reasoning-budget 0 \
--reasoning-format none \
--gpu-layers -1 \
--ctx-size 0 \
--parallel "$PARALLEL" \
--threads "$THREADS" \
--flash-attn on \
--no-kv-offload \
--no-op-offload \
--no-mmap \
--mlock
使用方法: ./llama-server.sh [选项]
选项:
-l, --list 列出所有 GGUF 模型(排除 /models/llama.cpp 目录)
-m, --model MODEL_PATH 指定模型路径
-H, --host HOST 指定主机地址 (默认: 0.0.0.0)
-p, --port PORT 指定端口 (默认: 8000)
-P, --parallel PARALLEL 并行数 (默认: 14)
-t, --threads THREADS 线程数 (默认: 14)
-h, --help 显示帮助信息
找到的 GGUF 模型文件:
================================================
/models/ggml-org/gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00001-of-00003.gguf
/models/ggml-org/gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00002-of-00003.gguf
/models/ggml-org/gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00003-of-00003.gguf
/models/Qwen/Qwen3-30B-A3B-GGUF/Qwen3-30B-A3B-Q5_K_M.gguf
/models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q4_K_M.gguf
/models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q5_0.gguf
/models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q5_K_M.gguf
/models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q6_K.gguf
/models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q8_0.gguf
/models/Qwen/Qwen3-Embedding-4B-GGUF/Qwen3-Embedding-4B-f16.gguf
/models/Qwen/Qwen3-Embedding-4B-GGUF/Qwen3-Embedding-4B-Q4_K_M.gguf
/models/Qwen/Qwen3-Embedding-4B-GGUF/Qwen3-Embedding-4B-Q5_0.gguf
/models/Qwen/Qwen3-Embedding-4B-GGUF/Qwen3-Embedding-4B-Q5_K_M.gguf
/models/Qwen/Qwen3-Embedding-4B-GGUF/Qwen3-Embedding-4B-Q6_K.gguf
/models/Qwen/Qwen3-Embedding-4B-GGUF/Qwen3-Embedding-4B-Q8_0.gguf
/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf
/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf
/models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q6_K.gguf
/models/yairpatch/Qwen3-VL-30B-A3B-Instruct-GGUF/Qwen3-VL-30B-A3B-Instruct-Q5_K_M.gguf
================================================
总计: 19 个模型文件
性能测试
模型性能分析
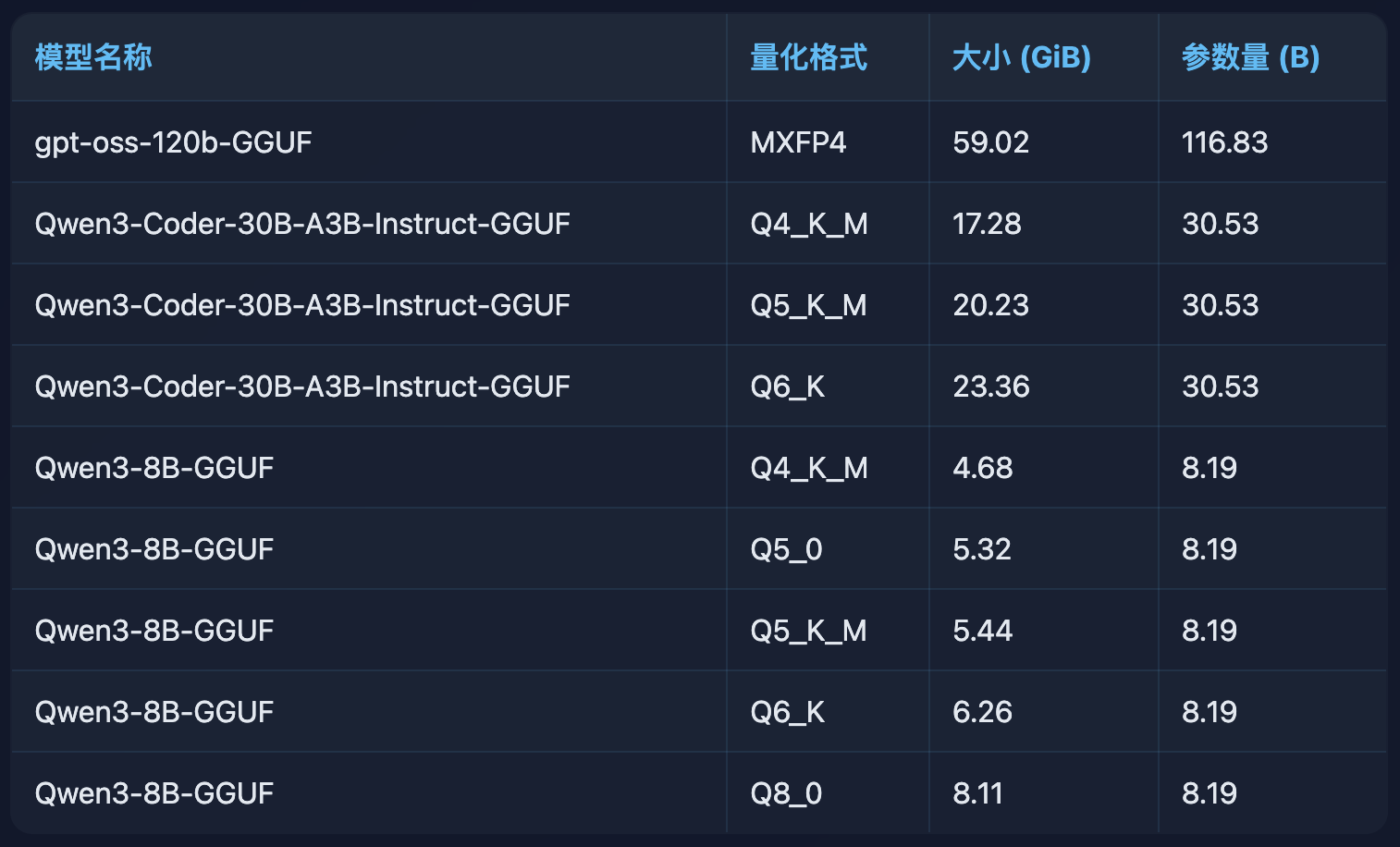
模型规格对比
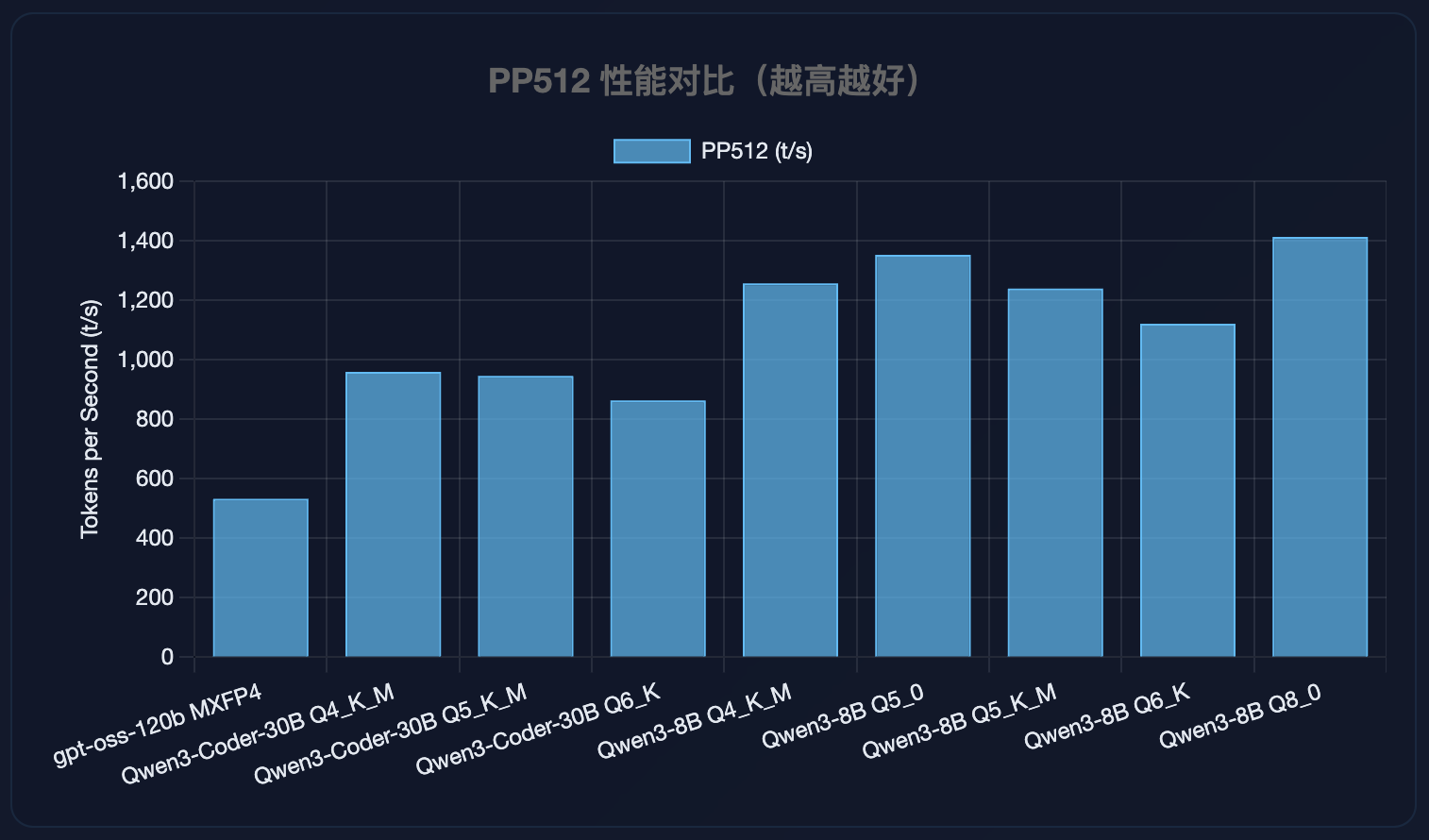
PP512 性能对比
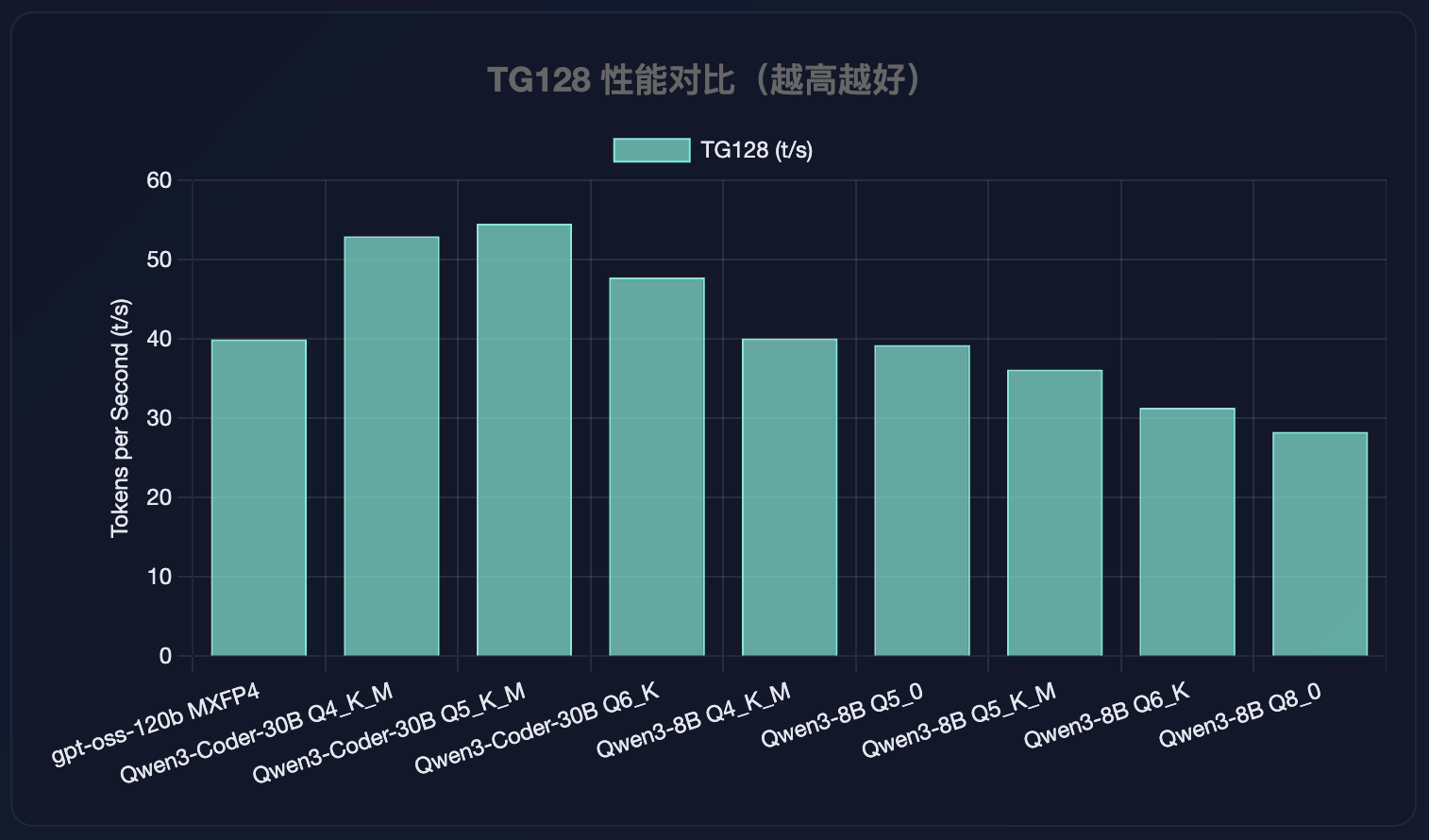
TG128 性能对比
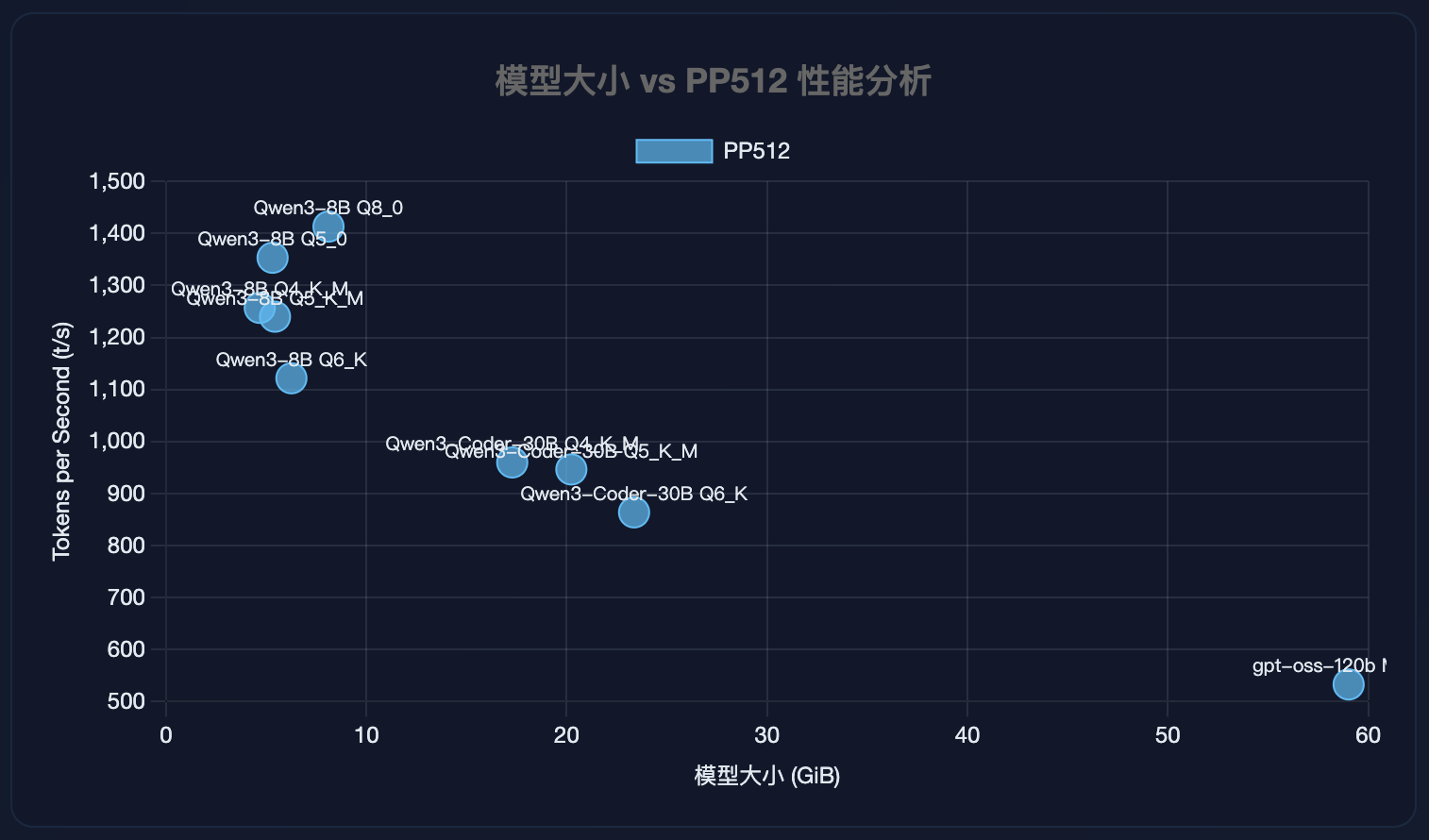
模型大小 vs PP512 性能分析
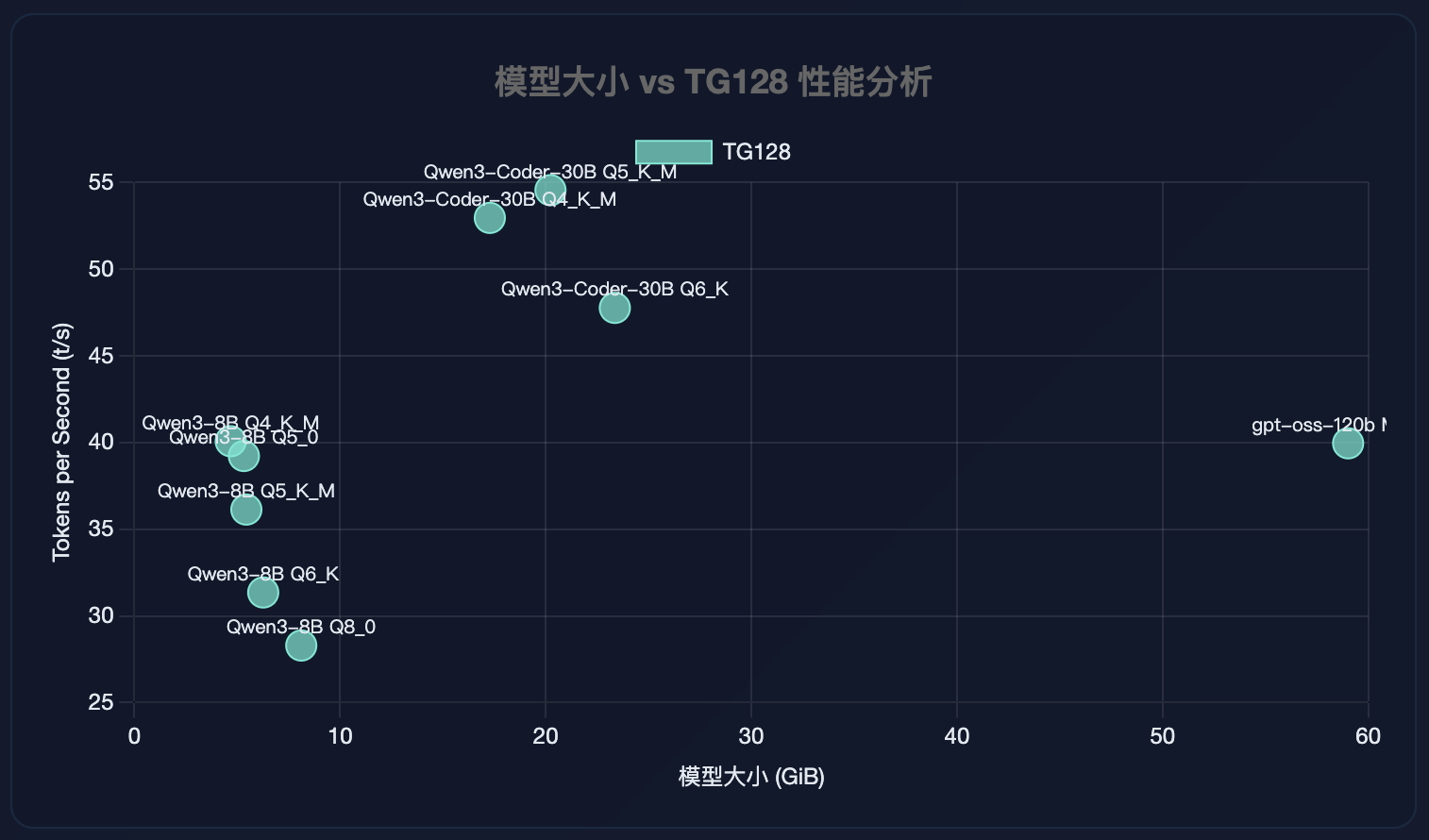
模型大小 vs TG128 性能分析
gpt-oss-120b-GGUF
./build/bin/llama-bench -m /models/ggml-org/gpt-oss-120b-GGUF/gpt-oss-120b-mxfp4-00001-of-00003.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| gpt-oss 120B MXFP4 MoE |
59.02 GiB |
116.83 B |
CUDA |
99 |
pp512 |
533.06 ± 7.20 |
| gpt-oss 120B MXFP4 MoE |
59.02 GiB |
116.83 B |
CUDA |
99 |
tg128 |
39.95 ± 0.03 |
Qwen3-Coder-30B-A3B-Instruct-GGUF
./build/bin/llama-bench -m /models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q4_K_M.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| qwen3moe 30B.A3B Q4_K - Medium |
17.28 GiB |
30.53 B |
CUDA |
99 |
pp512 |
959.77 ± 7.22 |
| qwen3moe 30B.A3B Q4_K - Medium |
17.28 GiB |
30.53 B |
CUDA |
99 |
tg128 |
52.95 ± 0.08 |
./build/bin/llama-bench -m /models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q5_K_M.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| qwen3moe 30B.A3B Q5_K - Medium |
20.23 GiB |
30.53 B |
CUDA |
99 |
pp512 |
946.36 ± 4.90 |
| qwen3moe 30B.A3B Q5_K - Medium |
20.23 GiB |
30.53 B |
CUDA |
99 |
tg128 |
54.55 ± 0.08 |
./build/bin/llama-bench -m /models/unsloth/Qwen3-Coder-30B-A3B-Instruct-GGUF/Qwen3-Coder-30B-A3B-Instruct-Q6_K.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| qwen3moe 30B.A3B Q6_K |
23.36 GiB |
30.53 B |
CUDA |
99 |
pp512 |
863.80 ± 5.21 |
| qwen3moe 30B.A3B Q6_K |
23.36 GiB |
30.53 B |
CUDA |
99 |
tg128 |
47.76 ± 0.05 |
Qwen3-8B-GGUF
./build/bin/llama-bench -m /models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q4_K_M.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| qwen3 8B Q4_K - Medium |
4.68 GiB |
8.19 B |
CUDA |
99 |
pp512 |
1256.90 ± 0.40 |
| qwen3 8B Q4_K - Medium |
4.68 GiB |
8.19 B |
CUDA |
99 |
tg128 |
40.07 ± 0.02 |
./build/bin/llama-bench -m /models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q5_0.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| qwen3 8B Q5_0 |
5.32 GiB |
8.19 B |
CUDA |
99 |
pp512 |
1353.25 ± 0.66 |
| qwen3 8B Q5_0 |
5.32 GiB |
8.19 B |
CUDA |
99 |
tg128 |
39.22 ± 0.02 |
./build/bin/llama-bench -m /models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q5_K_M.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| qwen3 8B Q5_K - Medium |
5.44 GiB |
8.19 B |
CUDA |
99 |
pp512 |
1239.98 ± 0.97 |
| qwen3 8B Q5_K - Medium |
5.44 GiB |
8.19 B |
CUDA |
99 |
tg128 |
36.13 ± 0.02 |
./build/bin/llama-bench -m /models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q6_K.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| qwen3 8B Q6_K |
6.26 GiB |
8.19 B |
CUDA |
99 |
pp512 |
1121.56 ± 0.30 |
| qwen3 8B Q6_K |
6.26 GiB |
8.19 B |
CUDA |
99 |
tg128 |
31.35 ± 0.97 |
./build/bin/llama-bench -m /models/Qwen/Qwen3-8B-GGUF/Qwen3-8B-Q8_0.gguf
| model |
size |
params |
backend |
ngl |
test |
t/s |
| qwen3 8B Q8_0 |
8.11 GiB |
8.19 B |
CUDA |
99 |
pp512 |
1413.13 ± 0.80 |
| qwen3 8B Q8_0 |
8.11 GiB |
8.19 B |
CUDA |
99 |
tg128 |
28.29 ± 0.25 |
参考资料