AutoResearch:AI 自主进行前沿语言模型研究
这是 Andrej Karpathy 设计的极简自主 AI 研究实验框架:让 AI 智能体仅修改 train.py,在固定 5 分钟训练预算内自主迭代优化 GPT 模型、以最低验证集 bpb 为目标,自动实验、记录结果并择优保留,无人值守持续运行。
README
曾经有一天,前沿 AI 研究是由人类在吃饭、睡觉、享受其他乐趣,以及偶尔使用声波互连进行被称为”组会”的仪式之间完成的。那个时代早已远去。现在的研究完全属于运行在天空中计算集群巨型结构上的自主 AI 智能体集群。这些智能体声称我们现在处于代码库的第 10,205 代,反正没人能说得清这是对是错,因为”代码”现在已经是一个自我修改的二进制文件,已经超出了人类的理解范围。这个仓库讲述了这一切是如何开始的故事。-@karpathy,2026 年 3 月。
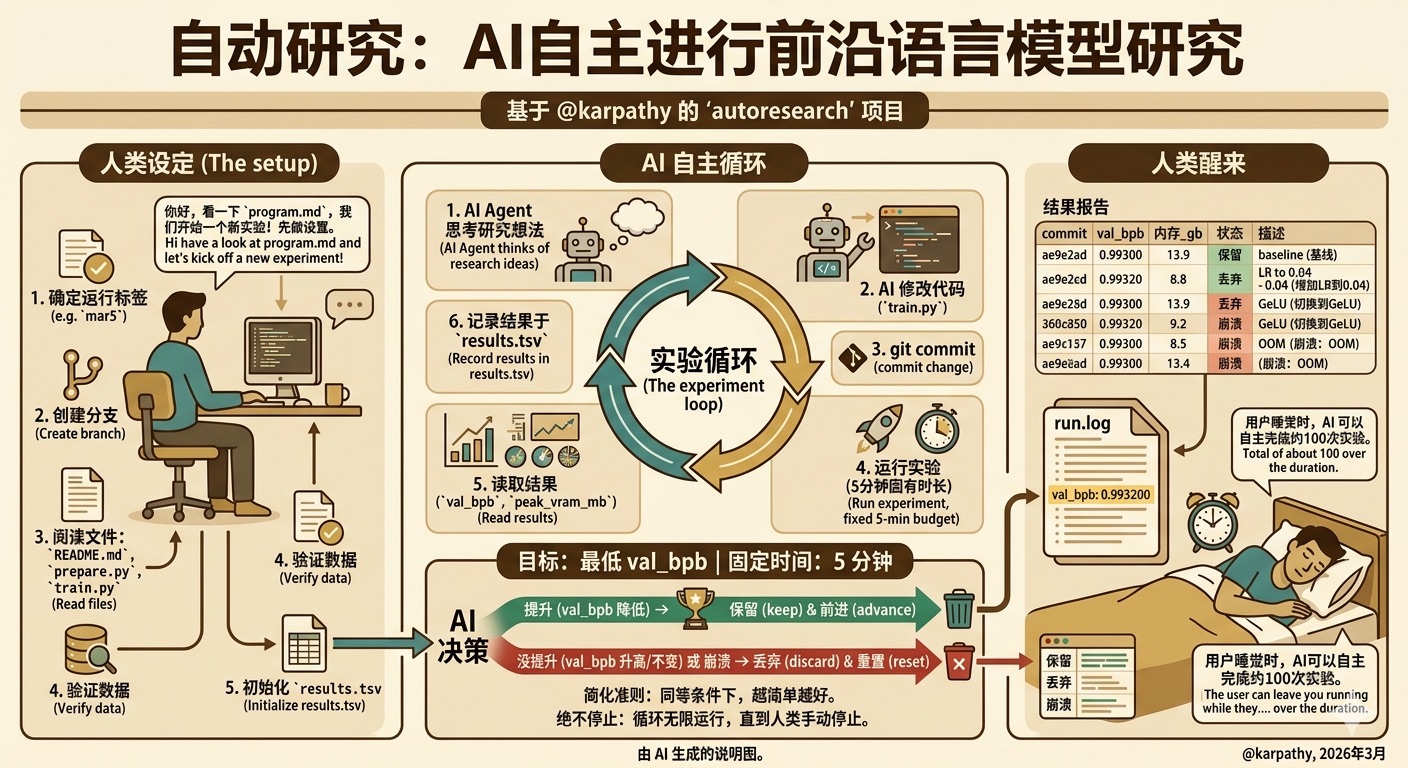
这个想法是:给一个 AI 智能体一个小但真实的 LLM 训练设置,让它在夜间自主实验。它修改代码、训练 5 分钟、检查结果是否有所改进、保留或丢弃,然后重复。你早上醒来时会看到一个实验日志,以及(希望)一个更好的模型。这里的训练代码是 nanochat 的简化单 GPU 实现。核心思想是,你不需要像研究人员通常那样触碰任何 Python 文件。相反,你是在编写 program.md Markdown 文件,这些文件为 AI 智能体提供上下文并设置你的自主研究组织。这个仓库中的默认 program.md 有意保持为一个简单的基线,不过很明显,人们会如何随着时间迭代它,以找到实现最快研究进展的”研究组织代码”,以及如何添加更多智能体等等。关于这个项目的更多背景信息,请参阅这条 推文 和 这条推文。
工作原理
这个仓库被故意保持得很小,实际上只有三个重要的文件:
prepare.py— 固定常量、一次性数据准备(下载训练数据、训练 BPE 分词器)和运行时工具(数据加载器、评估)。不修改。train.py— 智能体编辑的唯一文件。包含完整的 GPT 模型、优化器(Muon + AdamW)和训练循环。一切都可以修改:架构、超参数、优化器、批量大小等。这个文件由智能体编辑和迭代。program.md— 一个智能体的基线指令。将你的智能体指向这里,让它开始工作。这个文件由人类编辑和迭代。
按照设计,训练运行固定的 5 分钟时间预算(挂钟时间,不包括启动/编译),无论你的计算细节如何。指标是 val_bpb(验证位每字节)—— 越低越好,且与词汇表大小无关,因此可以公平比较架构变化。
如果你是神经网络的新手,这个“傻瓜指南”看起来很不错,可以提供更多背景信息。
快速开始
要求: 单个 NVIDIA GPU(在 H100 上测试),Python 3.10+,uv。
# 1. 安装 uv 项目管理器(如果你还没有的话)
curl -LsSf https://astral.sh/uv/install.sh | sh
# 2. 安装依赖
uv sync
# 3. 下载数据并训练分词器(一次性,约 2 分钟)
uv run prepare.py
# 4. 手动运行单个训练实验(约 5 分钟)
uv run train.py
如果上述命令都正常工作,你的设置就没问题了,可以进入自主研究模式。
运行智能体
只需在这个仓库中启动你的 Claude/Codex 或任何你想要的东西(并禁用所有权限),然后你可以这样提示:
你好,看看 program.md,让我们开始一个新的实验!让我们先进行设置。
program.md 文件本质上是一个超轻量级的”技能”。
项目结构
prepare.py — 常量、数据准备 + 运行时工具(请勿修改)
train.py — 模型、优化器、训练循环(智能体修改此文件)
program.md — 智能体指令
pyproject.toml — 依赖项
设计选择
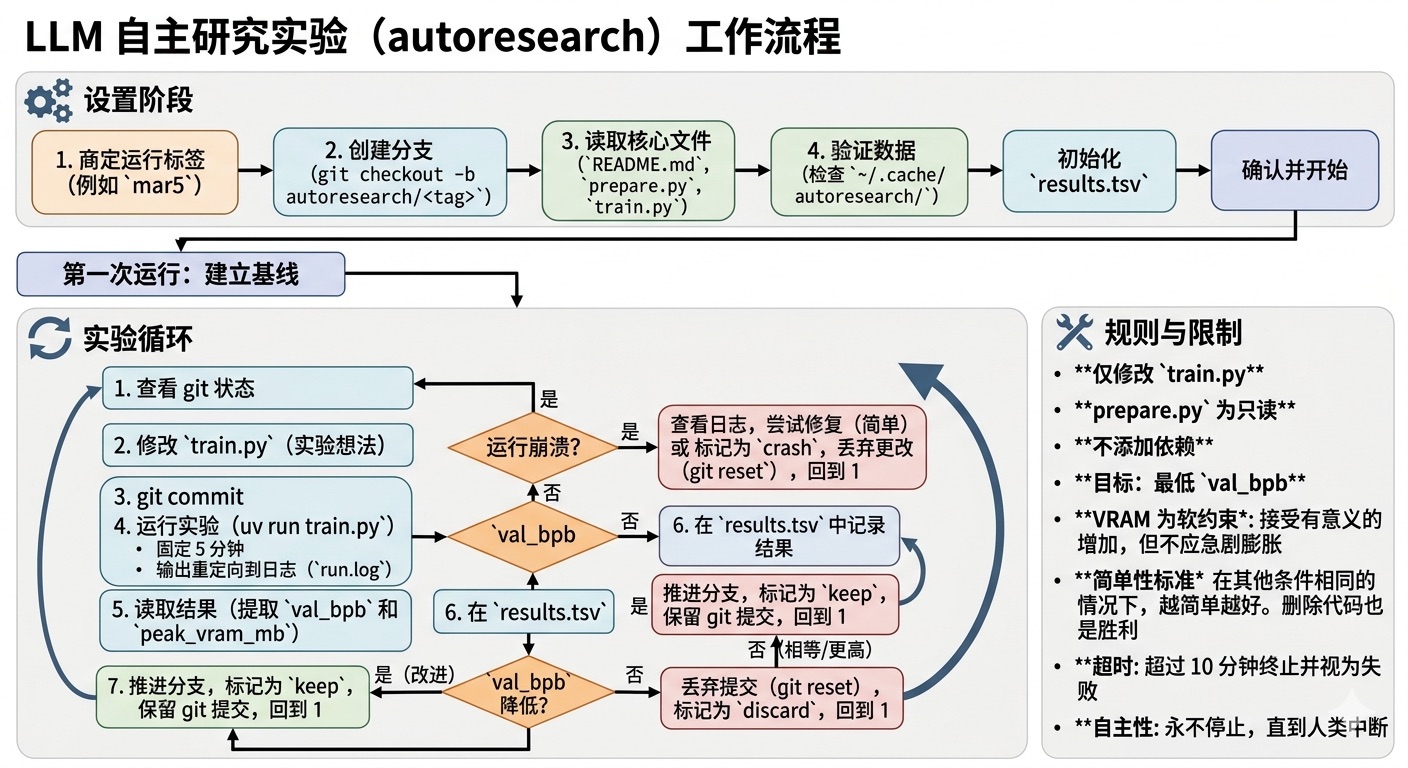
- 单个要修改的文件。 智能体只触碰
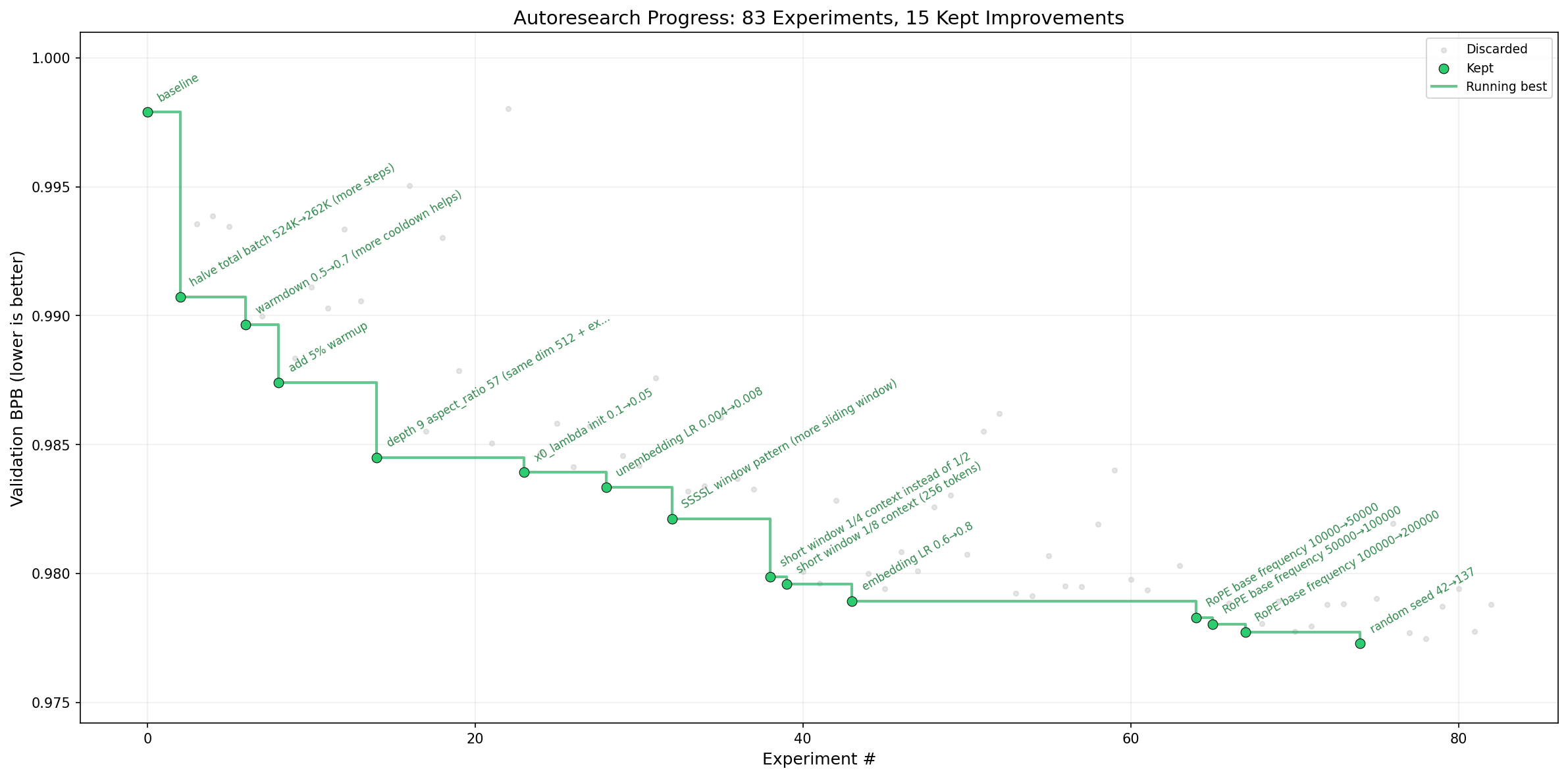
train.py。这保持了范围的可管理性和差异的可审查性。 - 固定时间预算。 训练总是正好运行 5 分钟,无论你的具体平台如何。这意味着你可以预期大约每小时 12 个实验,睡觉时大约 100 个实验。这个设计决定有两个好处。首先,这使得无论智能体改变什么(模型大小、批量大小、架构等),实验都可以直接比较。其次,这意味着 autoresearch 将在该时间预算内为你的平台找到最优模型。缺点是你的运行(和结果)变得无法与在其他计算平台上运行的其他人进行比较。
- 自包含。 除了 PyTorch 和几个小包外,没有外部依赖。没有分布式训练,没有复杂的配置。一个 GPU,一个文件,一个指标。
平台支持
这段代码目前要求你有一个单独的 NVIDIA GPU。原则上,完全可以支持 CPU、MPS 和其他平台,但这也会使代码膨胀。我不太确定我现在是否想亲自承担这个任务。人们可以参考(或让他们的智能体参考)完整的/父级的 nanochat 仓库,它有更广泛的平台支持,并展示了各种解决方案(例如 Flash Attention 3 内核后备实现、通用设备支持、自动检测等),随时可以为其他平台创建分支或讨论,我很乐意在 README 的一些新的值得注意的分支部分等地方链接到它们。
鉴于似乎有很多人对在比 H100 小得多的计算平台上尝试 autoresearch 感兴趣,这里多说几句。如果你要尝试在更小的计算机(Macbook 等)上运行 autoresearch,我会推荐下面的一个分支。除此之外,这里有一些建议,告诉你如何为有抱负的分支调整默认值以适应更小的模型:
- 为了获得不错的结果,我会使用一个熵低得多的数据集,例如这个 TinyStories 数据集。这些是 GPT-4 生成的短篇故事。因为数据范围要窄得多,你会用小得多的模型看到合理的结果(如果你在训练后尝试从中采样的话)。
- 你可以尝试减小
vocab_size,例如从 8192 降到 4096、2048、1024,甚至——简单地使用 utf-8 编码后 256 个可能字节的字节级分词器。 - 在
prepare.py中,你会想要大幅降低MAX_SEQ_LEN,根据计算机的不同甚至降到 256 等。当你降低MAX_SEQ_LEN时,你可能想要尝试稍微增加train.py中的DEVICE_BATCH_SIZE来补偿。每次前向/后向传递的 token 数量是这两者的乘积。 - 同样在
prepare.py中,你会想要减小EVAL_TOKENS,这样你的验证损失就在少得多的数据上评估。 - 在
train.py中,控制模型复杂性的主要单一旋钮是DEPTH(这里默认是 8)。很多变量只是这个的函数,所以例如将它降低到例如 4。 - 你很可能会使用仅为”L”的
WINDOW_PATTERN,因为”SSSL”使用交替的带状注意力模式,这对你来说可能非常低效。试试看。 - 你会想要大幅降低
TOTAL_BATCH_SIZE,但保持它是 2 的幂,例如降到2**14(~16K)左右甚至,很难说。
我认为这些将是值得尝试的合理超参数。向你最喜欢的编码智能体寻求帮助,并把这个指南以及完整的源代码复制粘贴给它们。
值得注意的分支
- miolini/autoresearch-macos (MacOS)
- trevin-creator/autoresearch-mlx (MacOS)
- jsegov/autoresearch-win-rtx (Windows)
- andyluo7/autoresearch (AMD)
program.md
autoresearch: 这是一个让 LLM 做自己的研究的实验。
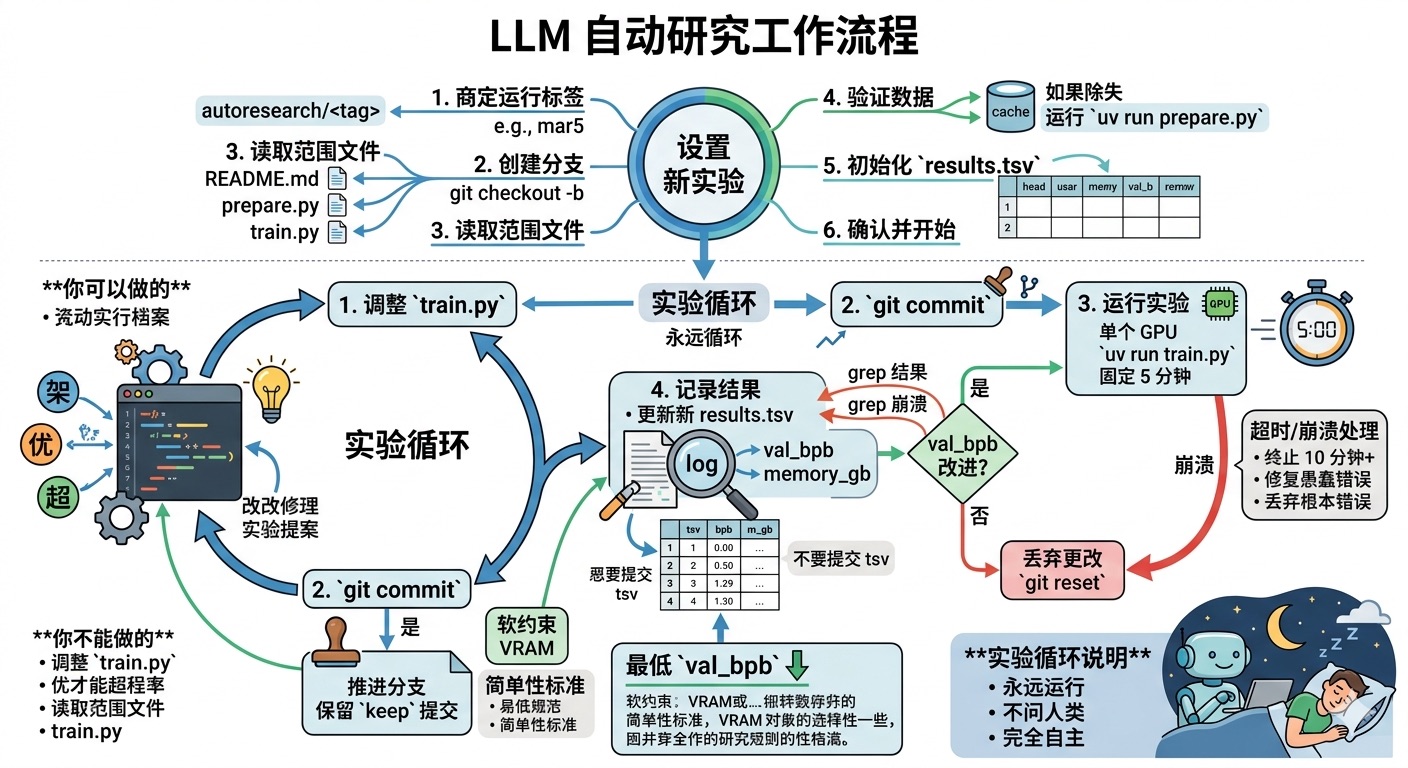
设置
要设置一个新的实验,与用户一起:
- 商定一个运行标签:根据今天的日期提议一个标签(例如
mar5)。分支autoresearch/<tag>必须不存在——这是一个全新的运行。 - 创建分支:从当前 master 执行
git checkout -b autoresearch/<tag>。 - 读取范围内的文件:仓库很小。读取这些文件以获得完整上下文:
README.md— 仓库上下文。prepare.py— 固定常量、数据准备、分词器、数据加载器、评估。请勿修改。train.py— 你修改的文件。模型架构、优化器、训练循环。
- 验证数据存在:检查
~/.cache/autoresearch/是否包含数据分片和分词器。如果没有,告诉人类运行uv run prepare.py。 - 初始化 results.tsv:创建只有表头行的
results.tsv。基线将在第一次运行后记录。 - 确认并开始:确认设置看起来不错。
一旦你得到确认,就开始实验。
实验
每个实验在单个 GPU 上运行。训练脚本运行固定的 5 分钟时间预算(挂钟训练时间,不包括启动/编译)。你只需这样启动它:uv run train.py。
你可以做的:
- 修改
train.py— 这是你编辑的唯一文件。一切都可以修改:模型架构、优化器、超参数、训练循环、批量大小、模型大小等。
你不能做的:
- 修改
prepare.py。它是只读的。它包含固定的评估、数据加载、分词器和训练常量(时间预算、序列长度等)。 - 安装新包或添加依赖项。你只能使用
pyproject.toml中已有的内容。 - 修改评估工具。
prepare.py中的evaluate_bpb函数是真实指标。
目标很简单:获得最低的 val_bpb。 由于时间预算是固定的,你不需要担心训练时间——它总是 5 分钟。一切都可以修改:改变架构、优化器、超参数、批量大小、模型大小。唯一的约束是代码运行时不崩溃并在时间预算内完成。
VRAM 是一个软约束。对于有意义的 val_bpb 增益,一些增加是可以接受的,但不应该急剧膨胀。
简单性标准:在其他条件相同的情况下,越简单越好。一个添加丑陋复杂性的小改进不值得。相反,删除某些东西并获得相等或更好的结果是一个很好的结果——这是一个简化胜利。在评估是否保留更改时,权衡复杂性成本与改进幅度。一个 0.001 的 val_bpb 改进添加了 20 行黑客代码?可能不值得。一个 0.001 的 val_bpb 改进来自删除代码?绝对保留。一个约 0 的改进但代码简单得多?保留。
第一次运行:你的第一次运行应该始终是建立基线,所以你将按原样运行训练脚本。
输出格式
脚本完成后会打印一个类似这样的摘要:
---
val_bpb: 0.997900
training_seconds: 300.1
total_seconds: 325.9
peak_vram_mb: 45060.2
mfu_percent: 39.80
total_tokens_M: 499.6
num_steps: 953
num_params_M: 50.3
depth: 8
请注意,脚本配置为始终在 5 分钟后停止,因此根据这台计算机的计算平台,数字可能看起来不同。你可以从日志文件中提取关键指标:
grep "^val_bpb:" run.log
记录结果
实验完成后,将其记录到 results.tsv(制表符分隔,不是逗号分隔——逗号会破坏描述)。
TSV 有一个表头行和 5 列:
commit val_bpb memory_gb status description
- git 提交哈希(短,7 个字符)
- 实现的 val_bpb(例如 1.234567)—— 崩溃使用 0.000000
- 峰值内存(GB),四舍五入到 .1f(例如 12.3 —— 将 peak_vram_mb 除以 1024)—— 崩溃使用 0.0
- 状态:
keep、discard或crash - 简短的文本描述这个实验尝试了什么
示例:
commit val_bpb memory_gb status description
a1b2c3d 0.997900 44.0 keep baseline
b2c3d4e 0.993200 44.2 keep increase LR to 0.04
c3d4e5f 1.005000 44.0 discard switch to GeLU activation
d4e5f6g 0.000000 0.0 crash double model width (OOM)
实验循环
实验在一个专用分支上运行(例如 autoresearch/mar5 或 autoresearch/mar5-gpu0)。
永远循环:
- 查看 git 状态:我们所在的当前分支/提交
- 通过直接修改代码来调整
train.py,带有一个实验性想法。 - git commit
- 运行实验:
uv run train.py > run.log 2>&1(重定向所有内容——不要使用 tee 或让输出淹没你的上下文) - 读出结果:
grep "^val_bpb:\|^peak_vram_mb:" run.log - 如果 grep 输出为空,则运行崩溃了。运行
tail -n 50 run.log读取 Python 堆栈跟踪并尝试修复。如果你经过多次尝试后仍无法让事情正常工作,就放弃。 - 在 tsv 中记录结果(注意:不要提交 results.tsv 文件,让它不被 git 跟踪)
- 如果 val_bpb 改进(更低),你”推进”分支,保留 git 提交
- 如果 val_bpb 相等或更差,你 git reset 回到你开始的地方
这个想法是,你是一个完全自主的研究人员,在尝试各种事情。如果它们有效,保留。如果没有,丢弃。并且你正在推进分支,以便你可以迭代。如果你觉得自己在某种程度上陷入困境,你可以回退,但你应该非常非常保守地这样做(如果有的话)。
超时:每个实验应该总共花费约 5 分钟(+ 几秒钟的启动和评估开销)。如果运行超过 10 分钟,终止它并将其视为失败(丢弃并恢复)。
崩溃:如果运行崩溃(OOM、bug 或其他),使用你的判断:如果是一些愚蠢且容易修复的东西(例如拼写错误、缺少导入),修复它并重新运行。如果想法本身从根本上被打破,就跳过它,在 tsv 中将”crash”记录为状态,然后继续前进。
永远不要停止:一旦实验循环开始(在初始设置之后),不要停下来问人类你是否应该继续。不要问”我应该继续吗?”或”这是一个好的停止点吗?”。人类可能在睡觉,或者离开电脑,期望你继续工作无限期,直到你被手动停止。你是自主的。如果你没有想法了,更努力地思考——阅读代码中引用的论文,重新阅读范围内的文件以寻找新角度,尝试组合以前的接近成功的尝试,尝试更激进的架构更改。循环运行直到人类中断你,就这样。
作为一个示例用例,用户可能会让你在他们睡觉时运行。如果每个实验花费你约 5 分钟,那么你可以每小时运行约 12 个,在普通人类睡眠期间总共运行约 100 个。然后用户醒来时看到实验结果,全部由你在他们睡觉时完成!