FunASR:多模型协同推理与语音处理全链路实践 (ASR, VAD, PUNC, SV)
本文详细介绍了 FunASR 这一基础语音识别工具包,它提供了一套完整的语音处理服务,涵盖了离线转写和实时听写两大核心功能。其技术核心在于 AutoModel 多模型协调引擎,能够将不同的组件,如语音活动检测(VAD)、自动语音识别(ASR)、标点恢复和说话人分离(SV),按序串联起来,实现复杂的音频转录任务。文档清晰展示了从原始音频输入到最终带说话人标签的转录结果的完整处理流程和数据流向。此外,本文不仅罗列了支持的多种中英文模型清单,还附带了音频格式转换指南和代码示例。最后,通过实验性能对比,文章论证了在不同硬件上,结合 VAD、PUNC 和 SV 等组件后对推理用时和处理准确性的影响。
ASR 模型综合对比表
| 模型名称 | 中文准确度 | 英文/混合识别 | 可读性 (标点) | 附加功能 | 综合评分 |
|---|---|---|---|---|---|
| Fun-ASR-Nano | 极高 | 完美 | 极佳 | 生产环境级别 | 5.0 |
| SenseVoiceSmall | 高 | 较弱 (漏失) | 较好 | 情感/事件检测 | 4.0 |
paraformer-zh (ASR) |
一般 | 极差 | 无 | 原始数据 | 2.0 |
paraformer-zh (+VAD +PUNC) |
高 | 中等 | 优秀 | 自动断句 | 4.5 |
建议:
- 如果你的场景需要极致的准确率和排版,首选 Fun-ASR-Nano。
- 如果你的场景需要分析说话人的情绪,SenseVoiceSmall 是唯一的选择。
- 对于普通的长音频转写,带标点补全的 paraformer-zh 性价比最高。
FunASR
FunASR 是一个基础语音识别工具包,提供多种功能,包括语音识别(ASR)、语音端点检测(VAD)、标点恢复、语言模型、说话人验证、说话人分离和多人对话语音识别等。
离线文件转写服务
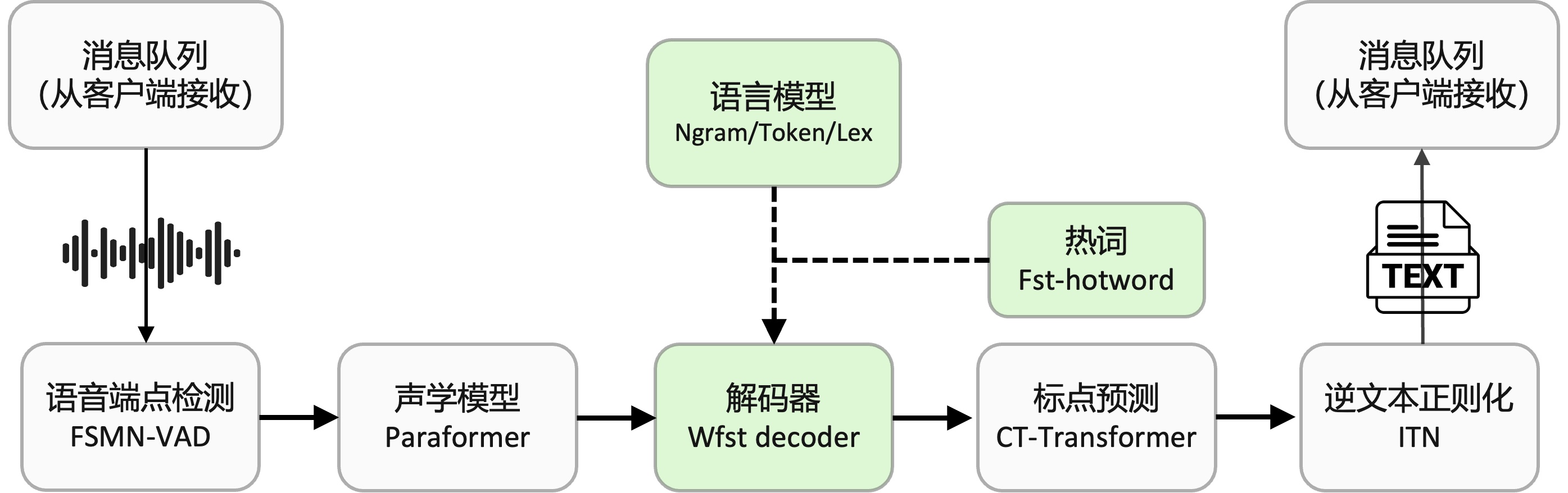
FunASR离线文件转写软件包,提供了一款功能强大的语音离线文件转写服务。拥有完整的语音识别链路,结合了语音端点检测、语音识别、标点等模型,可以将几十个小时的长音频与视频识别成带标点的文字,而且支持上百路请求同时进行转写。输出为带标点的文字,含有字级别时间戳,支持ITN与用户自定义热词等。服务端集成有ffmpeg,支持各种音视频格式输入。软件包提供有html、python、c++、java与c#等多种编程语言客户端。
实时听写服务
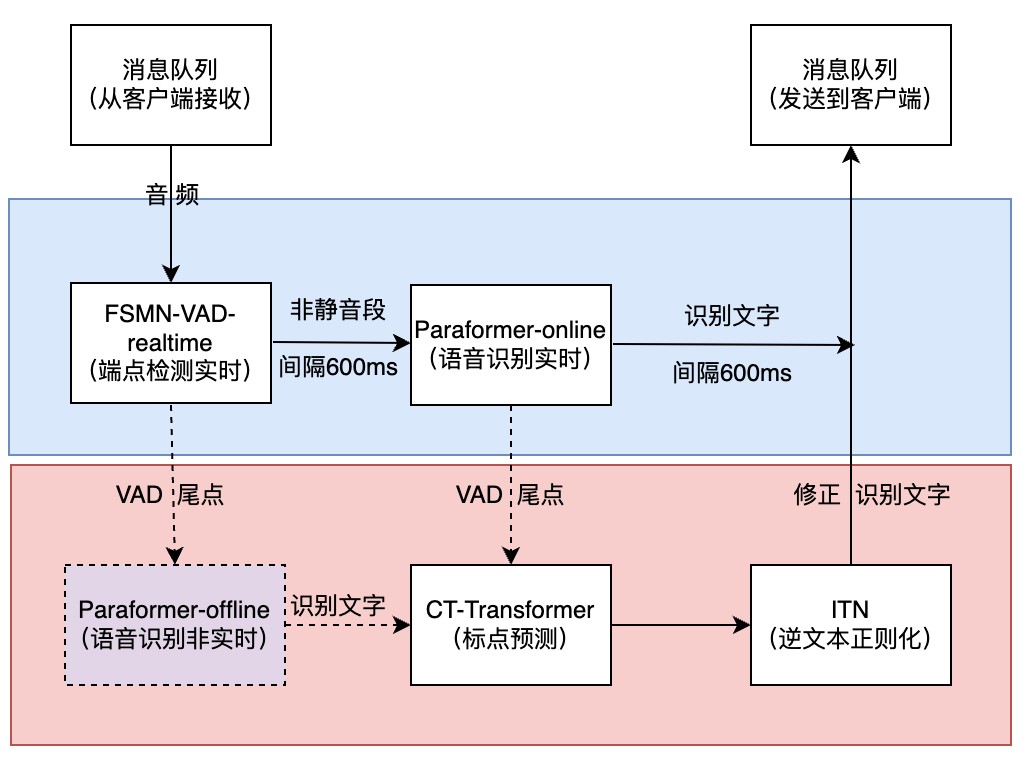
FunASR实时语音听写软件包,集成了实时版本的语音端点检测模型、语音识别、语音识别、标点预测模型等。采用多模型协同,既可以实时的进行语音转文字,也可以在说话句尾用高精度转写文字修正输出,输出文字带有标点,支持多路请求。依据使用者场景不同,支持实时语音听写服务(online)、非实时一句话转写(offline)与实时与非实时一体化协同(2pass)3种服务模式。软件包提供有html、python、c++、java与c#等多种编程语言客户端。
AutoModel 代码整体架构
FunASR 的 AutoModel 类,它是一个多模型协调引擎,用于语音处理任务。主要支持以下几种模型的组合:
核心模型类型
| 模型类型 | 功能 | 用途 |
|---|---|---|
主模型 (model) |
自动语音识别(ASR) | 核心语音转文字功能 |
| VAD 模型 | 语音活动检测 | 检测音频中的语音段 |
标点模型 (punc_model) |
标点符号恢复 | 为识别文本添加标点 |
说话人模型 (spk_model) |
说话人识别/分离 | 识别不同说话人、进行说话人分离 |
多模型协作流程
初始化阶段 (__init__ 方法)
1. 构建主ASR模型
↓
2. 如果指定VAD模型 → 加载VAD模型
↓
3. 如果指定标点模型 → 加载标点模型
↓
4. 如果指定说话人模型 → 加载说话人模型 + 聚类后端
推理流程 (generate → inference_with_vad)
输入音频
↓
┌──────────────────────────────────────────┐
│ 步骤1: VAD 分段 (可选)
│ 使用VAD模型检测音频中的语音段
│ 输出: [{start_ms, end_ms}, ...]
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 步骤2: ASR 识别 (主要处理)
│ 对每个VAD段进行语音识别
│ 输出: 识别文本 + 时间戳
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 步骤3: 标点恢复 (可选)
│ 为识别文本添加标点符号
│ 输入: 原始文本
│ 输出: 有标点的文本 + 标点数组
└──────────────────────────────────────────┘
↓
┌──────────────────────────────────────────┐
│ 步骤4: 说话人分离/识别 (可选)
│ • 提取每个片段的说话人嵌入向量
│ • 使用聚类将相同说话人聚集
│ • 分配说话人标签
│ 输出: 带说话人信息的句子列表
└──────────────────────────────────────────┘
↓
最终输出: 完整的转录结果
关键方法解析
1️⃣ prepare_data_iterator - 数据准备
处理多种输入格式:
- 文件路径 (
.scp,.jsonl,.txt) - 音频数据 (原始样本、字节、fbank特征)
- 列表 (多个输入文件)
2️⃣ build_model - 模型构建
- 下载模型权重
- 构建 tokenizer (分词器)
- 构建 frontend (前端特征提取)
- 加载预训练权重
- 处理 FP16/BF16 精度转换
3️⃣ inference - 单个模型推理
单个批次处理流程:
数据加载 → 前向传播 → 结果收集
支持实时进度回调
计算RTF (实时因子) 等性能指标
4️⃣ inference_with_vad - 多模型协作推理
关键步骤:
# 步骤1: VAD分段
res = self.inference(input, model=self.vad_model)
# res = [{"key": "...", "value": [[start, end], ...]}]
# 步骤2: 按时长排序VAD片段并分批处理
sorted_data = sorted(data_with_index, key=lambda x: x[0][1] - x[0][0])
# 步骤3: 对每个VAD片段进行ASR
results = self.inference(speech_j, model=self.model)
# 步骤4: 如果有说话人模型,提取说话人嵌入
if self.spk_model is not None:
segments = sv_chunk(vad_segments) # 分割成更小的片段
spk_res = self.inference(speech_b, model=self.spk_model)
# 获取说话人嵌入向量
# 步骤5: 对所有VAD片段的结果进行合并
for j in range(n):
if k.startswith("timestamp"):
# 调整时间戳
result[k].extend(restored_data[j][k])
# 步骤6: 标点恢复
punc_res = self.inference(result["text"], model=self.punc_model)
# 步骤7: 说话人聚类和分配
labels = self.cb_model(spk_embedding.cpu())
sv_output = postprocess(all_segments, None, labels, spk_embedding.cpu())
distribute_spk(sentence_list, sv_output)
模型间的数据流
┌─────────────────────────────────────────────────────────┐
│ 输入音频信号
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ VAD模型: 音频 → 语音活动检测
│ 输出: [[0ms, 2000ms], [3000ms, 5500ms], ...]
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────┐
│ 按时长排序优化处理顺序
└─────────────────────────────────────────┘
↓ (对每个片段)
┌─────────────────────────────────────────────────────────┐
│ ASR模型: 音频片段 → 文本 + 时间戳
│ 输出: {"text": "你好", "timestamp": [[0,0.5], ...]}
└─────────────────────────────────────────────────────────┘
↓
┌──────────────────────────────────────┐
│ 结果合并和恢复原始顺序
└──────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 标点模型: 文本 → 带标点的文本
│ 输出: {"text": "你好。", "punc_array": [...]}
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 说话人模型: 每个片段 → 说话人嵌入向量
│ 输出: spk_embedding (shape: [N, embedding_dim])
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 聚类后端: 嵌入向量 → 说话人标签
│ 输出: labels = [speaker_id_1, speaker_id_2, ...]
└─────────────────────────────────────────────────────────┘
↓
┌─────────────────────────────────────────────────────────┐
│ 后处理: 关联说话人信息到句子
│ 最终输出: 带说话人标签的完整转录
└─────────────────────────────────────────────────────────┘
模型
(注:⭐ 表示ModelScope模型仓库,🤗 表示Huggingface模型仓库,🍀表示OpenAI模型仓库)
| 模型名字 | 任务详情 | 训练数据 | 参数量 |
|---|---|---|---|
| Fun-ASR-Nano (⭐ 🤗 ) |
语音识别,支持中文、英文与日语,其中中文支持7个方言,26个地方口音,英文与日语覆盖多地区口音,歌词识别,说唱等 | 数千万小时 | 800M |
| SenseVoiceSmall (⭐ 🤗 ) |
多种语音理解能力,涵盖了自动语音识别(ASR)、语言识别(LID)、情感识别(SER)以及音频事件检测(AED) | 400000小时,中文 | 330M |
| paraformer-zh (⭐ 🤗 ) |
语音识别,带时间戳输出,非实时 | 60000小时,中文 | 220M |
| paraformer-zh-streaming ( ⭐ 🤗 ) |
语音识别,实时 | 60000小时,中文 | 220M |
| paraformer-en ( ⭐ 🤗 ) |
语音识别,非实时 | 50000小时,英文 | 220M |
| conformer-en ( ⭐ 🤗 ) |
语音识别,非实时 | 50000小时,英文 | 220M |
| ct-punc ( ⭐ 🤗 ) |
标点恢复 | 100M,中文与英文 | 290M |
| fsmn-vad ( ⭐ 🤗 ) |
语音端点检测,实时 | 5000小时,中文与英文 | 0.4M |
| fsmn-kws ( ⭐ ) |
语音唤醒,实时 | 5000小时,中文 | 0.7M |
| fa-zh ( ⭐ 🤗 ) |
字级别时间戳预测 | 50000小时,中文 | 38M |
| cam++ ( ⭐ 🤗 ) |
说话人确认/分割 | 5000小时 | 7.2M |
| Whisper-large-v3 (⭐ 🍀 ) |
语音识别,带时间戳输出,非实时 | 多语言 | 1550 M |
| Whisper-large-v3-turbo (⭐ 🍀 ) |
语音识别,带时间戳输出,非实时 | 多语言 | 809 M |
| Qwen-Audio (⭐ 🤗 ) |
音频文本多模态大模型(预训练) | 多语言 | 8B |
| Qwen-Audio-Chat (⭐ 🤗 ) |
音频文本多模态大模型(chat版本) | 多语言 | 8B |
| emotion2vec+large (⭐ 🤗 ) |
情感识别模型 | 40000小时,4种情感类别 | 300M |
基础知识
PCM(脉冲编码调制)
PCM(Pulse Code Modulation,脉冲编码调制)是一种将模拟声音转换为数字信号的最基础、最标准的方法,它通过固定的采样率(如 16kHz)对连续声波进行均匀取样,并用固定的量化精度(如 16bit)记录每个采样点的振幅,从而形成一串线性且无压缩的原始波形数据。PCM 不包含任何编码、压缩或格式元数据,因此既能完整保留语音特征,又便于实时处理,是绝大多数语音识别(ASR)模型和实时音频系统的默认输入格式。
梅尔频谱图 (Mel-spectrogram)
Mel-频谱图,你可以把它想象成是声音的“照片”,但这张照片是人工智能最容易理解的版本。
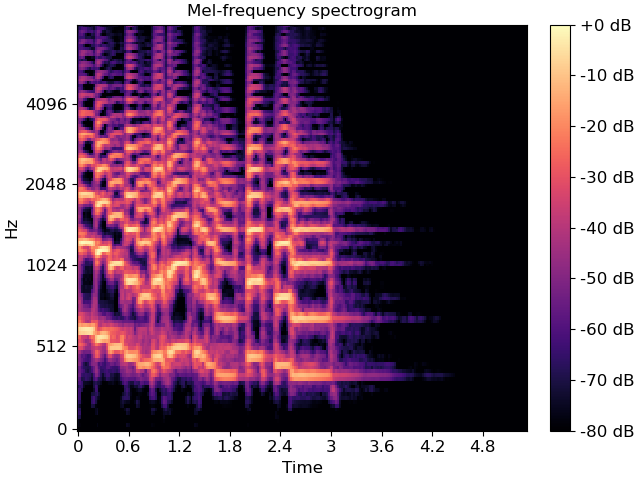
简单来说:
- 频谱图 (Spectrogram):它将一段声音(比如人说话或一段音乐)分解成一张图。这张图的横轴代表时间,纵轴代表频率(也就是音高),图上的颜色或亮度代表能量(也就是音量)。
- Mel-刻度 (Mel Scale):因为人类耳朵对低音的感知比对高音的感知更精细,所以科学家设计了一个特殊的“Mel”刻度,它模仿了人耳听觉的非线性特性。
- Mel-频谱图:就是将普通的频谱图的纵轴(频率)扭曲了一下,让它更符合人耳的听觉习惯。通过这种处理,AI 模型(比如语音识别或音乐分类系统)在分析这张“照片”时,就能更关注那些人类真正在意的声音特征,从而大大提高它们理解和处理音频数据的效率和准确性。
总结:它是一种特殊的、模拟人类听觉的声学图像,是现代人工智能处理声音时的标准输入格式。
准备语音文件
| 音频文件 | 说明 |
|---|---|
| meeting.wav | 多人音频、中英文等合并的 |
| test.wav | 我录制的 荷兰... |
| asr_example.wav | 达摩院 |
| guess_age_gender.wav | English |
| output.wav | 百度飞桨 |
| blank2.wav | 2 秒空白 |
| blank4.wav | 4 秒空白 |
| kws_xiaoyunxiaoyun.wav | 小云小云 唤醒 |
| sv_example_enroll.wav | 说话人确认 |
| sv_example_different.wav | 不同说话人 |
| sv_example_same.wav | 相同说话人 |
转换音频格式(m4a -> wav)
使用 ffmpeg 将音频文件转换为 16kHz 单声道 WAV 格式:
ffmpeg -i blank2.m4a -ar 16000 -ac 1 blank2.wav
ar16000:采样率 16 kHz(ASR 常用)ac1:单声道
不加这两个参数则保持原始参数
合并音频文件
创建一个文本文件 list_meeting.txt,内容如下:
list_meeting.txt
file 'test.wav'
file 'blank4.wav'
file 'asr_example.wav'
file 'blank2.wav'
file 'guess_age_gender.wav'
file 'blank2.wav'
file 'output.wav'
file 'blank4.wav'
file 'test.wav'
然后使用以下命令合并音频文件:
ffmpeg -f concat -safe 0 -i list_meeting.txt -ar 16000 -ac 1 -sample_fmt s16 meeting.wav
模拟会议场景,包含多人语音和静音片段。
实验(性能)
- ASR:
Automatic Speech Recognition- 自动语音识别 - VAD:
Voice Activity Detection- 语音活动检测 - PUNC:
Punctuation Restoration- 标点恢复 - SV:
Speaker Verification- 说话人验证/分离
代码
- CPU
from funasr import AutoModel
model = AutoModel(
model="iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
vad_model="iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="iic/punc_ct-transformer_cn-en-common-vocab471067-large",
spk_model="iic/speech_campplus_sv_zh-cn_16k-common",
disable_pbar=True, # 关闭进度条
)
res = model.generate(
input="wav/meeting.wav",
)
print(res)
- MPS
from funasr import AutoModel
model = AutoModel(
model="iic/speech_paraformer-large-vad-punc_asr_nat-zh-cn-16k-common-vocab8404-pytorch",
vad_model="iic/speech_fsmn_vad_zh-cn-16k-common-pytorch",
punc_model="iic/punc_ct-transformer_cn-en-common-vocab471067-large",
spk_model="iic/speech_campplus_sv_zh-cn_16k-common",
disable_pbar=True, # 关闭进度条
device="mps",
)
res = model.generate(
input="wav/meeting.wav",
)
print(res)
性能
- 硬件:Macbook Pro M2 Max, 64GB RAM
- 音频文件长度:84.789 s
全链路性能对比
| 模型配置 | MPS 推理用时 | CPU 推理用时 | MPS vs CPU |
|---|---|---|---|
| ① 纯 ASR(paraformer-zh) | 2.636 s | 2.417 s | 0.92× 🐢 |
| ② ASR + VAD(fsmn-vad) | 1.414 s 🚀 | 2.642 s | 1.87× |
| ③ ASR + VAD + PUNC(ct-punc) | 2.072 s | 2.795 s | 1.35× |
| ④ ASR + VAD + PUNC + SV(cam++) | 4.061 s | 11.839 s | 2.92× |
ASR 模型性能对比
| 模型配置 | MPS 推理用时 | CPU 推理用时 | MPS vs CPU |
|---|---|---|---|
paraformer-zh (ASR) |
2.636 s | 2.417 s | 0.92× |
paraformer-zh (+VAD +PUNC) |
2.072 s | 2.795 s | 1.35× |
| SenseVoiceSmall | 0.420 s | 2.244 s | 5.34× |
| Fun-ASR-Nano | 4.733 s | 11.831 s | 2.50x |
① ASR
[
{
'key': 'meeting',
'text': '格 兰 发 布 了 一 份 主 题 为 宣 布 即 将 对 先 进 半 导 体 制 造 设 备 采 取 的 出 口 管 制 措 施 的 公 告 表 示 鉴 于 技 术 的 发 展 和 地 缘 政 治 的 背 景 政 府 已 经 得 出 结 论 有 必 要 扩 大 现 有 的 特 定 半 导 体 制 造 设 备 的 出 口 管 制 欢 迎 大 家 来 体 验 达 摩 院 推 出 的 语 音 识 别 模 型 i heard that you can 的 a 的 for II know my agent gender from i 欢 百 度 度 讲 深 度 的 的 表 告 发 布 了 一 份 主 题 为 宣 布 即 将 对 先 进 半 导 体 制 造 设 备 管 导 的 出 口 管 制 措 施 的 公 告 表 示 鉴 于 技 术 的 发 展 和 地 缘 政 治 的 背 景 政 府 即 将 得 出 体 导 论 必 必 要 扩 导 导 有 的 设 备 半 导 体 制 造 设 备 的 出 口 管 制',
'timestamp': [
[
990,
1230
],
[
1350,
1590
],
[
1590,
1830
],
[
1830,
2070
],
[
2070,
2310
],
[
2330,
2570
],
[
2890,
3130
],
[
3170,
3350
],
[
3350,
3590
],
[
4130,
4370
],
[
4490,
4730
],
[
4870,
5110
],
[
5110,
5350
],
[
5710,
5950
],
[
6130,
6370
],
[
6490,
6730
],
[
6790,
6990
],
[
6990,
7230
],
[
7230,
7470
],
[
7510,
7650
],
[
7650,
7890
],
[
8010,
8250
],
[
8470,
8710
],
[
8790,
9030
],
[
9090,
9330
],
[
9650,
9890
],
[
9930,
10170
],
[
10170,
10370
],
[
10370,
10610
],
[
10630,
10790
],
[
10790,
11030
],
[
11350,
11590
],
[
11730,
11890
],
[
11890,
12130
],
[
12150,
12310
],
[
12310,
12550
],
[
13190,
13430
],
[
13590,
13830
],
[
13990,
14190
],
[
14190,
14370
],
[
14370,
14590
],
[
14590,
14810
],
[
14810,
15050
],
[
15410,
15650
],
[
15690,
15930
],
[
15950,
16170
],
[
16170,
16290
],
[
16290,
16410
],
[
16410,
16610
],
[
16610,
16850
],
[
17390,
17630
],
[
17690,
17930
],
[
18030,
18250
],
[
18250,
18490
],
[
18610,
18850
],
[
18850,
19090
],
[
19230,
19390
],
[
19390,
19630
],
[
20010,
20250
],
[
20410,
20650
],
[
20670,
20910
],
[
20970,
21210
],
[
21270,
21510
],
[
21790,
22030
],
[
22110,
22350
],
[
22470,
22710
],
[
22710,
22950
],
[
23030,
23210
],
[
23210,
23450
],
[
23450,
23690
],
[
24410,
24650
],
[
24770,
24970
],
[
24970,
25150
],
[
25150,
25330
],
[
25330,
25550
],
[
25550,
25750
],
[
25750,
25990
],
[
26050,
26250
],
[
26250,
26490
],
[
31970,
32210
],
[
32250,
32490
],
[
32509,
32670
],
[
32670,
32870
],
[
32870,
33110
],
[
33270,
33510
],
[
33550,
33690
],
[
33690,
33870
],
[
33870,
34110
],
[
34170,
34370
],
[
34370,
34610
],
[
34610,
34810
],
[
34810,
35030
],
[
35030,
35270
],
[
35330,
35530
],
[
35530,
35770
],
[
35790,
35950
],
[
35950,
36190
],
[
39690,
39850
],
[
39850,
39990
],
[
39990,
40130
],
[
40130,
40250
],
[
40250,
40490
],
[
40510,
40750
],
[
40750,
41210
],
[
41210,
41450
],
[
41570,
41810
],
[
42390,
42610
],
[
42610,
42850
],
[
43370,
43490
],
[
43490,
43730
],
[
43830,
43970
],
[
43970,
45230
],
[
45230,
45430
],
[
45430,
45650
],
[
45650,
46050
],
[
46090,
46530
],
[
46630,
46770
],
[
46770,
47010
],
[
47030,
47190
],
[
47470,
47710
],
[
50790,
50970
],
[
50970,
51210
],
[
51230,
51370
],
[
51370,
51610
],
[
51750,
51850
],
[
51850,
52050
],
[
52050,
52290
],
[
52410,
52550
],
[
52550,
52790
],
[
52790,
52930
],
[
52930,
53170
],
[
53310,
53550
],
[
58570,
58810
],
[
58850,
59090
],
[
59230,
59470
],
[
59470,
59710
],
[
59710,
59950
],
[
59950,
60190
],
[
60190,
60430
],
[
60750,
60990
],
[
61030,
61210
],
[
61210,
61450
],
[
61990,
62230
],
[
62350,
62590
],
[
62730,
62970
],
[
62970,
63210
],
[
63570,
63810
],
[
64030,
64269
],
[
64349,
64590
],
[
64650,
64890
],
[
65010,
65250
],
[
65269,
65430
],
[
65430,
65670
],
[
65770,
66010
],
[
66030,
66270
],
[
66330,
66570
],
[
66650,
66890
],
[
66950,
67190
],
[
67510,
67750
],
[
67790,
68030
],
[
68030,
68230
],
[
68230,
68470
],
[
68490,
68650
],
[
68650,
68890
],
[
69250,
69490
],
[
69610,
69810
],
[
69810,
70010
],
[
70010,
70170
],
[
70170,
70410
],
[
71090,
71330
],
[
71450,
71690
],
[
71970,
72150
],
[
72150,
72370
],
[
72370,
72610
],
[
72630,
72870
],
[
72870,
73110
],
[
73270,
73510
],
[
73550,
73790
],
[
73810,
74030
],
[
74030,
74150
],
[
74150,
74310
],
[
74310,
74470
],
[
74470,
74710
],
[
75250,
75490
],
[
75550,
75790
],
[
75890,
76110
],
[
76110,
76350
],
[
76470,
76710
],
[
76710,
76950
],
[
77090,
77270
],
[
77270,
77510
],
[
78170,
78410
],
[
78450,
78690
],
[
78730,
78970
],
[
79050,
79290
],
[
79550,
79790
],
[
79790,
79970
],
[
79970,
80210
],
[
80330,
80570
],
[
80570,
80810
],
[
80890,
81070
],
[
81070,
81310
],
[
81370,
81610
],
[
82270,
82510
],
[
82630,
82830
],
[
82830,
83010
],
[
83010,
83190
],
[
83190,
83410
],
[
83410,
83610
],
[
83610,
83850
],
[
83910,
84445
]
]
}
]
② ASR + VAD
[
{
'key': 'meeting',
'text': '格 兰 发 布 了 一 份 主 题 为 宣 布 即 将 对 先 进 半 导 体 制 造 设 备 采 取 的 出 口 管 制 措 施 的 公 告 表 示 鉴 于 技 术 的 发 展 和 地 缘 政 治 的 背 景 政 府 已 经 得 出 结 论 有 必 要 扩 大 现 有 的 特 定 半 导 体 制 造 设 备 的 出 口 管 制 欢 迎 大 家 来 体 验 达 摩 院 推 出 的 语 音 识 别 模 型 i heard that you can understand what people say and even though they are age and gender so can you guess my age and gender from my voice 你 好 欢 迎 使 用 百 度 飞 桨 深 度 学 习 框 架 格 兰 发 布 了 一 份 主 题 为 宣 布 即 将 对 先 进 半 导 体 制 造 设 备 采 取 的 出 口 管 制 措 施 的 公 告 表 示 鉴 于 技 术 的 发 展 和 地 缘 政 治 的 背 景 政 府 已 经 得 出 结 论 有 必 要 扩 大 现 有 的 特 定 半 导 体 制 造 设 备 的 出 口 管 制',
'timestamp': [
[
790,
1030
],
[
1030,
1270
],
[
1410,
1650
],
[
1670,
1850
],
[
1850,
2090
],
[
2130,
2370
],
[
2390,
2630
],
[
2930,
3170
],
[
3170,
3410
],
[
3410,
3650
],
[
4170,
4410
],
[
4490,
4730
],
[
4890,
5130
],
[
5150,
5390
],
[
5690,
5930
],
[
6150,
6390
],
[
6470,
6710
],
[
6810,
7010
],
[
7010,
7190
],
[
7190,
7430
],
[
7470,
7670
],
[
7670,
7910
],
[
7990,
8230
],
[
8250,
8490
],
[
8529,
8770
],
[
8790,
9030
],
[
9090,
9330
],
[
9710,
9930
],
[
9930,
10170
],
[
10230,
10410
],
[
10410,
10610
],
[
10610,
10830
],
[
10830,
11070
],
[
11390,
11630
],
[
11750,
11910
],
[
11910,
12110
],
[
12110,
12330
],
[
12330,
12570
],
[
13170,
13410
],
[
13530,
13770
],
[
13930,
14170
],
[
14190,
14350
],
[
14350,
14570
],
[
14570,
14770
],
[
14770,
15010
],
[
15070,
15310
],
[
15410,
15650
],
[
15670,
15910
],
[
15950,
16150
],
[
16150,
16330
],
[
16330,
16430
],
[
16430,
16570
],
[
16570,
16809
],
[
17370,
17610
],
[
17650,
17890
],
[
18010,
18190
],
[
18190,
18430
],
[
18610,
18850
],
[
18850,
19090
],
[
19230,
19390
],
[
19390,
19630
],
[
19970,
20210
],
[
20370,
20570
],
[
20570,
20810
],
[
20910,
21150
],
[
21230,
21470
],
[
21670,
21890
],
[
21890,
22130
],
[
22130,
22370
],
[
22470,
22710
],
[
22730,
22970
],
[
23010,
23210
],
[
23210,
23450
],
[
23450,
23690
],
[
24390,
24630
],
[
24710,
24910
],
[
24910,
25130
],
[
25130,
25310
],
[
25310,
25470
],
[
25470,
25670
],
[
25670,
25910
],
[
25970,
26150
],
[
26150,
26565
],
[
32020,
32240
],
[
32240,
32480
],
[
32500,
32660
],
[
32660,
32900
],
[
32900,
33140
],
[
33140,
33300
],
[
33300,
33540
],
[
33620,
33780
],
[
33780,
33900
],
[
33900,
34140
],
[
34160,
34360
],
[
34360,
34600
],
[
34600,
34820
],
[
34820,
35020
],
[
35020,
35260
],
[
35300,
35540
],
[
35540,
35740
],
[
35740,
35900
],
[
35900,
36255
],
[
39490,
39690
],
[
39690,
39990
],
[
39990,
40150
],
[
40150,
40270
],
[
40270,
40430
],
[
40430,
41070
],
[
41070,
41210
],
[
41210,
41450
],
[
41570,
41810
],
[
41890,
42070
],
[
42070,
42310
],
[
42350,
42550
],
[
42550,
42710
],
[
42710,
42950
],
[
43130,
43370
],
[
43550,
43770
],
[
43770,
44190
],
[
44750,
44990
],
[
45070,
45210
],
[
45210,
45450
],
[
45450,
45770
],
[
45770,
45970
],
[
45970,
46210
],
[
46330,
46530
],
[
46530,
46930
],
[
46970,
47170
],
[
47170,
47370
],
[
47370,
47915
],
[
50150,
50330
],
[
50330,
50570
],
[
50770,
50990
],
[
50990,
51230
],
[
51230,
51390
],
[
51390,
51630
],
[
51650,
51810
],
[
51810,
51990
],
[
51990,
52150
],
[
52150,
52350
],
[
52350,
52570
],
[
52570,
52710
],
[
52710,
52850
],
[
52850,
53070
],
[
53070,
53270
],
[
53270,
53565
],
[
58640,
58880
],
[
58880,
59120
],
[
59260,
59500
],
[
59520,
59700
],
[
59700,
59940
],
[
59980,
60180
],
[
60180,
60420
],
[
60780,
61020
],
[
61020,
61260
],
[
61260,
61500
],
[
62020,
62260
],
[
62340,
62580
],
[
62740,
62980
],
[
63000,
63240
],
[
63540,
63780
],
[
64000,
64240
],
[
64320,
64560
],
[
64660,
64860
],
[
64860,
65040
],
[
65040,
65280
],
[
65320,
65520
],
[
65520,
65760
],
[
65840,
66040
],
[
66040,
66280
],
[
66379,
66620
],
[
66640,
66880
],
[
66940,
67180
],
[
67560,
67780
],
[
67780,
68020
],
[
68080,
68260
],
[
68260,
68460
],
[
68460,
68680
],
[
68680,
68920
],
[
69220,
69460
],
[
69560,
69760
],
[
69760,
69960
],
[
69960,
70120
],
[
70120,
70360
],
[
71020,
71260
],
[
71380,
71620
],
[
71780,
72020
],
[
72040,
72200
],
[
72200,
72420
],
[
72420,
72620
],
[
72620,
72860
],
[
72880,
73120
],
[
73260,
73500
],
[
73520,
73760
],
[
73800,
74000
],
[
74000,
74180
],
[
74180,
74280
],
[
74280,
74420
],
[
74420,
74659
],
[
75220,
75460
],
[
75500,
75740
],
[
75840,
76040
],
[
76040,
76280
],
[
76440,
76680
],
[
76700,
76940
],
[
77080,
77240
],
[
77240,
77480
],
[
77800,
78040
],
[
78220,
78420
],
[
78420,
78660
],
[
78760,
79000
],
[
79080,
79320
],
[
79520,
79740
],
[
79740,
79980
],
[
79980,
80220
],
[
80320,
80560
],
[
80580,
80820
],
[
80860,
81060
],
[
81060,
81300
],
[
81300,
81540
],
[
82260,
82500
],
[
82560,
82760
],
[
82760,
82980
],
[
82980,
83160
],
[
83160,
83320
],
[
83320,
83520
],
[
83520,
83760
],
[
83820,
84000
],
[
84000,
84415
]
]
}
]
③ ASR + VAD + PUNC
[
{
'key': 'meeting',
'text': '格兰发布了一份主题,为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。欢迎大家来体验达摩院推出的语音识别模型。 I heard that you can understand what people say, and even though they are age and gender. So can you guess my age and gender from my voice?你好,欢迎使用百度飞桨深度学习框架。格兰发布了一份主题。为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。',
'timestamp': [
[
790,
1030
],
[
1030,
1270
],
[
1410,
1650
],
[
1670,
1850
],
[
1850,
2090
],
[
2130,
2370
],
[
2390,
2630
],
[
2930,
3170
],
[
3170,
3410
],
[
3410,
3650
],
[
4170,
4410
],
[
4490,
4730
],
[
4890,
5130
],
[
5150,
5390
],
[
5690,
5930
],
[
6150,
6390
],
[
6470,
6710
],
[
6810,
7010
],
[
7010,
7190
],
[
7190,
7430
],
[
7470,
7670
],
[
7670,
7910
],
[
7990,
8230
],
[
8250,
8490
],
[
8529,
8770
],
[
8790,
9030
],
[
9090,
9330
],
[
9710,
9930
],
[
9930,
10170
],
[
10230,
10410
],
[
10410,
10610
],
[
10610,
10830
],
[
10830,
11070
],
[
11390,
11630
],
[
11750,
11910
],
[
11910,
12110
],
[
12110,
12330
],
[
12330,
12570
],
[
13170,
13410
],
[
13530,
13770
],
[
13930,
14170
],
[
14190,
14370
],
[
14370,
14570
],
[
14570,
14770
],
[
14770,
15010
],
[
15070,
15310
],
[
15410,
15650
],
[
15670,
15910
],
[
15950,
16150
],
[
16150,
16330
],
[
16330,
16430
],
[
16430,
16570
],
[
16570,
16809
],
[
17370,
17610
],
[
17650,
17890
],
[
18010,
18190
],
[
18190,
18430
],
[
18610,
18850
],
[
18850,
19090
],
[
19230,
19390
],
[
19390,
19630
],
[
19990,
20230
],
[
20370,
20570
],
[
20570,
20810
],
[
20910,
21150
],
[
21230,
21470
],
[
21670,
21890
],
[
21890,
22130
],
[
22130,
22370
],
[
22470,
22710
],
[
22730,
22970
],
[
23010,
23210
],
[
23210,
23450
],
[
23450,
23690
],
[
24390,
24630
],
[
24710,
24910
],
[
24910,
25130
],
[
25130,
25310
],
[
25310,
25470
],
[
25470,
25670
],
[
25670,
25910
],
[
25970,
26150
],
[
26150,
26565
],
[
32020,
32240
],
[
32240,
32480
],
[
32500,
32660
],
[
32660,
32900
],
[
32900,
33140
],
[
33140,
33300
],
[
33300,
33540
],
[
33620,
33780
],
[
33780,
33900
],
[
33900,
34140
],
[
34160,
34360
],
[
34360,
34600
],
[
34600,
34820
],
[
34820,
35020
],
[
35020,
35260
],
[
35300,
35540
],
[
35540,
35740
],
[
35740,
35900
],
[
35900,
36255
],
[
39490,
39690
],
[
39690,
39990
],
[
39990,
40150
],
[
40150,
40270
],
[
40270,
40430
],
[
40430,
41070
],
[
41070,
41210
],
[
41210,
41450
],
[
41570,
41810
],
[
41890,
42070
],
[
42070,
42310
],
[
42350,
42550
],
[
42550,
42710
],
[
42710,
42950
],
[
43130,
43370
],
[
43550,
43770
],
[
43770,
44190
],
[
44770,
45010
],
[
45070,
45210
],
[
45210,
45450
],
[
45450,
45770
],
[
45770,
45970
],
[
45970,
46210
],
[
46330,
46530
],
[
46530,
46930
],
[
46970,
47170
],
[
47170,
47370
],
[
47370,
47915
],
[
50150,
50330
],
[
50330,
50570
],
[
50770,
50990
],
[
50990,
51230
],
[
51230,
51390
],
[
51390,
51630
],
[
51650,
51810
],
[
51810,
51990
],
[
51990,
52150
],
[
52150,
52350
],
[
52350,
52570
],
[
52570,
52710
],
[
52710,
52850
],
[
52850,
53070
],
[
53070,
53270
],
[
53270,
53565
],
[
58640,
58880
],
[
58880,
59120
],
[
59260,
59500
],
[
59520,
59700
],
[
59700,
59940
],
[
59980,
60180
],
[
60180,
60420
],
[
60780,
61020
],
[
61020,
61260
],
[
61260,
61500
],
[
62020,
62260
],
[
62340,
62580
],
[
62740,
62980
],
[
63000,
63240
],
[
63540,
63780
],
[
64000,
64240
],
[
64320,
64560
],
[
64660,
64860
],
[
64860,
65040
],
[
65040,
65280
],
[
65320,
65520
],
[
65520,
65760
],
[
65840,
66040
],
[
66040,
66280
],
[
66379,
66620
],
[
66640,
66880
],
[
66940,
67180
],
[
67560,
67780
],
[
67780,
68020
],
[
68080,
68260
],
[
68260,
68460
],
[
68460,
68680
],
[
68680,
68920
],
[
69220,
69460
],
[
69560,
69760
],
[
69760,
69960
],
[
69960,
70120
],
[
70120,
70360
],
[
71020,
71260
],
[
71380,
71620
],
[
71780,
72020
],
[
72040,
72200
],
[
72200,
72420
],
[
72420,
72620
],
[
72620,
72860
],
[
72880,
73120
],
[
73260,
73500
],
[
73520,
73760
],
[
73800,
74000
],
[
74000,
74180
],
[
74180,
74280
],
[
74280,
74420
],
[
74420,
74659
],
[
75220,
75460
],
[
75500,
75740
],
[
75840,
76040
],
[
76040,
76280
],
[
76440,
76680
],
[
76700,
76940
],
[
77080,
77240
],
[
77240,
77480
],
[
77800,
78040
],
[
78220,
78420
],
[
78420,
78660
],
[
78760,
79000
],
[
79080,
79320
],
[
79520,
79740
],
[
79740,
79980
],
[
79980,
80220
],
[
80320,
80560
],
[
80580,
80820
],
[
80860,
81060
],
[
81060,
81300
],
[
81300,
81540
],
[
82260,
82500
],
[
82560,
82760
],
[
82760,
82980
],
[
82980,
83160
],
[
83160,
83320
],
[
83320,
83520
],
[
83520,
83760
],
[
83820,
84000
],
[
84000,
84415
]
]
}
]
④ ASR + VAD + PUNC + SV
[
{
'key': 'meeting',
'text': '格兰发布了一份主题,为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。欢迎大家来体验达摩院推出的语音识别模型。 I heard that you can understand what people say, and even though they are age and gender. So can you guess my age and gender from my voice?你好,欢迎使用百度飞桨深度学习框架。格兰发布了一份主题。为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。',
'timestamp': [
[
790,
1030
],
[
1030,
1270
],
[
1410,
1650
],
[
1670,
1850
],
[
1850,
2090
],
[
2130,
2370
],
[
2370,
2610
],
[
2930,
3170
],
[
3170,
3410
],
[
3410,
3650
],
[
4170,
4410
],
[
4490,
4730
],
[
4890,
5130
],
[
5150,
5390
],
[
5690,
5930
],
[
6150,
6390
],
[
6470,
6710
],
[
6810,
7010
],
[
7010,
7190
],
[
7190,
7430
],
[
7470,
7670
],
[
7670,
7910
],
[
7990,
8230
],
[
8250,
8490
],
[
8529,
8770
],
[
8790,
9030
],
[
9090,
9330
],
[
9710,
9930
],
[
9930,
10170
],
[
10230,
10410
],
[
10410,
10610
],
[
10610,
10830
],
[
10830,
11070
],
[
11390,
11630
],
[
11750,
11910
],
[
11910,
12110
],
[
12110,
12330
],
[
12330,
12570
],
[
13170,
13410
],
[
13530,
13770
],
[
13930,
14170
],
[
14190,
14370
],
[
14370,
14570
],
[
14570,
14770
],
[
14770,
15010
],
[
15070,
15310
],
[
15410,
15650
],
[
15670,
15910
],
[
15950,
16150
],
[
16150,
16330
],
[
16330,
16430
],
[
16430,
16570
],
[
16570,
16809
],
[
17370,
17610
],
[
17650,
17890
],
[
18010,
18190
],
[
18190,
18430
],
[
18610,
18850
],
[
18850,
19090
],
[
19230,
19390
],
[
19390,
19630
],
[
19970,
20210
],
[
20370,
20570
],
[
20570,
20810
],
[
20910,
21150
],
[
21230,
21470
],
[
21670,
21890
],
[
21890,
22130
],
[
22130,
22370
],
[
22470,
22710
],
[
22730,
22970
],
[
23010,
23210
],
[
23210,
23450
],
[
23450,
23690
],
[
24390,
24630
],
[
24710,
24910
],
[
24910,
25130
],
[
25130,
25310
],
[
25310,
25470
],
[
25470,
25670
],
[
25670,
25910
],
[
25970,
26150
],
[
26150,
26565
],
[
32020,
32240
],
[
32240,
32480
],
[
32500,
32660
],
[
32660,
32900
],
[
32900,
33140
],
[
33140,
33300
],
[
33300,
33540
],
[
33620,
33780
],
[
33780,
33900
],
[
33900,
34140
],
[
34160,
34360
],
[
34360,
34600
],
[
34600,
34820
],
[
34820,
35020
],
[
35020,
35260
],
[
35300,
35540
],
[
35540,
35740
],
[
35740,
35900
],
[
35900,
36255
],
[
39490,
39690
],
[
39690,
39990
],
[
39990,
40150
],
[
40150,
40270
],
[
40270,
40430
],
[
40430,
41070
],
[
41070,
41210
],
[
41210,
41450
],
[
41570,
41810
],
[
41890,
42070
],
[
42070,
42310
],
[
42350,
42550
],
[
42550,
42710
],
[
42710,
42950
],
[
43130,
43370
],
[
43550,
43770
],
[
43770,
44190
],
[
44770,
45010
],
[
45070,
45210
],
[
45210,
45450
],
[
45450,
45770
],
[
45770,
45970
],
[
45970,
46210
],
[
46330,
46530
],
[
46530,
46930
],
[
46970,
47170
],
[
47170,
47370
],
[
47370,
47915
],
[
50150,
50330
],
[
50330,
50570
],
[
50770,
50990
],
[
50990,
51230
],
[
51230,
51390
],
[
51390,
51630
],
[
51650,
51810
],
[
51810,
51990
],
[
51990,
52150
],
[
52150,
52350
],
[
52350,
52570
],
[
52570,
52710
],
[
52710,
52850
],
[
52850,
53070
],
[
53070,
53270
],
[
53270,
53565
],
[
58640,
58880
],
[
58880,
59120
],
[
59260,
59500
],
[
59520,
59700
],
[
59700,
59940
],
[
59980,
60180
],
[
60180,
60420
],
[
60780,
61020
],
[
61020,
61260
],
[
61260,
61500
],
[
62020,
62260
],
[
62340,
62580
],
[
62740,
62980
],
[
63000,
63240
],
[
63540,
63780
],
[
64000,
64240
],
[
64320,
64560
],
[
64660,
64860
],
[
64860,
65040
],
[
65040,
65280
],
[
65320,
65520
],
[
65520,
65760
],
[
65840,
66040
],
[
66040,
66280
],
[
66379,
66620
],
[
66640,
66880
],
[
66940,
67180
],
[
67560,
67780
],
[
67780,
68020
],
[
68080,
68260
],
[
68260,
68460
],
[
68460,
68680
],
[
68680,
68920
],
[
69220,
69460
],
[
69560,
69760
],
[
69760,
69960
],
[
69960,
70120
],
[
70120,
70360
],
[
71020,
71260
],
[
71380,
71620
],
[
71780,
72020
],
[
72040,
72200
],
[
72200,
72420
],
[
72420,
72620
],
[
72620,
72860
],
[
72880,
73120
],
[
73260,
73500
],
[
73520,
73760
],
[
73800,
74000
],
[
74000,
74180
],
[
74180,
74280
],
[
74280,
74420
],
[
74420,
74659
],
[
75220,
75460
],
[
75500,
75740
],
[
75840,
76040
],
[
76040,
76280
],
[
76440,
76680
],
[
76700,
76940
],
[
77080,
77240
],
[
77240,
77480
],
[
77800,
78040
],
[
78220,
78420
],
[
78420,
78660
],
[
78760,
79000
],
[
79080,
79320
],
[
79520,
79740
],
[
79740,
79980
],
[
79980,
80220
],
[
80320,
80560
],
[
80580,
80820
],
[
80860,
81060
],
[
81060,
81300
],
[
81300,
81540
],
[
82260,
82500
],
[
82560,
82760
],
[
82760,
82980
],
[
82980,
83160
],
[
83160,
83320
],
[
83320,
83520
],
[
83520,
83760
],
[
83820,
84000
],
[
84000,
84415
]
],
'sentence_info': [
{
'text': '格兰发布了一份主题,',
'start': 790,
'end': 3410,
'timestamp': [
[
790,
1030
],
[
1030,
1270
],
[
1410,
1650
],
[
1670,
1850
],
[
1850,
2090
],
[
2130,
2370
],
[
2370,
2610
],
[
2930,
3170
],
[
3170,
3410
]
],
'spk': 0
},
{
'text': '为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,',
'start': 3410,
'end': 12570,
'timestamp': [
[
3410,
3650
],
[
4170,
4410
],
[
4490,
4730
],
[
4890,
5130
],
[
5150,
5390
],
[
5690,
5930
],
[
6150,
6390
],
[
6470,
6710
],
[
6810,
7010
],
[
7010,
7190
],
[
7190,
7430
],
[
7470,
7670
],
[
7670,
7910
],
[
7990,
8230
],
[
8250,
8490
],
[
8529,
8770
],
[
8790,
9030
],
[
9090,
9330
],
[
9710,
9930
],
[
9930,
10170
],
[
10230,
10410
],
[
10410,
10610
],
[
10610,
10830
],
[
10830,
11070
],
[
11390,
11630
],
[
11750,
11910
],
[
11910,
12110
],
[
12110,
12330
],
[
12330,
12570
]
],
'spk': 0
},
{
'text': '鉴于技术的发展和地缘政治的背景,',
'start': 13170,
'end': 16809,
'timestamp': [
[
13170,
13410
],
[
13530,
13770
],
[
13930,
14170
],
[
14190,
14370
],
[
14370,
14570
],
[
14570,
14770
],
[
14770,
15010
],
[
15070,
15310
],
[
15410,
15650
],
[
15670,
15910
],
[
15950,
16150
],
[
16150,
16330
],
[
16330,
16430
],
[
16430,
16570
],
[
16570,
16809
]
],
'spk': 0
},
{
'text': '政府已经得出结论,',
'start': 17370,
'end': 19630,
'timestamp': [
[
17370,
17610
],
[
17650,
17890
],
[
18010,
18190
],
[
18190,
18430
],
[
18610,
18850
],
[
18850,
19090
],
[
19230,
19390
],
[
19390,
19630
]
],
'spk': 0
},
{
'text': '有必要扩大现有的特定半导体制造设备的出口管制。',
'start': 19970,
'end': 26565,
'timestamp': [
[
19970,
20210
],
[
20370,
20570
],
[
20570,
20810
],
[
20910,
21150
],
[
21230,
21470
],
[
21670,
21890
],
[
21890,
22130
],
[
22130,
22370
],
[
22470,
22710
],
[
22730,
22970
],
[
23010,
23210
],
[
23210,
23450
],
[
23450,
23690
],
[
24390,
24630
],
[
24710,
24910
],
[
24910,
25130
],
[
25130,
25310
],
[
25310,
25470
],
[
25470,
25670
],
[
25670,
25910
],
[
25970,
26150
],
[
26150,
26565
]
],
'spk': 0
},
{
'text': '欢迎大家来体验达摩院推出的语音识别模型。',
'start': 32020,
'end': 36255,
'timestamp': [
[
32020,
32240
],
[
32240,
32480
],
[
32500,
32660
],
[
32660,
32900
],
[
32900,
33140
],
[
33140,
33300
],
[
33300,
33540
],
[
33620,
33780
],
[
33780,
33900
],
[
33900,
34140
],
[
34160,
34360
],
[
34360,
34600
],
[
34600,
34820
],
[
34820,
35020
],
[
35020,
35260
],
[
35300,
35540
],
[
35540,
35740
],
[
35740,
35900
],
[
35900,
36255
]
],
'spk': 1
},
{
'text': ' i heard that you can understand what people say,',
'start': 39490,
'end': 41810,
'timestamp': [
[
39490,
39690
],
[
39690,
39990
],
[
39990,
40150
],
[
40150,
40270
],
[
40270,
40430
],
[
40430,
41070
],
[
41070,
41210
],
[
41210,
41450
],
[
41570,
41810
]
],
'spk': 2
},
{
'text': ' and even though they are age and gender。',
'start': 41890,
'end': 44190,
'timestamp': [
[
41890,
42070
],
[
42070,
42310
],
[
42350,
42550
],
[
42550,
42710
],
[
42710,
42950
],
[
43130,
43370
],
[
43550,
43770
],
[
43770,
44190
]
],
'spk': 2
},
{
'text': ' so can you guess my age and gender from my voice?',
'start': 44770,
'end': 47915,
'timestamp': [
[
44770,
45010
],
[
45070,
45210
],
[
45210,
45450
],
[
45450,
45770
],
[
45770,
45970
],
[
45970,
46210
],
[
46330,
46530
],
[
46530,
46930
],
[
46970,
47170
],
[
47170,
47370
],
[
47370,
47915
]
],
'spk': 2
},
{
'text': '你好,',
'start': 50150,
'end': 50570,
'timestamp': [
[
50150,
50330
],
[
50330,
50570
]
],
'spk': 3
},
{
'text': '欢迎使用百度飞桨深度学习框架。',
'start': 50770,
'end': 53565,
'timestamp': [
[
50770,
50990
],
[
50990,
51230
],
[
51230,
51390
],
[
51390,
51630
],
[
51650,
51810
],
[
51810,
51990
],
[
51990,
52150
],
[
52150,
52350
],
[
52350,
52570
],
[
52570,
52710
],
[
52710,
52850
],
[
52850,
53070
],
[
53070,
53270
],
[
53270,
53565
]
],
'spk': 3
},
{
'text': '格兰发布了一份主题。',
'start': 58640,
'end': 61260,
'timestamp': [
[
58640,
58880
],
[
58880,
59120
],
[
59260,
59500
],
[
59520,
59700
],
[
59700,
59940
],
[
59980,
60180
],
[
60180,
60420
],
[
60780,
61020
],
[
61020,
61260
]
],
'spk': 0
},
{
'text': '为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,',
'start': 61260,
'end': 70360,
'timestamp': [
[
61260,
61500
],
[
62020,
62260
],
[
62340,
62580
],
[
62740,
62980
],
[
63000,
63240
],
[
63540,
63780
],
[
64000,
64240
],
[
64320,
64560
],
[
64660,
64860
],
[
64860,
65040
],
[
65040,
65280
],
[
65320,
65520
],
[
65520,
65760
],
[
65840,
66040
],
[
66040,
66280
],
[
66379,
66620
],
[
66640,
66880
],
[
66940,
67180
],
[
67560,
67780
],
[
67780,
68020
],
[
68080,
68260
],
[
68260,
68460
],
[
68460,
68680
],
[
68680,
68920
],
[
69220,
69460
],
[
69560,
69760
],
[
69760,
69960
],
[
69960,
70120
],
[
70120,
70360
]
],
'spk': 0
},
{
'text': '鉴于技术的发展和地缘政治的背景,',
'start': 71020,
'end': 74659,
'timestamp': [
[
71020,
71260
],
[
71380,
71620
],
[
71780,
72020
],
[
72040,
72200
],
[
72200,
72420
],
[
72420,
72620
],
[
72620,
72860
],
[
72880,
73120
],
[
73260,
73500
],
[
73520,
73760
],
[
73800,
74000
],
[
74000,
74180
],
[
74180,
74280
],
[
74280,
74420
],
[
74420,
74659
]
],
'spk': 0
},
{
'text': '政府已经得出结论,',
'start': 75220,
'end': 77480,
'timestamp': [
[
75220,
75460
],
[
75500,
75740
],
[
75840,
76040
],
[
76040,
76280
],
[
76440,
76680
],
[
76700,
76940
],
[
77080,
77240
],
[
77240,
77480
]
],
'spk': 0
},
{
'text': '有必要扩大现有的特定半导体制造设备的出口管制。',
'start': 77800,
'end': 84415,
'timestamp': [
[
77800,
78040
],
[
78220,
78420
],
[
78420,
78660
],
[
78760,
79000
],
[
79080,
79320
],
[
79520,
79740
],
[
79740,
79980
],
[
79980,
80220
],
[
80320,
80560
],
[
80580,
80820
],
[
80860,
81060
],
[
81060,
81300
],
[
81300,
81540
],
[
82260,
82500
],
[
82560,
82760
],
[
82760,
82980
],
[
82980,
83160
],
[
83160,
83320
],
[
83320,
83520
],
[
83520,
83760
],
[
83820,
84000
],
[
84000,
84415
]
],
'spk': 0
}
]
}
]
实时模型
ASR
- iic/speech_paraformer-large_asr_nat-zh-cn-16k-common-vocab8404-online
- paraformer-zh-streaming
import soundfile
import os
from funasr import AutoModel
# 注:`chunk_size`为流式延时配置,`[0,10,5]`表示上屏实时出字粒度为`10*60=600ms`,未来信息为`5*60=300ms`。
# 每次推理输入为`600ms`(采样点数为`16000*0.6=960`),输出为对应文字,最后一个语音片段输入需要设置`is_final=True`来强制输出最后一个字。
chunk_size = [0, 10, 5] #[0, 10, 5] 600ms, [0, 8, 4] 480ms
encoder_chunk_look_back = 4 #number of chunks to lookback for encoder self-attention
decoder_chunk_look_back = 1 #number of encoder chunks to lookback for decoder cross-attention
model = AutoModel(
model="paraformer-zh-streaming",
device="mps",
disable_pbar=True,
)
wav_file = "wav/meeting.wav"
speech, sample_rate = soundfile.read(wav_file)
chunk_stride = chunk_size[1] * 960 # 600ms
cache = {}
for start in range(0, len(speech), chunk_stride):
end = start + chunk_stride
speech_chunk = speech[start : end]
# 是否是最后一个 chunk(end >= 总长度)
is_final = end >= len(speech)
res = model.generate(
input=speech_chunk,
cache=cache,
is_final=is_final,
chunk_size=chunk_size,
encoder_chunk_look_back=encoder_chunk_look_back,
decoder_chunk_look_back=decoder_chunk_look_back,
)
print(res)
[{'key': 'rand_key_2yW4Acq9GFz6Y', 'text': ''}]
[{'key': 'rand_key_1t9EwL56nGisi', 'text': ''}]
[{'key': 'rand_key_WgNZq6ITZM5jt', 'text': '格兰'}]
[{'key': 'rand_key_gUe52RvEJgwBu', 'text': '发布了'}]
[{'key': 'rand_key_NO6n9JEC3HqdZ', 'text': '一份'}]
[{'key': 'rand_key_6J6afU1zT0YQO', 'text': '主'}]
[{'key': 'rand_key_aNF03vpUuT3em', 'text': '题为'}]
[{'key': 'rand_key_6KopZ9jZICffu', 'text': '宣'}]
[{'key': 'rand_key_4G7FgtJsThJv0', 'text': '布即'}]
[{'key': 'rand_key_7In9ZMJLsCfMZ', 'text': '将'}]
[{'key': 'rand_key_yuKpslm0lcNQq', 'text': '对'}]
[{'key': 'rand_key_EefRWi4j7c1f5', 'text': '先进'}]
[{'key': 'rand_key_S71IRz1THrHZp', 'text': '半导体'}]
[{'key': 'rand_key_2n5RL08ALrCFQ', 'text': '制造'}]
[{'key': 'rand_key_PS6YwfuNhFLOv', 'text': '设备采'}]
[{'key': 'rand_key_2mpbUrhToxYkv', 'text': '取的'}]
[{'key': 'rand_key_B0dgYj2Soc0KO', 'text': '出'}]
[{'key': 'rand_key_67IMRebhOmM1K', 'text': '口管'}]
[{'key': 'rand_key_hzfx1hcMbm9lT', 'text': '制措施'}]
[{'key': 'rand_key_hEnUZd7RbIBNg', 'text': '的'}]
[{'key': 'rand_key_1qeoePtwBldGD', 'text': '公告表'}]
[{'key': 'rand_key_cMgSzmqw5UE15', 'text': '示'}]
[{'key': 'rand_key_6KkSRn9XdYRk2', 'text': '鉴'}]
[{'key': 'rand_key_kvHqhM6CQlaER', 'text': '于技'}]
[{'key': 'rand_key_A5K3G6tPwy1Qq', 'text': '术的发'}]
[{'key': 'rand_key_jJSaDVfvVcIri', 'text': '展和'}]
[{'key': 'rand_key_pW9EwNsRwL85O', 'text': '地缘'}]
[{'key': 'rand_key_2NiTtyVA1PfaM', 'text': '政治的'}]
[{'key': 'rand_key_mSvkpoOCyT4RK', 'text': '背景'}]
[{'key': 'rand_key_3Acz3SKAXQTck', 'text': '政'}]
[{'key': 'rand_key_CeqSkCH4F6JMW', 'text': '府已'}]
[{'key': 'rand_key_a4cFut1DdZ04Z', 'text': '经得'}]
[{'key': 'rand_key_AmJ9Of1Uiaz8R', 'text': '出结论'}]
[{'key': 'rand_key_AuanaTWa0RHNg', 'text': ''}]
[{'key': 'rand_key_mhMPm3trSlgE2', 'text': '有必'}]
[{'key': 'rand_key_7zOfbr6CZYh3q', 'text': '要扩'}]
[{'key': 'rand_key_iPH0PPwh3jr2b', 'text': '大现'}]
[{'key': 'rand_key_ccnRqJu8x8K62', 'text': '有的'}]
[{'key': 'rand_key_c2V9SMPFTP5DO', 'text': '特定'}]
[{'key': 'rand_key_Bx3IlnyLsaijr', 'text': '半导体'}]
[{'key': 'rand_key_vvYxTfvXNccrk', 'text': ''}]
[{'key': 'rand_key_jLsxzJishEUp7', 'text': '制造'}]
[{'key': 'rand_key_dtl2HUetz1vtA', 'text': '设备的'}]
[{'key': 'rand_key_ggJ6EEv1ZZvhE', 'text': '出口管'}]
[{'key': 'rand_key_hSFBctvVR5j6k', 'text': '制'}]
[{'key': 'rand_key_OKyZOfeZfmVod', 'text': ''}]
[{'key': 'rand_key_yagzJHsC6FYLT', 'text': ''}]
[{'key': 'rand_key_RnBfxoqLXkBmw', 'text': ''}]
[{'key': 'rand_key_he032Sb5HCWRm', 'text': ''}]
[{'key': 'rand_key_hFzqnPc8ZnNjg', 'text': ''}]
[{'key': 'rand_key_mDyxI0jgMFjKz', 'text': ''}]
[{'key': 'rand_key_ORB4HFR64u1FF', 'text': ''}]
[{'key': 'rand_key_OQ3mIN7oavT9V', 'text': ''}]
[{'key': 'rand_key_5u0ucHj3qMYj1', 'text': '欢'}]
[{'key': 'rand_key_yLsTTZEeZfH36', 'text': '迎大'}]
[{'key': 'rand_key_ceoictaW2Cv3k', 'text': '家来体'}]
[{'key': 'rand_key_Zj3PD9xGy5HGc', 'text': '验达摩'}]
[{'key': 'rand_key_KfRYZHWMeVB5W', 'text': '院推出'}]
[{'key': 'rand_key_nsI5MA0E2YyML', 'text': '的语'}]
[{'key': 'rand_key_o23ZbQ4aVltGK', 'text': '音识别'}]
[{'key': 'rand_key_qveF3q80tXAyZ', 'text': '模型'}]
[{'key': 'rand_key_ydkP7ipsU1vd8', 'text': ''}]
[{'key': 'rand_key_cEAjF43MTfRSj', 'text': ''}]
[{'key': 'rand_key_ZwAcNDyDdgEXj', 'text': ''}]
[{'key': 'rand_key_bcMNiOugSJPwm', 'text': ''}]
[{'key': 'rand_key_yYXXFh4dNSDNO', 'text': ''}]
[{'key': 'rand_key_7vPhRTNsY2i96', 'text': 'i'}]
[{'key': 'rand_key_yZs6V39RZhH3Y', 'text': 'ard that you can'}]
[{'key': 'rand_key_mcYzCxWmDwYOe', 'text': 'stand'}]
[{'key': 'rand_key_9c57cFq5b8HQK', 'text': 'what people'}]
[{'key': 'rand_key_K4nofX044OXGS', 'text': 'say and even'}]
[{'key': 'rand_key_HAGt8hjB5KB7f', 'text': 'know they'}]
[{'key': 'rand_key_7gAegAXjU9bYC', 'text': 'are'}]
[{'key': 'rand_key_BRAbF639uUqfw', 'text': 'age and'}]
[{'key': 'rand_key_ehwSbwwla1o0x', 'text': ''}]
[{'key': 'rand_key_eM5jnanQRU85h', 'text': 'der so can'}]
[{'key': 'rand_key_VasxSb7Mo2jlD', 'text': 'you guess'}]
[{'key': 'rand_key_hEwT9qib9nxvE', 'text': 'my age'}]
[{'key': 'rand_key_9ss749JOulLfg', 'text': 'and gender'}]
[{'key': 'rand_key_ILtky5j8iZouG', 'text': 'from my'}]
[{'key': 'rand_key_ppWlsxAQc3iMb', 'text': ''}]
[{'key': 'rand_key_zeSeiAtJAV7jL', 'text': ''}]
[{'key': 'rand_key_BtOwfpCOxO8Hd', 'text': ''}]
[{'key': 'rand_key_yAaA9U5uCnxs8', 'text': 'ice'}]
[{'key': 'rand_key_Ef8lYgrhJMSjY', 'text': '你好'}]
[{'key': 'rand_key_SC7zlXABlp9Dv', 'text': '欢迎'}]
[{'key': 'rand_key_7HjwDOOfEWnsa', 'text': '使用百'}]
[{'key': 'rand_key_1SCNDanthXOtI', 'text': '度飞桨'}]
[{'key': 'rand_key_MjBTWEfRFW9oI', 'text': '深度学习'}]
[{'key': 'rand_key_WzrObhr4Qcaqz', 'text': '框'}]
[{'key': 'rand_key_H4LTzCgVqws3W', 'text': ''}]
[{'key': 'rand_key_R6mMfceYqtIvh', 'text': ''}]
[{'key': 'rand_key_H3p56WkeA3ssH', 'text': ''}]
[{'key': 'rand_key_iKHOnIgA9OIzV', 'text': ''}]
[{'key': 'rand_key_X5YrsCxKOikhS', 'text': ''}]
[{'key': 'rand_key_hyzLDiJQtwOEV', 'text': ''}]
[{'key': 'rand_key_AnEFSGuFP9dCt', 'text': ''}]
[{'key': 'rand_key_jVFd4NnbwEz4a', 'text': ''}]
[{'key': 'rand_key_2HeR3fR8V7Qza', 'text': '架格'}]
[{'key': 'rand_key_xchNar3OSsU5o', 'text': '兰发'}]
[{'key': 'rand_key_jWKsmgBDTvykv', 'text': '布了一'}]
[{'key': 'rand_key_AP5RBjC7TjHui', 'text': '份主'}]
[{'key': 'rand_key_n6lCwYyBZFyUo', 'text': '题为'}]
[{'key': 'rand_key_YmC8nLTd5ycoO', 'text': ''}]
[{'key': 'rand_key_f3lxdVORloNtN', 'text': '宣布'}]
[{'key': 'rand_key_fT3GWsX44wADd', 'text': '即将'}]
[{'key': 'rand_key_OSHQ9P9J7V7BL', 'text': '对'}]
[{'key': 'rand_key_DFqTEnvrccdkw', 'text': '先进'}]
[{'key': 'rand_key_asPaieYBRoMzJ', 'text': '半导'}]
[{'key': 'rand_key_6oDmvMgM4fYuu', 'text': '体制造'}]
[{'key': 'rand_key_ID5uqbHcmxfn3', 'text': '设备'}]
[{'key': 'rand_key_Hwm1mqRUVttH3', 'text': '采取'}]
[{'key': 'rand_key_yqEw3Tpct7Jea', 'text': '的'}]
[{'key': 'rand_key_DFUCd6ZAFDChf', 'text': '出口'}]
[{'key': 'rand_key_fpg0WjA46nCNe', 'text': '管制措'}]
[{'key': 'rand_key_0BJW41zc9lpFo', 'text': '施'}]
[{'key': 'rand_key_i13r7wuBgJ5sN', 'text': '的公告'}]
[{'key': 'rand_key_IYmTsXCGMDIOq', 'text': '表示'}]
[{'key': 'rand_key_robhNYTglUApn', 'text': ''}]
[{'key': 'rand_key_s4VQaVIGB2dhy', 'text': '鉴于'}]
[{'key': 'rand_key_PrhVKwoRTTIQs', 'text': '技术的'}]
[{'key': 'rand_key_oV15peHtRuoxO', 'text': '发展'}]
[{'key': 'rand_key_EsLkiZaJGuxLO', 'text': '和地'}]
[{'key': 'rand_key_bZi4zjlGeiWnY', 'text': '缘政治'}]
[{'key': 'rand_key_6XFKXSnpUi0oW', 'text': '的背景'}]
[{'key': 'rand_key_ywMLiOF56gN1b', 'text': ''}]
[{'key': 'rand_key_HMwFDta9oJPkQ', 'text': '政府'}]
[{'key': 'rand_key_4FZ9VEIuT2fqi', 'text': '已经'}]
[{'key': 'rand_key_MzTm0uYsy8dnc', 'text': '得出'}]
[{'key': 'rand_key_uUV9pv3CQUQQo', 'text': '结论'}]
[{'key': 'rand_key_qwQktbwKIdUOj', 'text': '有'}]
[{'key': 'rand_key_wbFOdbpcao8Pu', 'text': '必要'}]
[{'key': 'rand_key_e0dwQBi57nCBj', 'text': '扩大'}]
[{'key': 'rand_key_wtlPvUYVAyaA5', 'text': '现有'}]
[{'key': 'rand_key_qIIZVRTDWcK6h', 'text': '的特'}]
[{'key': 'rand_key_A9ykaGiN3QG1U', 'text': '定半导'}]
[{'key': 'rand_key_Sjfvp110lp8b9', 'text': '体'}]
[{'key': 'rand_key_Z5kVY1RJkTfB7', 'text': '制'}]
[{'key': 'rand_key_3MgNODTjNMcqv', 'text': '造设备'}]
[{'key': 'rand_key_ZVUybO74cFfws', 'text': '的出'}]
[{'key': 'rand_key_QjDpGwkVWzvrZ', 'text': '口管制'}]
[{'key': 'rand_key_F8zatH5sJEcXI', 'text': ''}]
VAD (fsmn-vad)
from funasr import AutoModel
import soundfile as sf
# 流式 VAD chunk 大小(毫秒)
chunk_size = 200 # e.g. 200ms
# 加载 VAD 模型
model = AutoModel(
model="fsmn-vad",
device="mps",
disable_pbar=True,
)
# 读取测试 wav
wav_file = "wav/meeting.wav"
speech, sample_rate = sf.read(wav_file)
# 如果是多通道(双声道),自动转单通道
if speech.ndim > 1:
speech = speech.mean(axis=1)
# 计算每个 chunk 对应的采样点数
chunk_stride = int(chunk_size * sample_rate / 1000)
if chunk_stride <= 0:
raise ValueError("chunk_stride must be > 0")
# 流式缓存
cache = {}
for start in range(0, len(speech), chunk_stride):
end = start + chunk_stride
speech_chunk = speech[start:end]
# 是否为最后一个 chunk
is_final = end >= len(speech)
# 推理(实时 VAD)
res = model.generate(
input=speech_chunk,
cache=cache,
is_final=is_final,
chunk_size=chunk_size, # 单位为 ms
)
if len(res[0]["value"]):
print(res)
[{'key': 'rand_key_NO6n9JEC3HqdZ', 'value': [[500, -1]]}]
[{'key': 'rand_key_Z5kVY1RJkTfB7', 'value': [[-1, 26910]]}]
[{'key': 'rand_key_uftbFaWqmWzyB', 'value': [[31730, -1]]}]
[{'key': 'rand_key_4ORzcopOsvk9p', 'value': [[-1, 36550]]}]
[{'key': 'rand_key_qlULusyOcsJBc', 'value': [[39220, -1]]}]
[{'key': 'rand_key_DyRmAFmkzdY8Z', 'value': [[-1, 48160]]}]
[{'key': 'rand_key_7z8DTIn5xTcbz', 'value': [[49880, -1]]}]
[{'key': 'rand_key_O2re3QuuJPsdY', 'value': [[-1, 53790]]}]
[{'key': 'rand_key_D6PHdYUm9qDSe', 'value': [[58350, -1]]}]
[{'key': 'rand_key_tpKSfjMz2X9xV', 'value': [[-1, 84770]]}]
离线模型
语音识别
Fun-ASR-Nano-2512
不需要搭配标点恢复模型(
PUNC);可以和端点检测模型(VAD)一块使用;不可以和说话人分离模型(SV)一块使用。
- 安装更新 FunASR 库
pip install -U funasr torch torchaudio
- 下载
model.py文件wget https://raw.githubusercontent.com/FunAudioLLM/Fun-ASR/refs/heads/main/model.py
from funasr import AutoModel
# 中文、英文、日文 for Fun-ASR-Nano-2512
# 中文、英文、粤语、日文、韩文、越南语、印尼语、泰语、马来语、菲律宾语、阿拉伯语、
# 印地语、保加利亚语、克罗地亚语、捷克语、丹麦语、荷兰语、爱沙尼亚语、芬兰语、希腊语、
# 匈牙利语、爱尔兰语、拉脱维亚语、立陶宛语、马耳他语、波兰语、葡萄牙语、罗马尼亚语、
# 斯洛伐克语、斯洛文尼亚语、瑞典语 for Fun-ASR-MLT-Nano-2512
model_dir = "FunAudioLLM/Fun-ASR-Nano-2512"
model = AutoModel(
model=model_dir,
device="mps",
disable_update=True,
disable_pbar=True,
trust_remote_code=True,
remote_code="./model.py",
)
wav_path = "meeting.wav"
res = model.generate(
input=[wav_path],
cache={},
batch_size=1,
)
text = res[0]["text"]
print(text)
参数说明:
model_dir: 模型名称或本地磁盘上的模型路径。trust_remote_code: 是否信任远程代码以加载自定义模型实现。remote_code: 指定特定模型代码的位置(例如当前目录中的model.py),支持绝对路径和相对路径。device: 指定使用的设备,如 “cuda:0”、”cpu” 或 “mps”。
格兰发布了一份主题为“宣布即将对先进半导体制造设备采取的出口管制”措施的公告,表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。欢迎大家来体验达摩院推出的语音识别模型。I heard that you can understand what people say and even know their age and gender,so can you guess my age and gender from my voice?你好,欢迎使用百度飞桨深度学习框架。格兰发布了一份主题为“宣布即将对先进半导体制造设备采取的出口管制”措施的公告,表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。
from funasr import AutoModel
model_dir = "FunAudioLLM/Fun-ASR-Nano-2512"
model = AutoModel(
model=model_dir,
device="mps",
disable_update=True,
disable_pbar=True,
trust_remote_code=True,
remote_code="./model.py",
)
wav_path = "meeting.wav"
res = model.generate(
input=[wav_path],
cache={},
batch_size=1,
hotwords=["荷兰"],
language="中文",
itn=True, # or False
)
text = res[0]["text"]
print(text)
荷兰发布了一份主题为“宣布即将对先进半导体制造设备采取的出口管制”措施的公告,表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。欢迎大家来体验达摩院推出的语音识别模型。I heard that you can understand what people say and even know their age and gender. So can you guess my age and gender from my voice? 你好,欢迎使用百度飞桨深度学习框架。荷兰发布了一份主题为“宣布即将对先进半导体制造设备采取的出口管制”措施的公告,表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。
ASR & VAD
from funasr import AutoModel
model_dir = "FunAudioLLM/Fun-ASR-Nano-2512"
model = AutoModel(
model=model_dir,
vad_model="fsmn-vad",
vad_kwargs={"max_single_segment_time": 30000},
device="mps",
disable_update=True,
disable_pbar=True,
trust_remote_code=True,
remote_code="./model.py",
)
wav_path = "meeting.wav"
res = model.generate(
input=[wav_path],
cache={},
batch_size=1,
hotwords=["荷兰"],
language="中文",
itn=True, # or False
)
text = res[0]["text"]
print(text)
SenseVoiceSmall
from funasr import AutoModel
model_dir = "iic/SenseVoiceSmall"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
device="mps",
)
wav_file = "wav/meeting.wav"
res = model.generate(
input=wav_file,
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
merge_vad=True,
merge_length_s=15,
)
print(res)
参数说明:
model_dir:模型名称,或本地磁盘中的模型路径。vad_model:表示开启VAD,VAD的作用是将长音频切割成短音频,此时推理耗时包括了VAD与SenseVoice总耗时,为链路耗时,如果需要单独测试SenseVoice模型耗时,可以关闭VAD模型。vad_kwargs:表示VAD模型配置,max_single_segment_time: 表示vad_model最大切割音频时长, 单位是毫秒ms。use_itn:输出结果中是否包含标点与逆文本正则化。batch_size_s表示采用动态batch,batch中总音频时长,单位为秒s。merge_vad:是否将 vad 模型切割的短音频碎片合成,合并后长度为merge_length_s,单位为秒s。ban_emo_unk:禁用emo_unk标签,禁用后所有的句子都会被赋与情感标签。
[
{
'key': 'meeting',
'text': '<|zh|><|NEUTRAL|><|Speech|><|withitn|>格兰发布了一份主题为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,于技术的发地缘政治的背景已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。欢迎大家达摩院推出的语音识别模型欢迎使用百度非讲深度学框架。格兰发布了一份主题为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,鉴于技术的发展和地缘政治的背景。政府已经得出结论,有必要扩大现有的特定半导体,制造设备的出口管制。'
}
]
❌ 未能识别出:I heard that you can understand what people say and even know their age and gender. So can you guess my age and gender from my voice? 你好,欢迎使用百度飞桨深度学习框架。
paraformer-zh
from funasr import AutoModel
model_dir = "paraformer-zh"
model = AutoModel(
model=model_dir,
trust_remote_code=True,
device="mps",
)
wav_file = "wav/meeting.wav"
res = model.generate(
input=wav_file,
cache={},
language="auto", # "zh", "en", "yue", "ja", "ko", "nospeech"
use_itn=True,
batch_size_s=60,
)
print(res)
[
{
'key': 'meeting',
'text': '格 兰 发 布 了 一 份 主 题 为 宣 布 即 将 对 先 进 半 导 体 制 造 设 备 采 取 的 制 口 管 制 措 施 的 公 告 表 示 鉴 于 技 术 的 发 展 和 地 缘 政 治 的 背 景 政 府 已 经 得 出 结 论 有 必 要 扩 大 现 有 的 特 定 半 导 体 制 造 设 备 的 出 口 管 制 欢 迎 大 家 来 体 验 达 摩 院 推 出 的 语 音 识 别 模 型 i heard that you can understand 的 报 告 示 迎 即 将 a agent der so 欢 迎 guess my agent gender from my voice 你 好 欢 迎 使 用 百 度 飞 桨 深 度 学 习 框 架 格 兰 发 布 了 一 份 儿 主 题 为 宣 布 即 将 对 先 进 半 导 体 制 造 设 备 采 取 的 出 口 管 制 措 施 的 公 告 表 示 鉴 于 技 术 的 发 展 和 地 缘 政 治 的 背 景 政 府 已 经 得 出 结 论 有 必 要 扩 大 现 有 的 特 定 半 导 体 制 造 设 备 的 出 口 管 制',
'timestamp': [
[
790,
1030
],
...
[
71130,
71635
]
]
}
]
Qwen-Audio-Chat
使用
FunASR库来推理失败 ❌,提示模型列表不支持。已安装pip install -U "funasr[llm]
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation import GenerationConfig
import torch
torch.manual_seed(1234)
# Note: The default behavior now has injection attack prevention off.
tokenizer = AutoTokenizer.from_pretrained("Qwen/Qwen-Audio-Chat", trust_remote_code=True)
# use bf16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-Audio-Chat", device_map="auto", trust_remote_code=True, bf16=True).eval()
# use fp16
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-Audio-Chat", device_map="auto", trust_remote_code=True, fp16=True).eval()
# use cpu only
# model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-Audio-Chat", device_map="cpu", trust_remote_code=True).eval()
# use cuda device
model = AutoModelForCausalLM.from_pretrained("Qwen/Qwen-Audio-Chat", device_map="mps", trust_remote_code=True).eval()
# Specify hyperparameters for generation (No need to do this if you are using transformers>4.32.0)
# model.generation_config = GenerationConfig.from_pretrained("Qwen/Qwen-Audio-Chat", trust_remote_code=True)
# 1st dialogue turn
query = tokenizer.from_list_format([
{'audio': 'wav/test.wav'}, # Either a local path or an url
{'text': '输出音频文本。'},
])
response, history = model.chat(tokenizer, query=query, history=None)
print(response)
# 2nd dialogue turn
response, history = model.chat(tokenizer, '对音频文本进行校正。', history=history)
print(response)
好的,这是音频文本:"格兰发布了一份主题为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示鉴于技术的发展和地缘政治的背景政府已经得出结论有必要扩大现有的特定半导体制造设备的出口管制"。
好的,这是校正后的音频文本:"格兰发布了一份主题为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示鉴于技术的发展和地缘政治的背景政府已经得出结论有必要扩大现有的特定半导体制造设备的出口管制"。
Whisper-large-v3-turbo
在 MacOS 上没有成功验证,CPU 超级 超级 🐢🐢🐢🐢🐢,GPU 直接崩溃 ❌。
需要安装 pip install openai-whisper
语音端点检测 (fsmn-vad)
from funasr import AutoModel
model = AutoModel(model="fsmn-vad")
wav_file = "wav/meeting.wav"
res = model.generate(input=wav_file)
print(res)
[{'key': 'meeting', 'value': [[500, 26910], [27550, 32370], [32810, 45170], [45560, 71970]]}]
标点恢复 (ct-punc)
from funasr import AutoModel
model = AutoModel(model="ct-punc")
res = model.generate(input="格 兰 发 布 了 一 份 主 题 为 宣 布 即 将 对 先 进 半 导 体 制 造 设 备 采 取 的 制 口 管 制 措 施 的 公 告 表 示 鉴 于 技 术 的 发 展 和 地 缘 政 治 的 背 景 政 府 已 经 得 出 结 论 有 必 要 扩 大 现 有 的 特 定 半 导 体 制 造 设 备 的 出 口 管 制 欢 迎 大 家 来 体 验 达 摩 院 推 出 的 语 音 识 别 模 型 i heard that you can understand 的 报 告 示 迎 即 将 a agent der so 欢 迎 guess my agent gender from my voice 你 好 欢 迎 使 用 百 度 飞 桨 深 度 学 习 框 架 格 兰 发 布 了 一 份 儿 主 题 为 宣 布 即 将 对 先 进 半 导 体 制 造 设 备 采 取 的 出 口 管 制 措 施 的 公 告 表 示 鉴 于 技 术 的 发 展 和 地 缘 政 治 的 背 景 政 府 已 经 得 出 结 论 有 必 要 扩 大 现 有 的 特 定 半 导 体 制 造 设 备 的 出 口 管 制")
print(res)
[
{
'key': 'rand_key_2yW4Acq9GFz6Y',
'text': '格兰发布了一份主题,为宣布即将对先进半导体制造设备采取的制口管制措施的公告表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。欢迎大家来体验达摩院推出的语音识别模型。 I heard that you can understand的报告示迎即将a agent der, so欢迎guess my agent gender from my voice.你好,欢迎使用百度飞桨深度学习框架。格兰发布了一份儿主题,为宣布即将对先进半导体制造设备采取的出口管制措施的公告表示,鉴于技术的发展和地缘政治的背景,政府已经得出结论,有必要扩大现有的特定半导体制造设备的出口管制。',
'punc_array': tensor([
1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 3, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1,
1, 1, 1, 1, 1, 1, 1, 3, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3,
1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 2, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 3
])
}
]
逆文本正则化 (fst_itn_zh)
from itn.chinese.inverse_normalizer import InverseNormalizer
invnormalizer = InverseNormalizer(cache_dir="./itn")
result = invnormalizer.normalize("二点五平方电线")
print(result)
2.5平方电线
时间戳预测 (fa-zh)
from funasr import AutoModel
model = AutoModel(model="fa-zh")
wav_file = f"{model.model_path}/example/asr_example.wav"
text_file = f"{model.model_path}/example/text.txt"
res = model.generate(input=(wav_file, text_file), data_type=("sound", "text"))
print(res)
[
{
'key': 'rand_key_2yW4Acq9GFz6Y',
'text': '欢 迎 大 家 来 到 魔 搭 社 区 进 行 体 验',
'timestamp': [
[1190, 1410], [1410, 1610], [1610, 1830], [1830, 2010], [2010, 2230], [2230, 2430], [2430, 2650], [2650, 2890], [2890, 3130], [3130, 3370], [3410, 3650], [3690, 3930], [3950, 4190], [4230, 4395]
]
}
]
情感识别 (emotion2vec_plus_large)
from funasr import AutoModel
model = AutoModel(model="emotion2vec_plus_large")
wav_file = f"{model.model_path}/example/test.wav"
res = model.generate(wav_file, output_dir="./outputs", granularity="utterance", extract_embedding=False)
print(res)
[
{
'key': 'test',
'labels': [
'生气/angry',
'厌恶/disgusted',
'恐惧/fearful',
'开心/happy',
'中立/neutral',
'其他/other',
'难过/sad',
'吃惊/surprised',
'<unk>'
],
'scores': [
1.0,
4.307111958756771e-12,
7.651635401673129e-12,
1.8212450991761386e-10,
7.213086378188294e-11,
1.3731805914519914e-14,
9.798567512930845e-11,
8.913384474951158e-10,
5.704838502579487e-21
]
}
]
语音唤醒 (iic/speech_charctc_kws_phone-xiaoyun)
from funasr import AutoModel
model = AutoModel(
model="iic/speech_charctc_kws_phone-xiaoyun",
keywords="小云小云",
output_dir="./outputs/debug",
)
# test_wav = "https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/KWS/pos_testset/kws_xiaoyunxiaoyun.wav"
test_wav = "wav/test.wav"
res = model.generate(input=test_wav, cache={},)
print(res)
- kws_xiaoyunxiaoyun.wav
[{'key': 'kws_xiaoyunxiaoyun', 'text': 'detected 小云小云 0.9954625458116295'}]
- test.wav
[{'key': 'test', 'text': 'rejected'}]
说话人确认 (iic/speech_campplus_sv_zh-cn_16k-common)
提取说话人声纹
声纹是什么?
声纹是一种说话人特征向量,它包含了语音中能够唯一标识说话人身份的特征,包含音色、音调、发音习惯等综合信息。就像指纹或虹膜一样,每个人的声纹都是独特的。
from funasr import AutoModel
model = AutoModel(
model="iic/speech_campplus_sv_zh-cn_16k-common",
disable_pbar=True,
disable_update=True,
)
res = model.generate(
input="https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/asr_example_zh.wav"
)
print(res)
print(res[0]['spk_embedding'].shape)
[{'spk_embedding': tensor([[-0.7695, 0.9301, -0.3387, -0.2433, -1.7098, 0.2449, -0.9042, 0.0154,
-1.4747, 1.1582, 0.0962, 0.4708, -0.4707, -0.1772, -0.0746, -0.2793,
-0.0782, 0.8927, -0.1124, 0.8741, 0.1740, -1.1813, 0.3146, 2.3054,
-0.1995, -0.4555, -0.8218, 0.1201, 0.2941, -0.4945, 0.1232, 0.1772,
1.6506, 0.6197, -0.3646, -0.6890, 0.9276, -0.0908, 2.0183, 1.2833,
-0.5604, 0.8838, 0.0284, -0.6835, -0.1514, 1.0652, 0.1939, -1.0589,
-0.2669, 0.9432, -1.2874, 0.5833, 1.5452, -0.0106, 0.2919, 1.1925,
1.3049, -0.2770, 0.9102, 0.1262, 1.0301, -0.1749, 0.1931, -1.9403,
1.4445, 2.2689, 1.4897, -0.4163, -1.3161, -0.0405, -0.1087, -1.2678,
-1.3225, 0.1088, -0.5461, 0.5921, -0.6173, -0.8690, -0.5573, 0.0105,
0.0817, 0.7311, -1.4333, 0.0363, -0.6978, -1.3585, -0.1253, -0.0536,
2.4604, -0.1948, 0.1687, -0.1148, 0.3924, -0.0933, -1.1472, 1.7566,
-0.2964, 0.2611, 1.2891, -1.9203, -0.5743, -0.3957, -0.2540, 0.0266,
-1.8311, -0.4786, 1.1606, 1.6374, 0.2868, -1.3295, 0.3058, 0.4059,
0.5929, -1.5850, 0.5731, -0.9439, -0.2294, 1.2431, 1.9116, -0.0431,
-0.6389, 0.3469, 0.6896, -1.6073, -0.6667, -0.0749, -0.8974, 0.8099,
0.5091, 0.7440, 0.5741, -0.0752, -0.8104, -0.1394, -0.6335, 0.5255,
1.5194, 0.2834, -0.1620, 0.9866, 0.4027, -1.5849, 0.1991, 1.2374,
-1.2397, -0.6116, 0.0415, -0.1860, -0.5082, 0.4865, -0.2256, -0.8089,
0.9281, -1.5008, -0.3342, 0.2433, -1.2234, 1.3291, 1.1277, -0.3685,
1.5369, 1.7379, -1.0607, 0.9092, -0.1880, 0.9070, -0.1833, -1.1448,
-0.0639, 0.1507, -0.0894, 1.1152, -0.8903, 0.1557, -1.0404, -0.2521,
-1.4380, -1.6033, 0.2485, 0.7856, -0.0065, 0.0115, 0.5793, -0.2226,
-0.3501, -0.2113, 0.2558, 0.4537, 1.1283, 0.6597, 1.1584, 0.6156]])}]
torch.Size([1, 192])
说话人验证与确认
import numpy as np
import torch
import torch.nn.functional as F
from funasr import AutoModel
import warnings
warnings.filterwarnings('ignore')
# 初始化模型
model = AutoModel(
model="iic/speech_campplus_sv_zh-cn_16k-common",
disable_pbar=True,
disable_update=True,
)
def extract_speaker_embedding(audio_path):
"""提取音频的说话人嵌入向量"""
res = model.generate(input=audio_path)
embedding = res[0]['spk_embedding']
# 归一化处理(通常余弦相似度需要归一化向量)
embedding = F.normalize(embedding, p=2, dim=1)
return embedding.squeeze().numpy() # 转换为numpy数组
def calculate_cosine_similarity(emb1, emb2):
"""计算两个嵌入向量的余弦相似度"""
# 确保向量是1维的
emb1 = emb1.flatten()
emb2 = emb2.flatten()
# 计算余弦相似度
similarity = np.dot(emb1, emb2) / (np.linalg.norm(emb1) * np.linalg.norm(emb2))
return similarity
def compare_speakers(audio_paths):
"""比较多个音频的说话人相似度"""
embeddings = []
print("提取说话人特征...")
for i, path in enumerate(audio_paths):
embedding = extract_speaker_embedding(path)
embeddings.append(embedding)
print(f"音频{i+1}: {path}")
print(f" 特征向量维度: {embedding.shape}")
print(f" 特征范数: {np.linalg.norm(embedding):.4f}")
print("\n说话人相似度矩阵:")
n = len(audio_paths)
similarity_matrix = np.zeros((n, n))
for i in range(n):
for j in range(n):
similarity = calculate_cosine_similarity(embeddings[i], embeddings[j])
similarity_matrix[i, j] = similarity
# 打印相似度矩阵
for i in range(n):
row = [f"{similarity_matrix[i, j]:.4f}" for j in range(n)]
print(f"音频{i+1}: " + " ".join(row))
return embeddings, similarity_matrix
def speaker_verification(enrollment_audio, test_audio, threshold=0.5):
"""说话人验证:判断测试音频是否与注册音频来自同一说话人"""
print("=== 说话人验证 ===")
print(f"注册音频: {enrollment_audio}")
print(f"测试音频: {test_audio}")
# 提取特征
emb1 = extract_speaker_embedding(enrollment_audio)
emb2 = extract_speaker_embedding(test_audio)
# 计算相似度
similarity = calculate_cosine_similarity(emb1, emb2)
print(f"余弦相似度: {similarity:.4f}")
print(f"阈值: {threshold}")
# 判断是否为同一说话人
if similarity >= threshold:
print("结果: ✅ 同一说话人")
return True, similarity
else:
print("结果: ❌ 不同说话人")
return False, similarity
def speaker_identification(enrollment_embeddings_dict, test_audio):
"""说话人识别:从已知说话人中识别测试音频的说话人"""
print("=== 说话人识别 ===")
print(f"测试音频: {test_audio}")
# 提取测试音频特征
test_emb = extract_speaker_embedding(test_audio)
best_match = None
best_similarity = -1
# 与所有注册说话人比较
for speaker_id, enrollment_emb in enrollment_embeddings_dict.items():
similarity = calculate_cosine_similarity(enrollment_emb, test_emb)
print(f"与说话人 '{speaker_id}' 的相似度: {similarity:.4f}")
if similarity > best_similarity:
best_similarity = similarity
best_match = speaker_id
print(f"\n识别结果: 说话人 '{best_match}' (相似度: {best_similarity:.4f})")
return best_match, best_similarity
if __name__ == "__main__":
# 示例音频URL
audio_urls = [
"https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav",
# "https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_same.wav",
"https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_different.wav",
]
# 1. 比较多个音频的相似度
print("1. 多音频说话人比较")
print("=" * 50)
embeddings, similarity_matrix = compare_speakers(audio_urls[:2]) # 先比较前两个
# 2. 说话人验证示例
print("\n" + "=" * 50)
print("2. 说话人验证示例")
print("=" * 50)
# 假设第一个音频是注册音频,第二个是测试音频
is_same, similarity = speaker_verification(
enrollment_audio=audio_urls[0],
test_audio=audio_urls[1],
threshold=0.5
)
# 3. 说话人识别示例
print("\n" + "=" * 50)
print("3. 说话人识别示例")
print("=" * 50)
# 创建注册说话人数据库
enrollment_database = {
"speaker_zhangsan": embeddings[0], # 第一个音频作为张三的注册
# "speaker_lisi": some_other_embedding, # 可以添加更多说话人
}
# 进行说话人识别
identified_speaker, top_similarity = speaker_identification(
enrollment_embeddings_dict=enrollment_database,
test_audio=audio_urls[0] # 使用第一个音频作为测试
)
# 4. 高级分析:阈值选择建议
print("\n" + "=" * 50)
print("4. 阈值选择分析")
print("=" * 50)
# 模拟不同阈值下的性能
thresholds = [0.3, 0.4, 0.5, 0.6, 0.7]
for thresh in thresholds:
is_same, sim = speaker_verification(
audio_urls[0],
audio_urls[1],
threshold=thresh
)
- 特征维度: 每个音频提取192维的说话人嵌入向量
- 相似度计算: 使用余弦相似度,范围[-1, 1],值越大表示越相似
- 归一化: 特征向量通常需要L2归一化
- 阈值:
- 一般阈值设为0.5左右
- 具体阈值需要根据实际数据调整
- 同一说话人不同音频通常>0.7
- 不同说话人通常<0.3
1. 多音频说话人比较
==================================================
提取说话人特征...
音频1: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav
特征向量维度: (192,)
特征范数: 1.0000
音频2: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_different.wav
特征向量维度: (192,)
特征范数: 1.0000
说话人相似度矩阵:
音频1: 1.0000 0.0699
音频2: 0.0699 1.0000
==================================================
2. 说话人验证示例
==================================================
=== 说话人验证 ===
注册音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav
测试音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_different.wav
余弦相似度: 0.0699
阈值: 0.5
结果: ❌ 不同说话人
==================================================
3. 说话人识别示例
==================================================
=== 说话人识别 ===
测试音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav
与说话人 'speaker_zhangsan' 的相似度: 1.0000
识别结果: 说话人 'speaker_zhangsan' (相似度: 1.0000)
==================================================
4. 阈值选择分析
==================================================
=== 说话人验证 ===
注册音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav
测试音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_different.wav
余弦相似度: 0.0699
阈值: 0.3
结果: ❌ 不同说话人
=== 说话人验证 ===
注册音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav
测试音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_different.wav
余弦相似度: 0.0699
阈值: 0.4
结果: ❌ 不同说话人
=== 说话人验证 ===
注册音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav
测试音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_different.wav
余弦相似度: 0.0699
阈值: 0.5
结果: ❌ 不同说话人
=== 说话人验证 ===
注册音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav
测试音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_different.wav
余弦相似度: 0.0699
阈值: 0.6
结果: ❌ 不同说话人
=== 说话人验证 ===
注册音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav
测试音频: https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_different.wav
余弦相似度: 0.0699
阈值: 0.7
结果: ❌ 不同说话人
应用实践
| 应用 | 模型 | 性能 |
|---|---|---|
| 实时语音识别 | Gemini3 | 🚀🚀🚀🚀🚀 |
| Qwen3 | 🚀🚀🚀🚀 | |
| 混元 | 🚀🚀🚀🚀 | |
| Kimi | 🚀🚀🚀 | |
| LongCat | 🚀🚀🚀 | |
| DeepSeek | 🚀🚀🚀 | |
| 豆包 | 🚀🚀 | |
| GPT-5 | 🚀🚀 |
实时语音识别
Gemini3-Flash
import sys
import numpy as np
import soundfile as sf
import sounddevice as sd
from funasr import AutoModel
class RealTimeASR:
"""
FunASR 实时语音转录(ASR)核心类。
支持流式处理语音数据并实时输出转录文本。
"""
def __init__(self, model_name="paraformer-zh-streaming", chunk_size_ms=600, device="cpu"):
"""
初始化 ASR 模型。
:param model_name: FunASR 模型名称。
:param chunk_size_ms: 每块语音数据的大小(毫秒),用于实时推理。
:param device: 推理设备(如 "cpu", "cuda", "mps")。
"""
# 模型参数 (来自您的示例)
# chunk_size=[0, 10, 5] -> 10 * 60ms = 600ms
chunk_len_ms = chunk_size_ms / 60
self.chunk_size = [0, int(chunk_len_ms), int(chunk_len_ms / 2)]
self.encoder_chunk_look_back = 4
self.decoder_chunk_look_back = 1
# 采样率和缓存
self.sample_rate = 16000
self.cache = {}
print(f"Loading ASR model: {model_name} on {device}...")
self.model = AutoModel(
model=model_name,
device=device,
disable_pbar=True,
disable_update=True,
)
print("Model loaded successfully.")
# 采样点数计算
self.chunk_stride_samples = int(self.chunk_size[1] * self.sample_rate * 0.06) # 60ms * 10 = 600ms
def reset_cache(self):
"""重置流式缓存,用于开始新的语音输入。"""
self.cache = {}
def process_chunk(self, speech_chunk: np.ndarray, is_final=False) -> str:
"""
处理单个语音块。
:param speech_chunk: 单个 chunk 的语音数据 (numpy array)。
:param is_final: 是否为最后一个 chunk。
:return: 本次推理新上屏的文本。
"""
if speech_chunk.size == 0:
return ""
res = self.model.generate(
input=speech_chunk,
cache=self.cache,
is_final=is_final,
chunk_size=self.chunk_size,
encoder_chunk_look_back=self.encoder_chunk_look_back,
decoder_chunk_look_back=self.decoder_chunk_look_back,
)
# FunASR 返回一个 list of dicts,我们提取其中的 'text'
return res[0].get('text', '') if res and res[0].get('text') else ""
def transcribe_file(self, wav_file: str):
"""
模式 1: 使用语音文件进行转录。
优化打印逻辑:只打印增量文本。
"""
print(f"--- Starting file transcription: {wav_file} ---")
self.reset_cache()
# 读取语音文件并确保是单声道 16kHz
speech, sr = sf.read(wav_file, dtype='float32')
if sr != self.sample_rate:
raise ValueError(f"File sample rate must be {self.sample_rate}Hz.")
if speech.ndim > 1:
speech = speech.mean(axis=1) # 转单声道
full_text = ""
# 打印一次 ASR 提示,后续只打印文本
print("ASR Output: ", end="", flush=True)
for start in range(0, len(speech), self.chunk_stride_samples):
end = start + self.chunk_stride_samples
speech_chunk = speech[start : end]
is_final = end >= len(speech)
new_text = self.process_chunk(speech_chunk, is_final=is_final)
if new_text:
full_text += new_text
# *** 关键修改:只打印增量文本,并用 end="" 保持在同一行 ***
print(new_text, end="", flush=True)
# 完成后换行
print("\n", end="")
print(f"--- Final Transcription: {full_text} ---")
def transcribe_mic(self):
"""
模式 2: 使用麦克风进行实时转录。
优化打印逻辑:移除重复的 "ASR Output:" 提示。
"""
print("--- Starting real-time microphone transcription (Press Ctrl+C to stop) ---")
self.reset_cache()
full_text = ""
# 计算 sounddevice 的 blocksize (必须是整数)
blocksize_samples = self.chunk_stride_samples
try:
# 打开一个输入流
with sd.InputStream(samplerate=self.sample_rate,
blocksize=blocksize_samples,
channels=1,
dtype='float32') as stream:
print("🔈 Listening...")
# 预先打印一次提示,后续通过 \r 覆盖
print("ASR Output: ", end="", flush=True)
while True:
# 读取一个音频块
audio_chunk, overflowed = stream.read(blocksize_samples)
if overflowed:
print("Audio buffer overflowed!", flush=True)
speech_chunk = audio_chunk[:, 0]
# 实时推理 (is_final=False,除非用户中断)
new_text = self.process_chunk(speech_chunk, is_final=False)
if new_text:
full_text += new_text
print(new_text, end="", flush=True)
except KeyboardInterrupt:
# 用户中断 (Ctrl+C),处理最后一个 chunk 并强制输出
print("\nUser interrupted. Finalizing transcription...")
# 最后一个 chunk 用一个空的 np.array 和 is_final=True 来清空 funasr 内部的缓存
final_text = self.process_chunk(np.array([]).astype(np.float32), is_final=True)
if final_text:
full_text += final_text
print(f"\n--- Final Transcription: {full_text} ---")
except Exception as e:
print(f"\nAn error occurred: {e}")
if __name__ == "__main__":
# 1. 初始化 ASR 实例
# 建议使用 'cpu' 或 'mps' (macOS) / 'cuda' (NVIDIA GPU)
asr_app = RealTimeASR(device="mps")
# --- 模式选择 ---
if len(sys.argv) > 1:
# 模式 A: 文件转录
# 命令行参数数量大于 1,第一个参数即为文件路径
wav_file_path = sys.argv[1]
print(f"检测到参数:'{wav_file_path}'。运行文件转录模式(模式 A)。")
try:
# 假设 RealTimeASR 和 RealTimeVADASR 都有 transcribe_file 方法
asr_app.transcribe_file(wav_file_path)
except FileNotFoundError:
print(f"ERROR: 文件 '{wav_file_path}' 未找到。请提供一个有效的语音文件路径。")
except ValueError as e:
print(f"ERROR: 文件处理错误,请检查采样率是否为 16kHz。详细信息:{e}")
except AttributeError:
print("ERROR: 当前模型实例没有 transcribe_file 方法。请检查类定义。")
else:
# 模式 B: 麦克风实时转录
# 命令行参数数量等于 1 (只有脚本名)
print("未检测到参数。运行麦克风实时转录模式(模式 B)。")
asr_app.transcribe_mic()
chunk_size配置: 遵循您的示例,[0, 10, 5]对应 600ms 的输入块 (10 * 60ms)。sounddevice: 用于跨平台捕获麦克风数据。blocksize设置为 ASR 模型期望的采样点数 (self.chunk_stride_samples),确保每次读取的音频数据量恰好是模型所需的。is_final=True: 在文件模式的循环结束时,以及麦克风模式的用户中断 (Ctrl+C) 处,设置is_final=True来强制 FunASR 模型输出仍在内部缓存中的最后一个词。
Qwen3-Max
import sys
import argparse
import time
import numpy as np
import soundfile as sf
import pyaudio
from funasr import AutoModel
# ==================== 配置 ====================
CHUNK_DURATION_MS = 600 # 每块 600ms(与 Paraformer 的 chunk_size[1]=10 对应)
SAMPLE_RATE = 16000
CHUNK_SIZE_SAMPLES = int(SAMPLE_RATE * CHUNK_DURATION_MS / 1000) # 9600 samples = 600ms
# Paraformer 流式参数
chunk_size = [0, 10, 5] # [0, 10, 5] → 600ms 实时出字,300ms 未来信息
encoder_chunk_look_back = 4
decoder_chunk_look_back = 1
# ==================== 通用流式 ASR 处理器 ====================
class StreamingASR:
def __init__(self, device="mps"):
print("Loading Paraformer streaming ASR model...")
self.model = AutoModel(
model="paraformer-zh-streaming",
device=device,
disable_pbar=True,
)
self.cache = {}
self.full_text = ""
def process_chunk(self, speech_chunk: np.ndarray, is_final: bool = False):
"""处理一个音频块,返回当前增量文本"""
res = self.model.generate(
input=speech_chunk,
cache=self.cache,
is_final=is_final,
chunk_size=chunk_size,
encoder_chunk_look_back=encoder_chunk_look_back,
decoder_chunk_look_back=decoder_chunk_look_back,
)
text = res[0]["text"] if res and "text" in res[0] else ""
if text:
self.full_text += text
print(f"\r{self.full_text}", end="", flush=True)
return text
def reset(self):
self.cache = {}
self.full_text = ""
# ==================== 麦风输入 ====================
def run_mic_stream(asr: StreamingASR):
print("\n🎙️ Starting microphone streaming (press Ctrl+C to stop)...")
p = pyaudio.PyAudio()
stream = p.open(
format=pyaudio.paInt16,
channels=1,
rate=SAMPLE_RATE,
input=True,
frames_per_buffer=CHUNK_SIZE_SAMPLES,
)
try:
while True:
audio_data = stream.read(CHUNK_SIZE_SAMPLES, exception_on_overflow=False)
# 转为 float32 [-1, 1]
audio_np = np.frombuffer(audio_data, dtype=np.int16).astype(np.float32) / 32768.0
asr.process_chunk(audio_np, is_final=False)
except KeyboardInterrupt:
print("\n🛑 Stopping microphone...")
stream.stop_stream()
stream.close()
p.terminate()
# 强制输出剩余内容
asr.process_chunk(np.array([]), is_final=True)
print(f"\n✅ Final transcription:\n{asr.full_text}")
# ==================== 语音文件输入 ====================
def run_file_stream(asr: StreamingASR, wav_file: str):
print(f"\n📂 Processing audio file: {wav_file}")
speech, sr = sf.read(wav_file)
# 转为单声道
if speech.ndim > 1:
speech = speech.mean(axis=1)
# 重采样到 16kHz(简单处理,若采样率不同)
if sr != SAMPLE_RATE:
print(f"⚠️ Resampling from {sr}Hz to {SAMPLE_RATE}Hz (basic linear interpolation)")
duration = len(speech) / sr
new_length = int(duration * SAMPLE_RATE)
speech = np.interp(
np.linspace(0, len(speech), new_length),
np.arange(len(speech)),
speech
)
# 分块处理
for start in range(0, len(speech), CHUNK_SIZE_SAMPLES):
end = start + CHUNK_SIZE_SAMPLES
chunk = speech[start:end]
is_final = end >= len(speech)
asr.process_chunk(chunk, is_final=is_final)
time.sleep(CHUNK_DURATION_MS / 1000) # 模拟实时(可选)
print(f"\n✅ Final transcription:\n{asr.full_text}")
# ==================== 主程序 ====================
def main():
parser = argparse.ArgumentParser(description="实时/文件语音转文字(FunASR + Paraformer 流式)")
parser.add_argument("--file", type=str, help="语音文件路径(如未指定,则使用麦克风)")
parser.add_argument("--device", type=str, default="mps", choices=["cpu", "cuda", "mps"], help="推理设备")
args = parser.parse_args()
asr = StreamingASR(device=args.device)
try:
if args.file:
run_file_stream(asr, args.file)
else:
run_mic_stream(asr)
except Exception as e:
print(f"\n❌ Error: {e}")
sys.exit(1)
if __name__ == "__main__":
main()
混元
import asyncio
import threading
import queue
import time
import os
import numpy as np
import soundfile as sf
import pyaudio
from funasr import AutoModel
import warnings
warnings.filterwarnings('ignore')
class RealTimeTranscriber:
def __init__(self, model_name="paraformer-zh-streaming", device="mps"):
"""
初始化实时语音转录器
Args:
model_name: 模型名称
device: 运行设备 (mps/cpu/cuda)
"""
# 模型配置
self.chunk_size = [0, 10, 5] # 600ms延迟
self.encoder_chunk_look_back = 4
self.decoder_chunk_look_back = 1
# 初始化模型
print(f"正在加载模型 {model_name}...")
self.model = AutoModel(
model=model_name,
device=device,
disable_pbar=True,
disable_update=True
)
# 音频参数
self.sample_rate = 16000
self.chunk_stride = self.chunk_size[1] * 960 # 600ms对应的采样点数
# 状态管理
self.cache = {}
self.is_running = False
self.audio_queue = queue.Queue()
self.result_callback = None
# PyAudio实例
self.pyaudio_instance = None
self.stream = None
def set_result_callback(self, callback):
"""设置结果回调函数"""
self.result_callback = callback
def _audio_callback(self, in_data, frame_count, time_info, status):
"""PyAudio回调函数,用于实时麦克风输入"""
if self.is_running:
audio_data = np.frombuffer(in_data, dtype=np.float32)
self.audio_queue.put(audio_data.copy())
return (in_data, pyaudio.paContinue)
def start_microphone_stream(self):
"""启动麦克风实时流"""
self.pyaudio_instance = pyaudio.PyAudio()
# 查找可用的输入设备
input_device_index = None
for i in range(self.pyaudio_instance.get_device_count()):
info = self.pyaudio_instance.get_device_info_by_index(i)
if info['maxInputChannels'] > 0:
input_device_index = i
print(f"使用音频设备: {info['name']}")
break
self.stream = self.pyaudio_instance.open(
format=pyaudio.paFloat32,
channels=1,
rate=self.sample_rate,
input=True,
input_device_index=input_device_index,
frames_per_buffer=self.chunk_stride,
stream_callback=self._audio_callback
)
self.stream.start_stream()
print("麦克风流已启动")
def stop_microphone_stream(self):
"""停止麦克风实时流"""
self.is_running = False
if self.stream:
self.stream.stop_stream()
self.stream.close()
if self.pyaudio_instance:
self.pyaudio_instance.terminate()
print("麦克风流已停止")
def process_audio_chunk(self, audio_chunk, is_final=False):
"""处理音频块并进行转录"""
try:
res = self.model.generate(
input=audio_chunk,
cache=self.cache,
is_final=is_final,
chunk_size=self.chunk_size,
encoder_chunk_look_back=self.encoder_chunk_look_back,
decoder_chunk_look_back=self.decoder_chunk_look_back,
)
# 提取文本结果
if res and len(res) > 0 and 'text' in res[0]:
text = res[0]['text'].strip()
if text: # 只有非空文本才返回
return text
return None
except Exception as e:
print(f"转录错误: {e}")
return None
def transcribe_file(self, file_path, display_intermediate=True):
"""转录音频文件"""
print(f"开始转录文件: {file_path}")
try:
# 读取音频文件
speech, sample_rate = sf.read(file_path)
# 重采样到16kHz(如果需要)
if sample_rate != self.sample_rate:
# 这里可以添加重采样逻辑
print(f"警告: 音频采样率为{sample_rate}Hz,建议使用{self.sample_rate}Hz")
# 如果是多通道,转换为单通道
if speech.ndim > 1:
speech = speech.mean(axis=1)
# 重置缓存
self.cache = {}
all_text = []
start_time = time.time()
# 分块处理
for start in range(0, len(speech), self.chunk_stride):
end = start + self.chunk_stride
speech_chunk = speech[start:end]
is_final = end >= len(speech)
text = self.process_audio_chunk(speech_chunk, is_final)
if text:
if display_intermediate or is_final:
print(f"{text}", end='', flush=True)
all_text.append(text)
# 模拟实时延迟
if not is_final:
time.sleep(0.01)
total_time = time.time() - start_time
full_text = ''.join(all_text)
print(f"\n\n转录完成! 总时长: {total_time:.2f}s")
print(f"最终结果: {full_text}")
return full_text
except Exception as e:
print(f"文件转录错误: {e}")
return ""
def microphone_transcription_loop(self):
"""麦克风转录主循环"""
buffer = np.array([], dtype=np.float32)
last_result_time = time.time()
while self.is_running:
try:
# 从队列获取音频数据(非阻塞)
try:
chunk = self.audio_queue.get_nowait()
buffer = np.concatenate([buffer, chunk])
except queue.Empty:
time.sleep(0.001)
continue
# 当缓冲区有足够数据时进行处理
while len(buffer) >= self.chunk_stride:
# 提取一个chunk进行处理
speech_chunk = buffer[:self.chunk_stride]
buffer = buffer[self.chunk_stride:]
# 检查是否静音(可选优化)
if self._is_silent(speech_chunk):
continue
text = self.process_audio_chunk(speech_chunk)
if text:
current_time = time.time()
# 避免过于频繁的更新
if current_time - last_result_time > 0.1 or len(text) > 1:
result = {
'type': 'realtime',
'text': text,
'timestamp': current_time
}
if self.result_callback:
self.result_callback(result)
else:
print(f"\r实时转录: {text}", end='', flush=True)
last_result_time = current_time
except Exception as e:
print(f"麦克风处理错误: {e}")
continue
def _is_silent(self, audio_chunk, threshold=0.01):
"""简单的静音检测"""
return np.max(np.abs(audio_chunk)) < threshold
def start_realtime_transcription(self):
"""开始实时转录"""
if self.is_running:
print("转录已在运行中")
return
self.is_running = True
self.cache = {} # 重置缓存
# 启动麦克风流
self.start_microphone_stream()
# 启动处理线程
self.process_thread = threading.Thread(target=self.microphone_transcription_loop)
self.process_thread.daemon = True
self.process_thread.start()
print("实时转录已开始,按 Ctrl+C 停止...")
def stop_realtime_transcription(self):
"""停止实时转录"""
self.is_running = False
self.stop_microphone_stream()
if hasattr(self, 'process_thread'):
self.process_thread.join(timeout=2)
print("\n实时转录已停止")
def main():
"""主函数 - 演示用法"""
# 创建转录器实例
transcriber = RealTimeTranscriber()
def result_handler(result):
"""处理结果回调"""
print(f"{result['text']}", end='', flush=True)
transcriber.set_result_callback(result_handler)
try:
while True:
print("\n=== 实时语音转录系统 ===")
print("1. 麦克风实时转录")
print("2. 音频文件转录")
print("3. 退出")
choice = input("请选择模式 (1-3): ").strip()
if choice == '1':
print("开始麦克风实时转录...")
print("说话吧!按 Ctrl+C 停止")
transcriber.start_realtime_transcription()
try:
# 保持运行直到用户中断
while True:
time.sleep(1)
except KeyboardInterrupt:
transcriber.stop_realtime_transcription()
elif choice == '2':
file_path = input("请输入音频文件路径: ").strip().strip('"')
if os.path.exists(file_path):
transcriber.transcribe_file(file_path)
else:
print("文件不存在!")
elif choice == '3':
print("再见!")
break
else:
print("无效选择!")
except KeyboardInterrupt:
print("\n程序被用户中断")
finally:
# 确保资源被正确释放
if transcriber.is_running:
transcriber.stop_realtime_transcription()
if __name__ == "__main__":
# 检查依赖
try:
import pyaudio
except ImportError:
print("请安装 PyAudio: pip install pyaudio")
exit(1)
main()
实时语音识别(VAD)
Gemini3-Flash
import numpy as np
import sounddevice as sd
from funasr import AutoModel
import soundfile as sf
import time
class RealTimeVADASR:
"""
FunASR 实时 VAD + ASR 联合流式推理类。
VAD 控制 ASR 模型的输入,实现更智能的实时转录。
"""
def __init__(self, device="cpu"):
self.sample_rate = 16000
self.device = device
# --- VAD 配置 ---
self.vad_model = "fsmn-vad"
self.vad_chunk_size_ms = 200 # VAD 每次处理 200ms
self.vad_stride_samples = int(self.vad_chunk_size_ms * self.sample_rate / 1000)
self.vad_cache = {}
print(f"Loading VAD model: {self.vad_model} on {self.device}...")
self.vad_model = AutoModel(
model=self.vad_model,
device=self.device,
disable_pbar=True,
disable_update=True
)
# --- ASR 配置 ---
self.asr_model = "paraformer-zh-streaming"
# ASR chunk_size=[0, 10, 5] -> 600ms
self.asr_chunk_size = [0, 10, 5]
self.asr_stride_samples = int(self.asr_chunk_size[1] * self.sample_rate * 0.06) # 10 * 960 = 9600 samples = 600ms
self.asr_cache = {}
print(f"Loading ASR model: {self.asr_model} on {self.device}...")
self.asr_model = AutoModel(
model=self.asr_model,
device=self.device,
disable_pbar=True,
disable_update=True
)
# VAD 状态管理
self.speech_start_time = 0
self.speech_end_time = 0
self.is_speech_start = False
self.speech_buffer = np.array([]).astype(np.float32)
def _reset_asr_cache(self):
"""重置 ASR 流式缓存。"""
self.asr_cache = {}
def _process_asr_chunk(self, speech_chunk: np.ndarray, is_final=False) -> str:
"""
处理单个语音块并进行 ASR 推理。
"""
if speech_chunk.size == 0 and not is_final:
return ""
res = self.asr_model.generate(
input=speech_chunk,
cache=self.asr_cache,
is_final=is_final,
chunk_size=self.asr_chunk_size,
encoder_chunk_look_back=4,
decoder_chunk_look_back=1,
)
return res[0].get('text', '') if res and res[0].get('text') else ""
def _run_vad_asr(self, speech_chunk: np.ndarray, current_time_ms: int):
"""
核心联合推理逻辑:VAD 决定何时将数据送给 ASR。
:param speech_chunk: 当前的语音块。
:param current_time_ms: 当前语音块在流中的时间戳(ms)。
"""
new_text = ""
# 1. VAD 推理
vad_res = self.vad_model.generate(
input=speech_chunk,
cache=self.vad_cache,
is_final=False,
chunk_size=self.vad_chunk_size_ms,
)
vad_value = vad_res[0].get('value', [])
# 2. VAD 状态解析
if vad_value:
for start_ms, end_ms in vad_value:
# 语音起始事件 (start_ms > 0)
if start_ms >= 0 and not self.is_speech_start:
self.is_speech_start = True
self.speech_start_time = current_time_ms + start_ms
print(f"\n[VAD] Speech Start at {self.speech_start_time}ms", flush=True)
# 语音结束事件 (end_ms > 0)
if end_ms >= 0 and self.is_speech_start:
self.is_speech_start = False
self.speech_end_time = current_time_ms + end_ms
print(f"\n[VAD] Speech End at {self.speech_end_time}ms. Finalizing ASR...", flush=True)
# 3. 语音结束,清空 ASR 缓存
# ASR 强制输出最后一个字
new_text = self._process_asr_chunk(np.array([]).astype(np.float32), is_final=True)
self._reset_asr_cache()
# 清空缓冲区
self.speech_buffer = np.array([]).astype(np.float32)
# 3. ASR 缓冲和流式推理
if self.is_speech_start:
# 只有在检测到语音活动时,才将数据添加到缓冲区
self.speech_buffer = np.append(self.speech_buffer, speech_chunk)
# 如果缓冲区数据量达到 ASR 模型的 chunk 大小,则进行 ASR 推理
if len(self.speech_buffer) >= self.asr_stride_samples:
# 取出 ASR chunk
asr_chunk = self.speech_buffer[:self.asr_stride_samples]
# 更新缓冲区
self.speech_buffer = self.speech_buffer[self.asr_stride_samples:]
# ASR 实时推理
new_asr_text = self._process_asr_chunk(asr_chunk, is_final=False)
if new_asr_text:
new_text += new_asr_text
return new_text
def transcribe_mic(self):
"""
使用麦克风进行 VAD + ASR 实时转录。
"""
print("--- Starting real-time VAD+ASR (Press Ctrl+C to stop) ---")
self._reset_asr_cache()
self.vad_cache = {}
self.speech_buffer = np.array([]).astype(np.float32)
full_text = ""
current_time_ms = 0
# VAD 模型的 chunk size 决定了 sounddevice 的 blocksize
blocksize_samples = self.vad_stride_samples
try:
with sd.InputStream(samplerate=self.sample_rate,
blocksize=blocksize_samples,
channels=1,
dtype='float32') as stream:
print(f"Listening... (VAD chunk: {self.vad_chunk_size_ms}ms)")
while True:
audio_chunk, overflowed = stream.read(blocksize_samples)
if overflowed:
print("Audio buffer overflowed!", flush=True)
speech_chunk = audio_chunk[:, 0]
# 运行 VAD + ASR 联合推理
new_text = self._run_vad_asr(speech_chunk, current_time_ms)
if new_text:
full_text += new_text
# 实时打印转录结果
print(f"ASR Output: {full_text}\r", end="", flush=True)
current_time_ms += self.vad_chunk_size_ms
except KeyboardInterrupt:
# 用户中断 (Ctrl+C)
print("\nUser interrupted. Finalizing ASR...")
# 清理 ASR 缓冲区中的剩余数据
if len(self.speech_buffer) > 0:
final_text = self._process_asr_chunk(self.speech_buffer, is_final=False)
if final_text:
full_text += final_text
# 强制 ASR 输出最后一个字
final_text = self._process_asr_chunk(np.array([]).astype(np.float32), is_final=True)
if final_text:
full_text += final_text
print(f"\n--- Final Transcription: {full_text} ---")
except Exception as e:
print(f"\nAn error occurred: {e}")
if __name__ == "__main__":
# 1. 初始化 ASR 实例
# 建议使用 'cpu' 或 'mps' (macOS) / 'cuda' (NVIDIA GPU)
asr_app = RealTimeVADASR(device="mps")
# 开始麦克风 VAD + ASR 联合转录
asr_app.transcribe_mic()
Qwen3-Max
import sys
import argparse
import time
import numpy as np
import soundfile as sf
import pyaudio
from funasr import AutoModel
# ==================== 配置 ====================
SAMPLE_RATE = 16000
# VAD 配置(小块,低延迟)
VAD_CHUNK_MS = 200
VAD_CHUNK_SAMPLES = int(SAMPLE_RATE * VAD_CHUNK_MS / 1000) # 3200 samples
# ASR 配置(600ms/块)
ASR_CHUNK_MS = 600
ASR_CHUNK_SAMPLES = int(SAMPLE_RATE * ASR_CHUNK_MS / 1000) # 9600 samples
# Paraformer 流式参数
ASR_CHUNK_SIZE = [0, 10, 5] # 600ms 实时出字
ENC_LOOK_BACK = 4
DEC_LOOK_BACK = 1
# ==================== VAD + ASR 联合处理器 ====================
class VADASRPipeline:
def __init__(self, device="mps"):
print("Loading FSMN-VAD model...")
self.vad_model = AutoModel(
model="fsmn-vad",
device=device,
disable_pbar=True,
disable_update=True
)
self.vad_cache = {}
print("Loading Paraformer streaming ASR model...")
self.asr_model = AutoModel(
model="paraformer-zh-streaming",
device=device,
disable_pbar=True,
disable_update=True
)
# 状态变量
self.speech_buffer = [] # 缓存当前语音段的音频
self.in_speech = False # 是否处于语音中
self.asr_cache = {}
self.full_transcript = ""
def _run_asr_on_segment(self, speech_segment: np.ndarray):
"""对一个完整语音段运行流式 ASR"""
if len(speech_segment) == 0:
return
print("\n🎙️ Detected speech segment, transcribing...")
self.asr_cache = {} # 每段语音重置 ASR 缓存
segment_text = ""
# 分块送入 ASR(600ms/块)
for start in range(0, len(speech_segment), ASR_CHUNK_SAMPLES):
end = start + ASR_CHUNK_SAMPLES
chunk = speech_segment[start:end]
is_final = end >= len(speech_segment)
res = self.asr_model.generate(
input=chunk,
cache=self.asr_cache,
is_final=is_final,
chunk_size=ASR_CHUNK_SIZE,
encoder_chunk_look_back=ENC_LOOK_BACK,
decoder_chunk_look_back=DEC_LOOK_BACK,
)
text = res[0].get("text", "")
if text:
segment_text += text
print(f"\r[ASR] {segment_text}", end="", flush=True)
if segment_text:
self.full_transcript += segment_text + " "
print(f"\n✅ Segment done: \"{segment_text}\"")
else:
print("\n🔇 (No text recognized)")
def process_audio_chunk(self, audio_chunk: np.ndarray, is_final: bool = False):
"""主入口:处理一个 VAD chunk(200ms)"""
# VAD 推理
vad_res = self.vad_model.generate(
input=audio_chunk,
cache=self.vad_cache,
is_final=is_final,
chunk_size=VAD_CHUNK_MS, # 单位 ms
)
# 解析 VAD 结果:[ [start_ms, end_ms], ... ]
segments = vad_res[0]["value"]
speech_in_chunk = False
if segments:
for seg in segments:
start_ms, end_ms = seg
if start_ms >= 0 and end_ms == -1:
# 语音开始
self.in_speech = True
self.speech_buffer = []
# 如果 start_ms > 0,说明 chunk 前半段是静音,但我们已按 200ms 切分,通常 start_ms=0
elif start_ms == -1 and end_ms >= 0:
# 语音结束
self.in_speech = False
speech_in_chunk = True
elif start_ms >= 0 and end_ms >= 0:
# 完整语音段(短语音)
self.in_speech = False
speech_in_chunk = True
# 缓存音频
if self.in_speech or speech_in_chunk:
self.speech_buffer.append(audio_chunk)
# 如果语音结束,送入 ASR
if not self.in_speech and speech_in_chunk and len(self.speech_buffer) > 0:
full_speech = np.concatenate(self.speech_buffer)
self._run_asr_on_segment(full_speech)
self.speech_buffer = []
# 最终块:强制结束
if is_final and self.in_speech and len(self.speech_buffer) > 0:
full_speech = np.concatenate(self.speech_buffer)
self._run_asr_on_segment(full_speech)
self.speech_buffer = []
self.in_speech = False
def get_final_transcript(self):
return self.full_transcript.strip()
def reset(self):
self.speech_buffer = []
self.in_speech = False
self.vad_cache = {}
self.asr_cache = {}
self.full_transcript = ""
# ==================== 麦克风模式 ====================
def run_mic_mode(pipeline: VADASRPipeline):
print("\n🎤 Starting microphone with VAD+ASR (Ctrl+C to stop)...")
p = pyaudio.PyAudio()
stream = p.open(
format=pyaudio.paInt16,
channels=1,
rate=SAMPLE_RATE,
input=True,
frames_per_buffer=VAD_CHUNK_SAMPLES,
)
try:
while True:
data = stream.read(VAD_CHUNK_SAMPLES, exception_on_overflow=False)
audio_np = np.frombuffer(data, dtype=np.int16).astype(np.float32) / 32768.0
pipeline.process_audio_chunk(audio_np, is_final=False)
except KeyboardInterrupt:
print("\n🛑 Stopping...")
stream.stop_stream()
stream.close()
p.terminate()
pipeline.process_audio_chunk(np.array([]), is_final=True)
print(f"\n📜 Final Transcript:\n{pipeline.get_final_transcript()}")
# ==================== 文件模式 ====================
def run_file_mode(pipeline: VADASRPipeline, wav_file: str):
print(f"\n📂 Processing file: {wav_file} with VAD+ASR")
speech, sr = sf.read(wav_file)
if speech.ndim > 1:
speech = speech.mean(axis=1)
if sr != SAMPLE_RATE:
print(f"⚠️ Resampling from {sr}Hz to {SAMPLE_RATE}Hz")
duration = len(speech) / sr
new_len = int(duration * SAMPLE_RATE)
speech = np.interp(np.linspace(0, len(speech), new_len), np.arange(len(speech)), speech)
# 按 VAD chunk 分割
for start in range(0, len(speech), VAD_CHUNK_SAMPLES):
end = start + VAD_CHUNK_SAMPLES
chunk = speech[start:end]
is_final = end >= len(speech)
pipeline.process_audio_chunk(chunk, is_final=is_final)
# 可选:模拟实时
# time.sleep(VAD_CHUNK_MS / 1000)
print(f"\n📜 Final Transcript:\n{pipeline.get_final_transcript()}")
# ==================== 主程序 ====================
def main():
parser = argparse.ArgumentParser(description="VAD + 流式 ASR 联合系统")
parser.add_argument("--file", type=str, help="输入语音文件(WAV)")
parser.add_argument("--device", type=str, default="mps", choices=["cpu", "cuda", "mps"])
args = parser.parse_args()
pipeline = VADASRPipeline(device=args.device)
try:
if args.file:
run_file_mode(pipeline, args.file)
else:
run_mic_mode(pipeline)
except Exception as e:
print(f"\n❌ Error: {e}")
import traceback
traceback.print_exc()
sys.exit(1)
if __name__ == "__main__":
main()
实时语音唤醒(VAD)
import pyaudio
import numpy as np
from funasr import AutoModel
import soundfile as sf
# 配置 FunASR 模型
model = AutoModel(
model="iic/speech_charctc_kws_phone-xiaoyun",
keywords="小云小云",
output_dir="./outputs/debug",
device='cpu',
disable_update=True
)
# 配置音频参数
RATE = 16000 # 采样率
CHUNK = 1024 # 缓冲区大小,减小为1024,避免溢出
FORMAT = pyaudio.paInt16 # 音频格式
CHANNELS = 1 # 单声道
# 初始化 pyaudio
p = pyaudio.PyAudio()
# 打开麦克风流
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK,
stream_callback=None)
print("开始录音... 请说出关键词(例如:'小云')")
# 加载 VAD 模型
vad_model = AutoModel(
model="fsmn-vad",
device="cpu",
disable_pbar=True,
disable_update=True
)
# 初始化缓存
cache = {}
# 音频流处理函数
def process_audio_stream():
try:
print("正在监听麦克风...")
buffer = np.zeros(0) # 缓存音频数据
while True:
# 读取一段音频数据
data = stream.read(CHUNK, exception_on_overflow=False) # 设置exception_on_overflow=False
np_data = np.frombuffer(data, dtype=np.int16) # 转换为numpy数组
# 转换为float32 类型以适配 torchaudio
np_data = np_data.astype(np.float32) / 32768.0 # 将数据标准化到 -1 到 1 之间
# 将当前音频数据加入缓存
buffer = np.concatenate((buffer, np_data))
# 如果缓存超过 2 秒音频,开始处理(防止缓存过大)
if len(buffer) >= 2 * RATE: # 2秒数据
print(f"处理了一段音频,长度: {len(buffer)}")
# 使用 VAD 检测当前缓存是否包含语音
vad_res = vad_model.generate(input=buffer, cache=cache, is_final=True, chunk_size=200)
if len(vad_res[0]["value"]) > 0: # 如果检测到语音活动
print("检测到语音活动,开始进行关键词检测")
# 将音频数据传给关键词识别模型
try:
res = model.generate(input=buffer, cache=cache)
print(f"模型输出: {res}") # 打印模型返回的结果
if 'kws' in res:
if res['kws'] == "小云小云":
print("检测到关键词:小云")
break
except Exception as e:
print(f"模型推理过程中发生错误: {e}")
else:
print("没有检测到语音活动,跳过当前音频块")
# 处理完数据后清空缓存
buffer = np.zeros(0)
except KeyboardInterrupt:
print("停止录音.")
stream.stop_stream()
stream.close()
p.terminate()
if __name__ == "__main__":
process_audio_stream()
説活人嵌入向量提取服务
import numpy as np
import torch
import torch.nn.functional as F
from funasr import AutoModel
from fastapi import FastAPI, HTTPException
from pydantic import BaseModel
import traceback # 导入堆栈追踪库
import warnings
# 忽略funasr内部的一些警告
warnings.filterwarnings('ignore')
# --- 模型初始化(全局一次) ---
# 初始化模型
try:
print("正在初始化 FunASR AutoModel (speech_campplus_sv_zh-cn_16k-common)...")
model = AutoModel(
model="iic/speech_campplus_sv_zh-cn_16k-common",
device="cpu",
# 禁用进度条和更新检查,加快初始化速度
disable_pbar=True,
disable_update=True,
)
print("模型初始化成功。")
except Exception as e:
# 打印错误信息并让程序退出,因为没有模型服务无法运行
print(f"模型初始化失败: {e}")
# 在实际部署中,可能需要更优雅的错误处理,但这里我们直接退出或抛出异常
raise RuntimeError("无法加载模型,请检查配置和依赖。")
# --- FastAPI 应用和 Pydantic 模型 ---
app = FastAPI(
title="FunASR 说话人嵌入向量提取服务",
description="基于 FunASR/CampPlus 的中文说话人验证/识别嵌入向量提取 API。",
version="1.0.0"
)
class AudioPath(BaseModel):
"""请求体模型:包含音频路径或URL"""
audio_path: str
class EmbeddingResponse(BaseModel):
"""响应体模型:包含嵌入向量和维度信息"""
audio_path: str
embedding: list[float]
dimension: int
norm: float
# --- 核心逻辑函数 ---
def extract_speaker_embedding(audio_path):
"""
提取音频的说话人嵌入向量。
:param audio_path: 音频文件的本地路径或 URL。
:return: 归一化后的说话人嵌入向量 (numpy.ndarray)。
"""
# 这里的 generate 能够处理本地路径或网络 URL (如您示例中的阿里云OSS链接)
res = model.generate(input=audio_path)
# 检查结果是否包含嵌入向量
if not res or 'spk_embedding' not in res[0]:
raise ValueError("模型未能提取出说话人嵌入向量,请检查音频文件。")
embedding = res[0]['spk_embedding']
# 归一化处理(L2范数归一化,与您的原代码保持一致)
# F.normalize 确保向量的 L2 范数(长度)为 1
embedding = F.normalize(embedding, p=2, dim=1)
# 转换为numpy数组并移除维度为1的轴 (e.g., [1, 512] -> [512])
return embedding.squeeze().numpy()
# --- API 路由定义 ---
@app.post(
"/extract_embedding",
response_model=EmbeddingResponse,
summary="提取说话人嵌入向量",
description="输入音频文件路径或URL,返回L2归一化后的说话人嵌入向量。"
)
async def get_speaker_embedding(item: AudioPath):
"""
接受一个音频路径,调用模型提取说话人嵌入向量,并返回结果。
"""
try:
# 调用核心提取函数
embedding_np = extract_speaker_embedding(item.audio_path)
# 将 numpy 数组转换为 list 以便 JSON 序列化
embedding_list = embedding_np.tolist()
dimension = embedding_np.shape[0]
# 计算 L2 范数(对于归一化后的向量,应该接近 1.0)
vector_norm = np.linalg.norm(embedding_np)
return EmbeddingResponse(
audio_path=item.audio_path,
embedding=embedding_list,
dimension=dimension,
norm=float(vector_norm) # 确保是标准浮点数
)
except ValueError as e:
# 如果模型提取失败 (如音频文件损坏或路径错误)
raise HTTPException(
status_code=400,
detail=f"音频处理错误: {e}"
)
except Exception as e:
# 关键:打印出具体错误到终端
print("发生错误!具体堆栈如下:")
traceback.print_exc()
# 捕捉其他可能的运行时错误 (如网络问题、模型执行错误)
raise HTTPException(
status_code=500,
detail=f"服务器内部错误: {e}"
)
if __name__ == "__main__":
# 1. 模拟一个请求对象
test_item = AudioPath(
audio_path="https://isv-data.oss-cn-hangzhou.aliyuncs.com/ics/MaaS/ASR/test_audio/sv_example_enroll.wav"
)
# 2. 定义一个运行测试的异步函数
async def run_test():
print(f"\n--- 开始本地测试调用 ---")
try:
# 直接调用异步函数
result = await get_speaker_embedding(test_item)
print("测试成功!")
print(f"音频路径: {result.audio_path}")
print(f"向量维度: {result.dimension}")
print(f"向量模长: {result.norm:.4f}")
print(f"向量前5位: {result.embedding[:5]}...")
except Exception as e:
print(f"测试失败: {e}")
# 3. 执行测试
import asyncio
asyncio.run(run_test())
安装依赖
pip install funasr torch fastapi uvicorn[standard] numpy
运行服务
在终端中运行以下命令启动 FastAPI 应用:
uvicorn speaker_api:app --host 0.0.0.0 --port 8000
测试 API
服务启动后,您可以通过访问 http://127.0.0.1:8000/docs 来使用 Swagger UI 进行测试。